 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks
Mar 30, 2023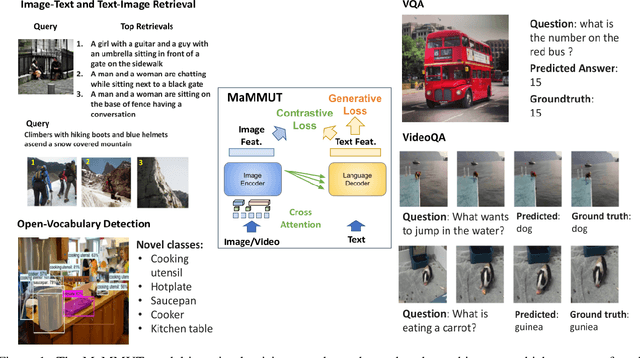
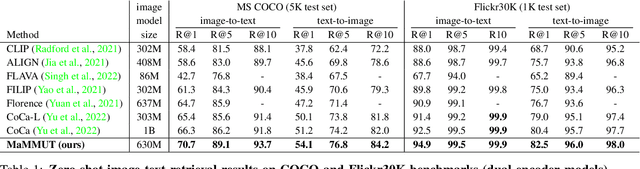
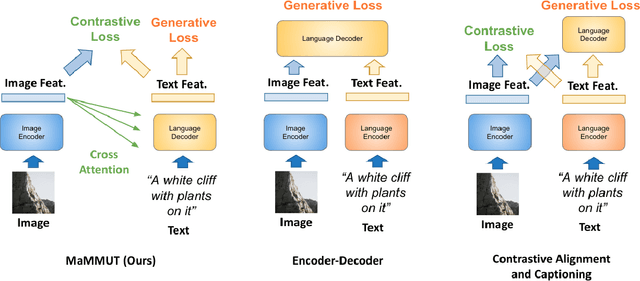
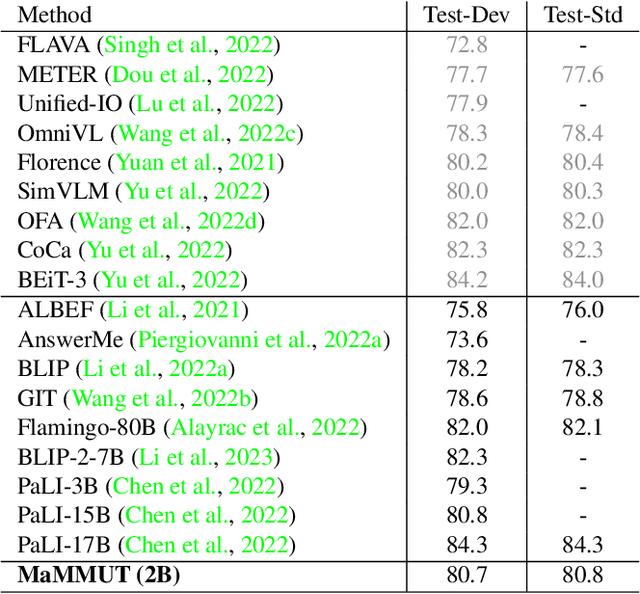
The development of language models have moved from encoder-decoder to decoder-only designs. In addition, the common knowledge has it that the two most popular multimodal tasks, the generative and contrastive tasks, tend to conflict with one another, are hard to accommodate in one architecture, and further need complex adaptations for downstream tasks. We propose a novel paradigm of training with a decoder-only model for multimodal tasks, which is surprisingly effective in jointly learning of these disparate vision-language tasks. This is done with a simple model, called MaMMUT. It consists of a single vision encoder and a text decoder, and is able to accommodate contrastive and generative learning by a novel two-pass approach on the text decoder. We demonstrate that joint learning of these diverse objectives is simple, effective, and maximizes the weight-sharing of the model across these tasks. Furthermore, the same architecture enables straightforward extensions to open-vocabulary object detection and video-language tasks. The model tackles a diverse range of tasks, while being modest in capacity. Our model achieves the state of the art on image-text and text-image retrieval, video question answering and open-vocabulary detection tasks, outperforming much larger and more extensively trained foundational models. It shows very competitive results on VQA and Video Captioning, especially considering its capacity. Ablations confirm the flexibility and advantages of our approach.
