 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
PaLI-X: On Scaling up a Multilingual Vision and Language Model
May 29, 2023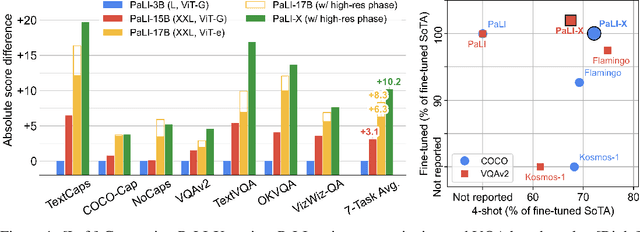
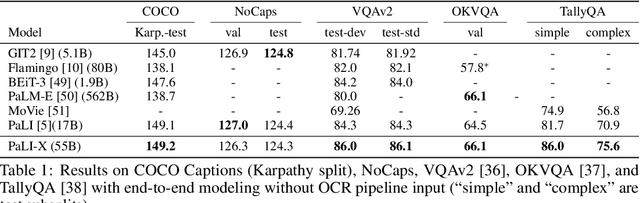
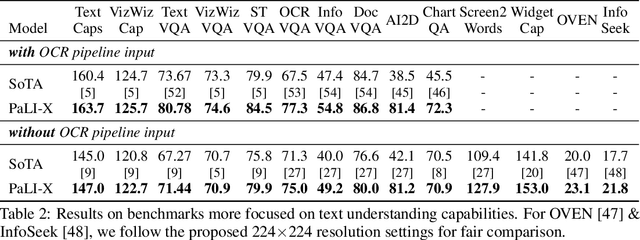

We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
What You See is What You Read? Improving Text-Image Alignment Evaluation
May 22, 2023Automatically determining whether a text and a corresponding image are semantically aligned is a significant challenge for vision-language models, with applications in generative text-to-image and image-to-text tasks. In this work, we study methods for automatic text-image alignment evaluation. We first introduce SeeTRUE: a comprehensive evaluation set, spanning multiple datasets from both text-to-image and image-to-text generation tasks, with human judgements for whether a given text-image pair is semantically aligned. We then describe two automatic methods to determine alignment: the first involving a pipeline based on question generation and visual question answering models, and the second employing an end-to-end classification approach by finetuning multimodal pretrained models. Both methods surpass prior approaches in various text-image alignment tasks, with significant improvements in challenging cases that involve complex composition or unnatural images. Finally, we demonstrate how our approaches can localize specific misalignments between an image and a given text, and how they can be used to automatically re-rank candidates in text-to-image generation.
Connecting Vision and Language with Video Localized Narratives
Mar 15, 2023
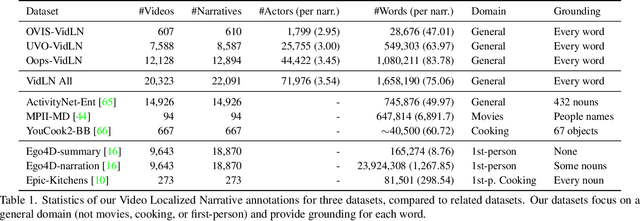


We propose Video Localized Narratives, a new form of multimodal video annotations connecting vision and language. In the original Localized Narratives, annotators speak and move their mouse simultaneously on an image, thus grounding each word with a mouse trace segment. However, this is challenging on a video. Our new protocol empowers annotators to tell the story of a video with Localized Narratives, capturing even complex events involving multiple actors interacting with each other and with several passive objects. We annotated 20k videos of the OVIS, UVO, and Oops datasets, totalling 1.7M words. Based on this data, we also construct new benchmarks for the video narrative grounding and video question answering tasks, and provide reference results from strong baseline models. Our annotations are available at https://google.github.io/video-localized-narratives/.
Can Pre-trained Vision and Language Models Answer Visual Information-Seeking Questions?
Feb 24, 2023

