 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Scaling State-Space Models for Dense Video Captioning
Sep 03, 2025Dense video captioning is a challenging video understanding task which aims to simultaneously segment the video into a sequence of meaningful consecutive events and to generate detailed captions to accurately describe each event. Existing methods often encounter difficulties when working with the long videos associated with dense video captioning, due to the computational complexity and memory limitations. Furthermore, traditional approaches require the entire video as input, in order to produce an answer, which precludes online processing of the video. We address these challenges by time-scaling State-Space Models (SSMs) to even longer sequences than before. Our approach, State-Space Models with Transfer State, combines both the long-sequence and recurrent properties of SSMs and addresses the main limitation of SSMs which are otherwise not able to sustain their state for very long contexts, effectively scaling SSMs further in time. The proposed model is particularly suitable for generating captions on-the-fly, in an online or streaming manner, without having to wait for the full video to be processed, which is more beneficial in practice. When applied to dense video captioning, our approach scales well with video lengths and uses 7x fewer FLOPs.
VideoComp: Advancing Fine-Grained Compositional and Temporal Alignment in Video-Text Models
Apr 10, 2025



We introduce VideoComp, a benchmark and learning framework for advancing video-text compositionality understanding, aimed at improving vision-language models (VLMs) in fine-grained temporal alignment. Unlike existing benchmarks focused on static image-text compositionality or isolated single-event videos, our benchmark targets alignment in continuous multi-event videos. Leveraging video-text datasets with temporally localized event captions (e.g. ActivityNet-Captions, YouCook2), we construct two compositional benchmarks, ActivityNet-Comp and YouCook2-Comp. We create challenging negative samples with subtle temporal disruptions such as reordering, action word replacement, partial captioning, and combined disruptions. These benchmarks comprehensively test models' compositional sensitivity across extended, cohesive video-text sequences. To improve model performance, we propose a hierarchical pairwise preference loss that strengthens alignment with temporally accurate pairs and gradually penalizes increasingly disrupted ones, encouraging fine-grained compositional learning. To mitigate the limited availability of densely annotated video data, we introduce a pretraining strategy that concatenates short video-caption pairs to simulate multi-event sequences. We evaluate video-text foundational models and large multimodal models (LMMs) on our benchmark, identifying both strengths and areas for improvement in compositionality. Overall, our work provides a comprehensive framework for evaluating and enhancing model capabilities in achieving fine-grained, temporally coherent video-text alignment.
Whats in a Video: Factorized Autoregressive Decoding for Online Dense Video Captioning
Nov 22, 2024



Generating automatic dense captions for videos that accurately describe their contents remains a challenging area of research. Most current models require processing the entire video at once. Instead, we propose an efficient, online approach which outputs frequent, detailed and temporally aligned captions, without access to future frames. Our model uses a novel autoregressive factorized decoding architecture, which models the sequence of visual features for each time segment, outputting localized descriptions and efficiently leverages the context from the previous video segments. This allows the model to output frequent, detailed captions to more comprehensively describe the video, according to its actual local content, rather than mimic the training data. Second, we propose an optimization for efficient training and inference, which enables scaling to longer videos. Our approach shows excellent performance compared to both offline and online methods, and uses 20\% less compute. The annotations produced are much more comprehensive and frequent, and can further be utilized in automatic video tagging and in large-scale video data harvesting.
Mirasol3B: A Multimodal Autoregressive model for time-aligned and contextual modalities
Nov 13, 2023



One of the main challenges of multimodal learning is the need to combine heterogeneous modalities (e.g., video, audio, text). For example, video and audio are obtained at much higher rates than text and are roughly aligned in time. They are often not synchronized with text, which comes as a global context, e.g., a title, or a description. Furthermore, video and audio inputs are of much larger volumes, and grow as the video length increases, which naturally requires more compute dedicated to these modalities and makes modeling of long-range dependencies harder. We here decouple the multimodal modeling, dividing it into separate, focused autoregressive models, processing the inputs according to the characteristics of the modalities. We propose a multimodal model, called Mirasol3B, consisting of an autoregressive component for the time-synchronized modalities (audio and video), and an autoregressive component for the context modalities which are not necessarily aligned in time but are still sequential. To address the long-sequences of the video-audio inputs, we propose to further partition the video and audio sequences in consecutive snippets and autoregressively process their representations. To that end, we propose a Combiner mechanism, which models the audio-video information jointly within a timeframe. The Combiner learns to extract audio and video features from raw spatio-temporal signals, and then learns to fuse these features producing compact but expressive representations per snippet. Our approach achieves the state-of-the-art on well established multimodal benchmarks, outperforming much larger models. It effectively addresses the high computational demand of media inputs by both learning compact representations, controlling the sequence length of the audio-video feature representations, and modeling their dependencies in time.
