 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-Squeeze: Simple and Effective Post-Tuning and In-Tuning Compression of LoRA Modules
Feb 11, 2026Despite its huge number of variants, standard Low-Rank Adaptation (LoRA) is still a dominant technique for parameter-efficient fine-tuning (PEFT). Nonetheless, it faces persistent challenges, including the pre-selection of an optimal rank and rank-specific hyper-parameters, as well as the deployment complexity of heterogeneous-rank modules and more sophisticated LoRA derivatives. In this work, we introduce LoRA-Squeeze, a simple and efficient methodology that aims to improve standard LoRA learning by changing LoRA module ranks either post-hoc or dynamically during training}. Our approach posits that it is better to first learn an expressive, higher-rank solution and then compress it, rather than learning a constrained, low-rank solution directly. The method involves fine-tuning with a deliberately high(er) source rank, reconstructing or efficiently approximating the reconstruction of the full weight update matrix, and then using Randomized Singular Value Decomposition (RSVD) to create a new, compressed LoRA module at a lower target rank. Extensive experiments across 13 text and 10 vision-language tasks show that post-hoc compression often produces lower-rank adapters that outperform those trained directly at the target rank, especially if a small number of fine-tuning steps at the target rank is allowed. Moreover, a gradual, in-tuning rank annealing variant of LoRA-Squeeze consistently achieves the best LoRA size-performance trade-off.
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022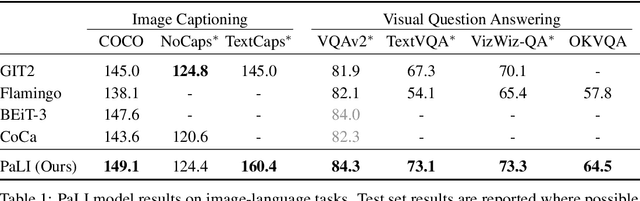

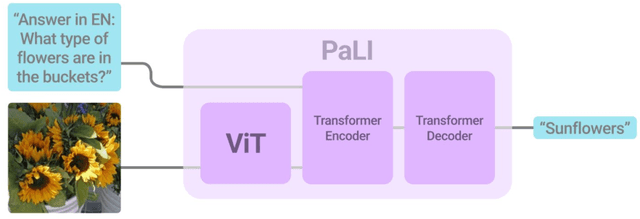

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.