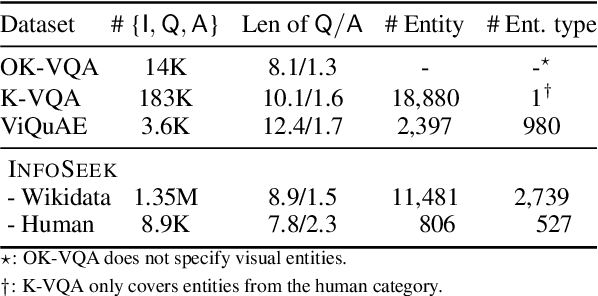

Large language models have demonstrated an emergent capability in answering knowledge intensive questions. With recent progress on web-scale visual and language pre-training, do these models also understand how to answer visual information seeking questions? To answer this question, we present InfoSeek, a Visual Question Answering dataset that focuses on asking information-seeking questions, where the information can not be answered by common sense knowledge. We perform a multi-stage human annotation to collect a natural distribution of high-quality visual information seeking question-answer pairs. We also construct a large-scale, automatically collected dataset by combining existing visual entity recognition datasets and Wikidata, which provides over one million examples for model fine-tuning and validation. Based on InfoSeek, we analyzed various pre-trained Visual QA systems to gain insights into the characteristics of different pre-trained models. Our analysis shows that it is challenging for the state-of-the-art multi-modal pre-trained models to answer visual information seeking questions, but this capability is improved through fine-tuning on the automated InfoSeek dataset. We hope our analysis paves the way to understand and develop the next generation of multi-modal pre-training.
MetaCLUE: Towards Comprehensive Visual Metaphors Research
Dec 19, 2022



Creativity is an indispensable part of human cognition and also an inherent part of how we make sense of the world. Metaphorical abstraction is fundamental in communicating creative ideas through nuanced relationships between abstract concepts such as feelings. While computer vision benchmarks and approaches predominantly focus on understanding and generating literal interpretations of images, metaphorical comprehension of images remains relatively unexplored. Towards this goal, we introduce MetaCLUE, a set of vision tasks on visual metaphor. We also collect high-quality and rich metaphor annotations (abstract objects, concepts, relationships along with their corresponding object boxes) as there do not exist any datasets that facilitate the evaluation of these tasks. We perform a comprehensive analysis of state-of-the-art models in vision and language based on our annotations, highlighting strengths and weaknesses of current approaches in visual metaphor Classification, Localization, Understanding (retrieval, question answering, captioning) and gEneration (text-to-image synthesis) tasks. We hope this work provides a concrete step towards developing AI systems with human-like creative capabilities.
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022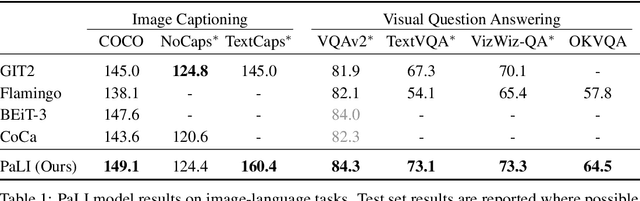

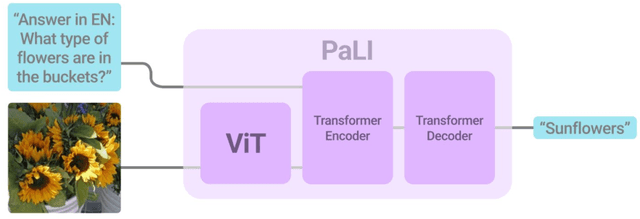

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
PreSTU: Pre-Training for Scene-Text Understanding
Sep 12, 2022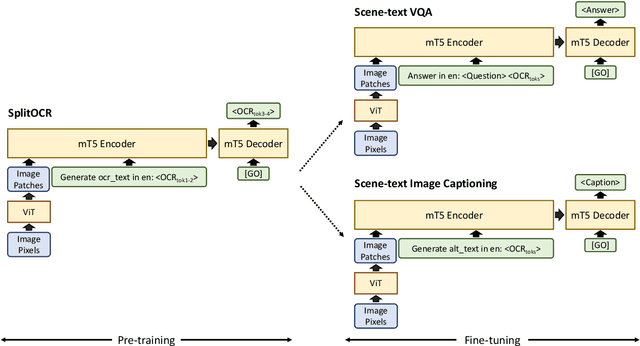
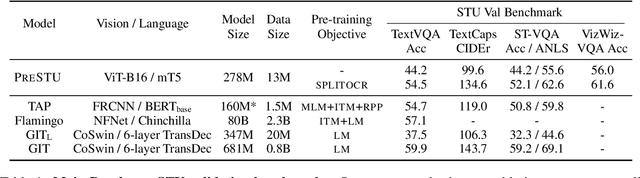
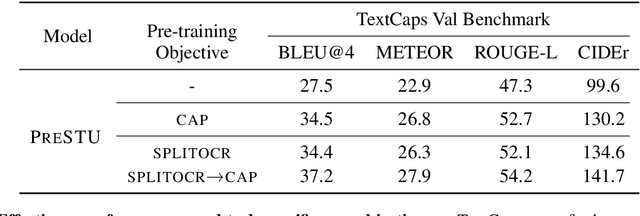
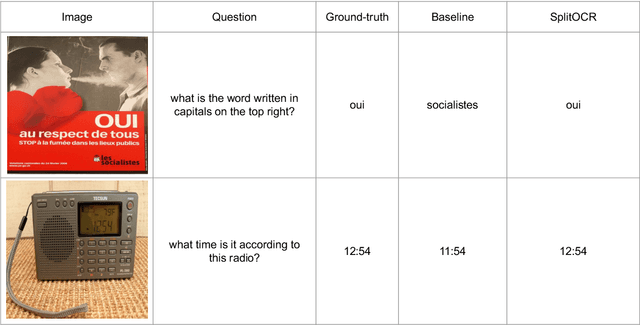
The ability to read and reason about texts in an image is often lacking in vision-and-language (V&L) models. How can we learn V&L models that exhibit strong scene-text understanding (STU)? In this paper, we propose PreSTU, a simple pre-training recipe specifically designed for scene-text understanding. PreSTU combines a simple OCR-aware pre-training objective with a large-scale image-text dataset with off-the-shelf OCR signals. We empirically demonstrate the superiority of this pre-training objective on TextVQA, TextCaps, ST-VQA, and VizWiz-VQA. We also study which factors affect STU performance, where we highlight the importance of image resolution and dataset scale during pre-training.
Towards Multi-Lingual Visual Question Answering
Sep 12, 2022