Diversifying Joint Vision-Language Tokenization Learning
Jun 15, 2023Building joint representations across images and text is an essential step for tasks such as Visual Question Answering and Video Question Answering. In this work, we find that the representations must not only jointly capture features from both modalities but should also be diverse for better generalization performance. To this end, we propose joint vision-language representation learning by diversifying the tokenization learning process, enabling tokens that are sufficiently disentangled from each other to be learned from both modalities. We observe that our approach outperforms the baseline models in a majority of settings and is competitive with state-of-the-art methods.
Joint Adaptive Representations for Image-Language Learning
Jun 01, 2023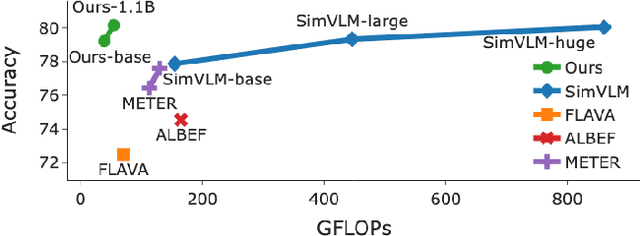
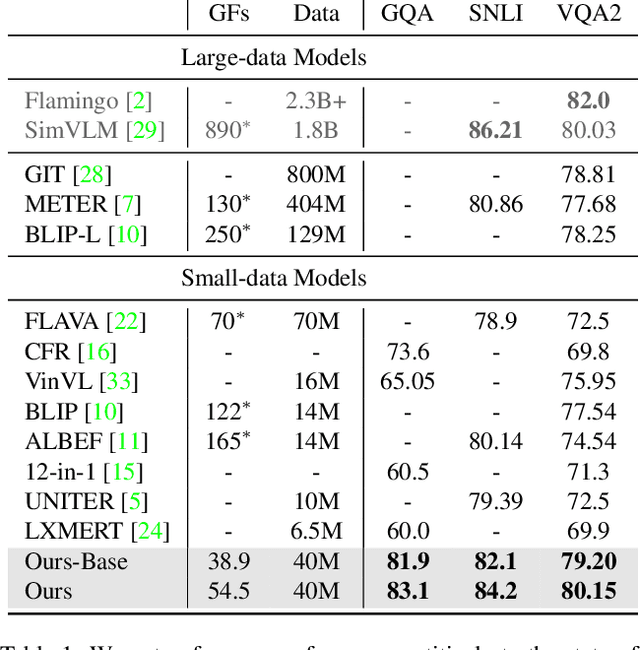
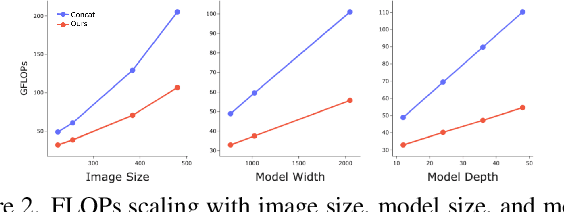

Image-language learning has made unprecedented progress in visual understanding. These developments have come at high costs, as contemporary vision-language models require large model scales and amounts of data. We here propose a much easier recipe for image-language learning, which produces effective models, outperforming bigger and more expensive ones, often trained on orders of magnitude larger datasets. Our key finding is the joint learning of a compact vision and language representation, which adaptively and iteratively fuses the multi-modal features. This results in a more effective image-language learning, greatly lowering the FLOPs by combining and reducing the number of tokens for both text and images, e.g. a 33\% reduction in FLOPs is achieved, compared to baseline fusion techniques used by popular image-language models, while improving performance. This also allows the model to scale without a large increase in FLOPs or memory. In addition, we propose adaptive pre-training data sampling which improves the data efficiency. The proposed approach achieves competitive performance compared to much larger models, and does so with significantly less data and FLOPs. With only 40M training examples and with 39 GFLOPs our lightweight model outperforms many times larger state-of-the-art models of 2-20x more FLOPs and using bigger datasets some of which with close to 1B training examples.