Solving Image PDEs with a Shallow Network
Oct 15, 2021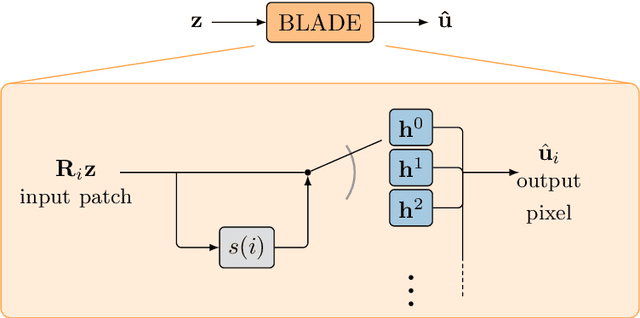
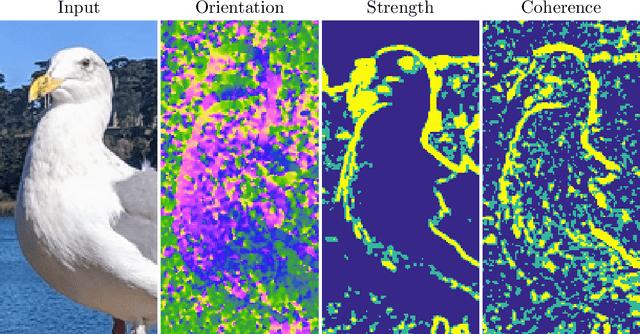
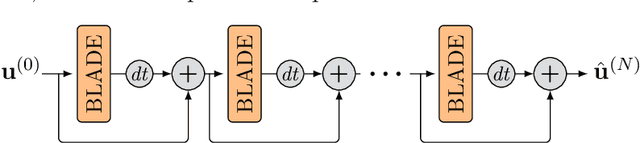
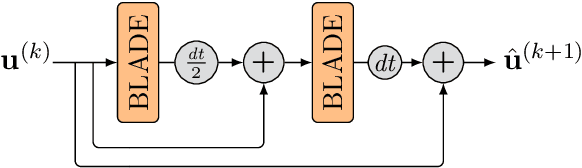
Partial differential equations (PDEs) are typically used as models of physical processes but are also of great interest in PDE-based image processing. However, when it comes to their use in imaging, conventional numerical methods for solving PDEs tend to require very fine grid resolution for stability, and as a result have impractically high computational cost. This work applies BLADE (Best Linear Adaptive Enhancement), a shallow learnable filtering framework, to PDE solving, and shows that the resulting approach is efficient and accurate, operating more reliably at coarse grid resolutions than classical methods. As such, the model can be flexibly used for a wide variety of problems in imaging.
Deep 3D-to-2D Watermarking: Embedding Messages in 3D Meshes and Extracting Them from 2D Renderings
Apr 29, 2021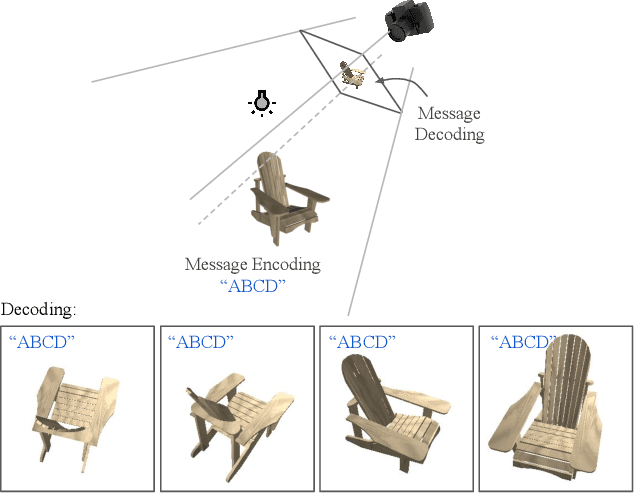

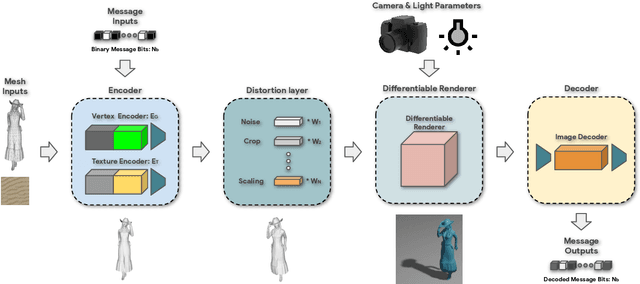

Digital watermarking is widely used for copyright protection. Traditional 3D watermarking approaches or commercial software are typically designed to embed messages into 3D meshes, and later retrieve the messages directly from distorted/undistorted watermarked 3D meshes. Retrieving messages from 2D renderings of such meshes, however, is still challenging and underexplored. We introduce a novel end-to-end learning framework to solve this problem through: 1) an encoder to covertly embed messages in both mesh geometry and textures; 2) a differentiable renderer to render watermarked 3D objects from different camera angles and under varied lighting conditions; 3) a decoder to recover the messages from 2D rendered images. From extensive experiments, we show that our models learn to embed information visually imperceptible to humans, and to reconstruct the embedded information from 2D renderings robust to 3D distortions. In addition, we demonstrate that our method can be generalized to work with different renderers, such as ray tracers and real-time renderers.