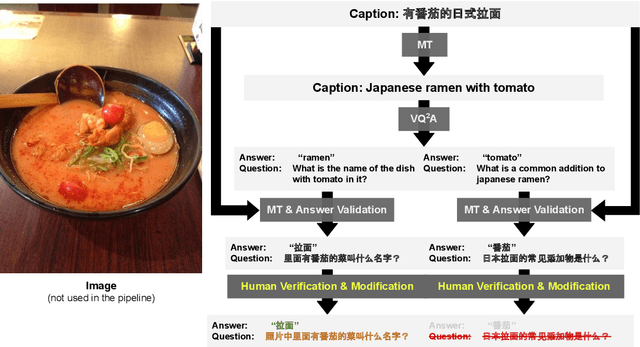

Visual Question Answering (VQA) has been primarily studied through the lens of the English language. Yet, tackling VQA in other languages in the same manner would require considerable amount of resources. In this paper, we propose scalable solutions to multi-lingual visual question answering (mVQA), on both data and modeling fronts. We first propose a translation-based framework to mVQA data generation that requires much less human annotation efforts than the conventional approach of directly collection questions and answers. Then, we apply our framework to the multi-lingual captions in the Crossmodal-3600 dataset and develop an efficient annotation protocol to create MAVERICS-XM3600 (MaXM), a test-only VQA benchmark in 7 diverse languages. Finally, we propose an approach to unified, extensible, open-ended, and end-to-end mVQA modeling and demonstrate strong performance in 13 languages.
All You May Need for VQA are Image Captions
May 04, 2022
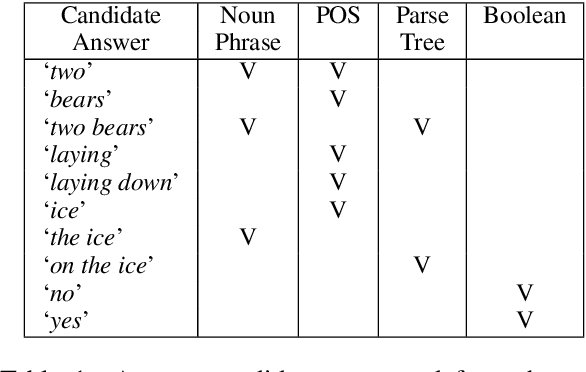
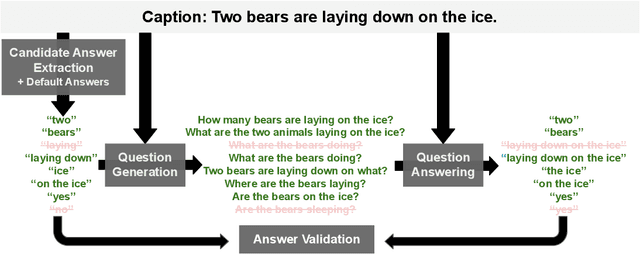
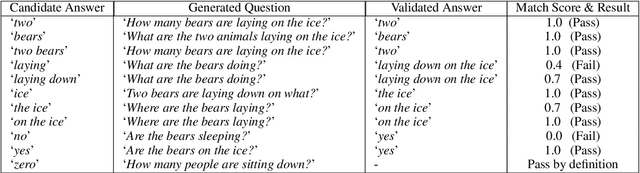
Visual Question Answering (VQA) has benefited from increasingly sophisticated models, but has not enjoyed the same level of engagement in terms of data creation. In this paper, we propose a method that automatically derives VQA examples at volume, by leveraging the abundance of existing image-caption annotations combined with neural models for textual question generation. We show that the resulting data is of high-quality. VQA models trained on our data improve state-of-the-art zero-shot accuracy by double digits and achieve a level of robustness that lacks in the same model trained on human-annotated VQA data.