PaLI-X: On Scaling up a Multilingual Vision and Language Model
May 29, 2023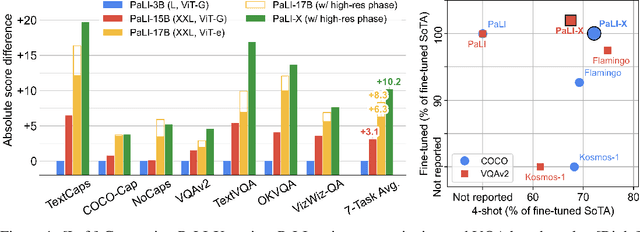
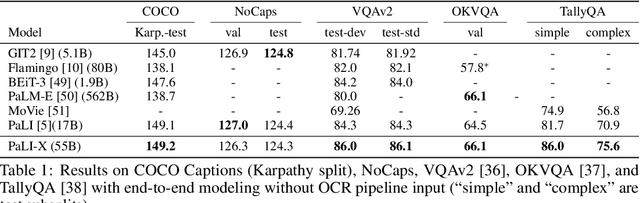
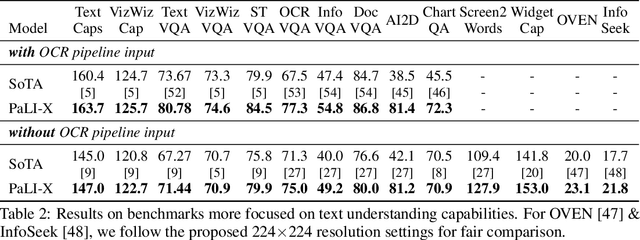

We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks
Mar 30, 2023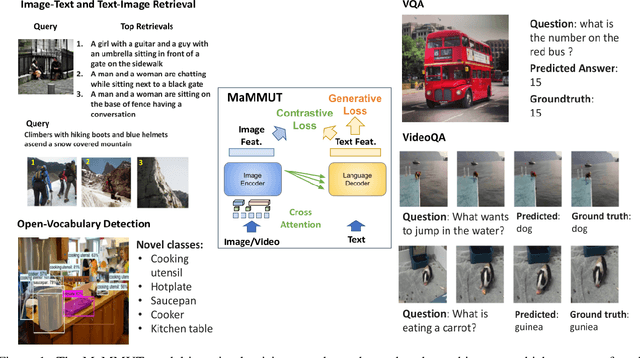
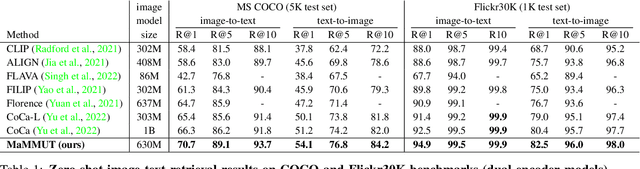
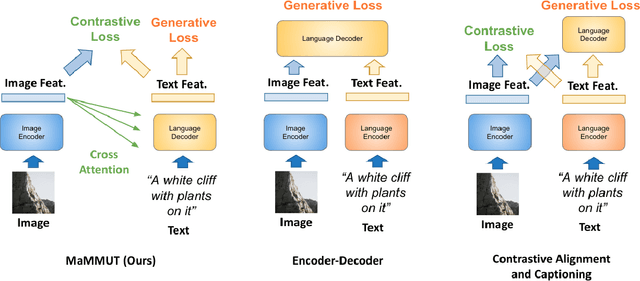
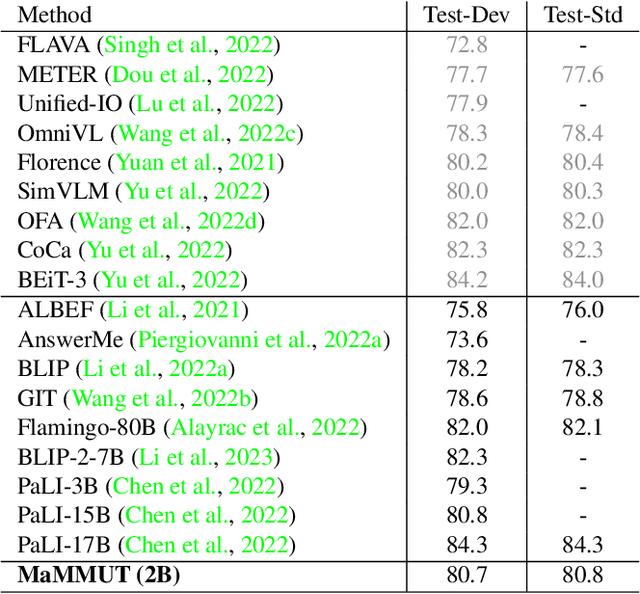
The development of language models have moved from encoder-decoder to decoder-only designs. In addition, the common knowledge has it that the two most popular multimodal tasks, the generative and contrastive tasks, tend to conflict with one another, are hard to accommodate in one architecture, and further need complex adaptations for downstream tasks. We propose a novel paradigm of training with a decoder-only model for multimodal tasks, which is surprisingly effective in jointly learning of these disparate vision-language tasks. This is done with a simple model, called MaMMUT. It consists of a single vision encoder and a text decoder, and is able to accommodate contrastive and generative learning by a novel two-pass approach on the text decoder. We demonstrate that joint learning of these diverse objectives is simple, effective, and maximizes the weight-sharing of the model across these tasks. Furthermore, the same architecture enables straightforward extensions to open-vocabulary object detection and video-language tasks. The model tackles a diverse range of tasks, while being modest in capacity. Our model achieves the state of the art on image-text and text-image retrieval, video question answering and open-vocabulary detection tasks, outperforming much larger and more extensively trained foundational models. It shows very competitive results on VQA and Video Captioning, especially considering its capacity. Ablations confirm the flexibility and advantages of our approach.
Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning
Dec 06, 2022We present a simple approach which can turn a ViT encoder into an efficient video model, which can seamlessly work with both image and video inputs. By sparsely sampling the inputs, the model is able to do training and inference from both inputs. The model is easily scalable and can be adapted to large-scale pre-trained ViTs without requiring full finetuning. The model achieves SOTA results and the code will be open-sourced.
Compound Tokens: Channel Fusion for Vision-Language Representation Learning
Dec 02, 2022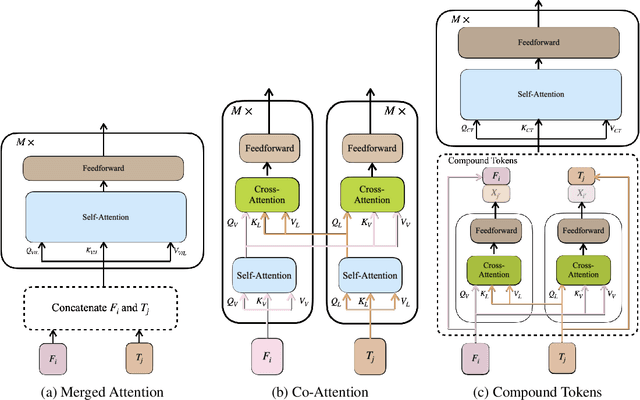



We present an effective method for fusing visual-and-language representations for several question answering tasks including visual question answering and visual entailment. In contrast to prior works that concatenate unimodal representations or use only cross-attention, we compose multimodal representations via channel fusion. By fusing on the channels, the model is able to more effectively align the tokens compared to standard methods. These multimodal representations, which we call compound tokens are generated with cross-attention transformer layers. First, vision tokens are used as queries to retrieve compatible text tokens through cross-attention. We then chain the vision tokens and the queried text tokens along the channel dimension. We call the resulting representations compound tokens. A second group of compound tokens are generated using an analogous process where the text tokens serve as queries to the cross-attention layer. We concatenate all the compound tokens for further processing with multimodal encoder. We demonstrate the effectiveness of compound tokens using an encoder-decoder vision-language model trained end-to-end in the open-vocabulary setting. Compound Tokens achieve highly competitive performance across a range of question answering tasks including GQA, VQA2.0, and SNLI-VE.