The Rate-Distortion-Accuracy Tradeoff: JPEG Case Study
Aug 03, 2020
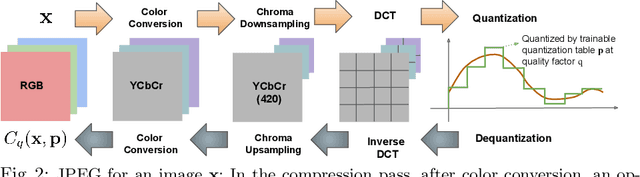
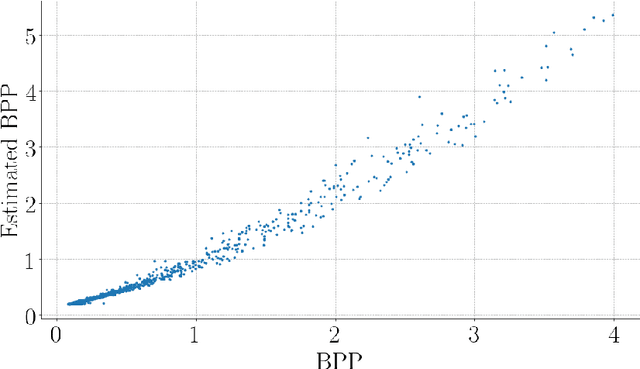

Handling digital images is almost always accompanied by a lossy compression in order to facilitate efficient transmission and storage. This introduces an unavoidable tension between the allocated bit-budget (rate) and the faithfulness of the resulting image to the original one (distortion). An additional complicating consideration is the effect of the compression on recognition performance by given classifiers (accuracy). This work aims to explore this rate-distortion-accuracy tradeoff. As a case study, we focus on the design of the quantization tables in the JPEG compression standard. We offer a novel optimal tuning of these tables via continuous optimization, leveraging a differential implementation of both the JPEG encoder-decoder and an entropy estimator. This enables us to offer a unified framework that considers the interplay between rate, distortion and classification accuracy. In all these fronts, we report a substantial boost in performance by a simple and easily implemented modification of these tables.
GIFnets: Differentiable GIF Encoding Framework
Jun 24, 2020
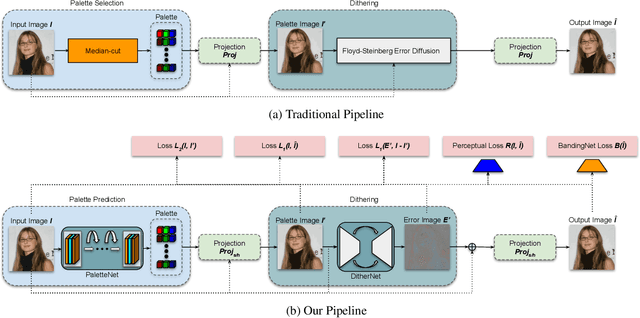
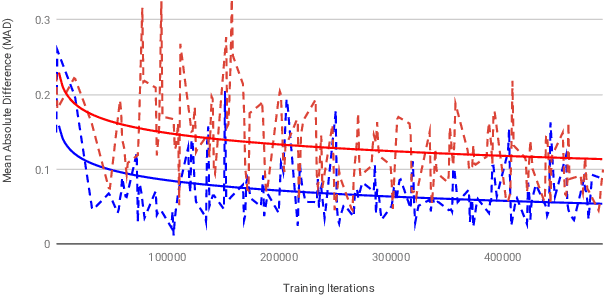

Graphics Interchange Format (GIF) is a widely used image file format. Due to the limited number of palette colors, GIF encoding often introduces color banding artifacts. Traditionally, dithering is applied to reduce color banding, but introducing dotted-pattern artifacts. To reduce artifacts and provide a better and more efficient GIF encoding, we introduce a differentiable GIF encoding pipeline, which includes three novel neural networks: PaletteNet, DitherNet, and BandingNet. Each of these three networks provides an important functionality within the GIF encoding pipeline. PaletteNet predicts a near-optimal color palette given an input image. DitherNet manipulates the input image to reduce color banding artifacts and provides an alternative to traditional dithering. Finally, BandingNet is designed to detect color banding, and provides a new perceptual loss specifically for GIF images. As far as we know, this is the first fully differentiable GIF encoding pipeline based on deep neural networks and compatible with existing GIF decoders. User study shows that our algorithm is better than Floyd-Steinberg based GIF encoding.
Better Compression with Deep Pre-Editing
Feb 01, 2020
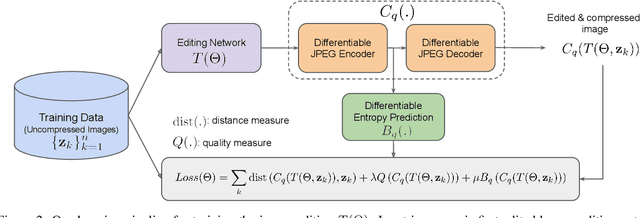
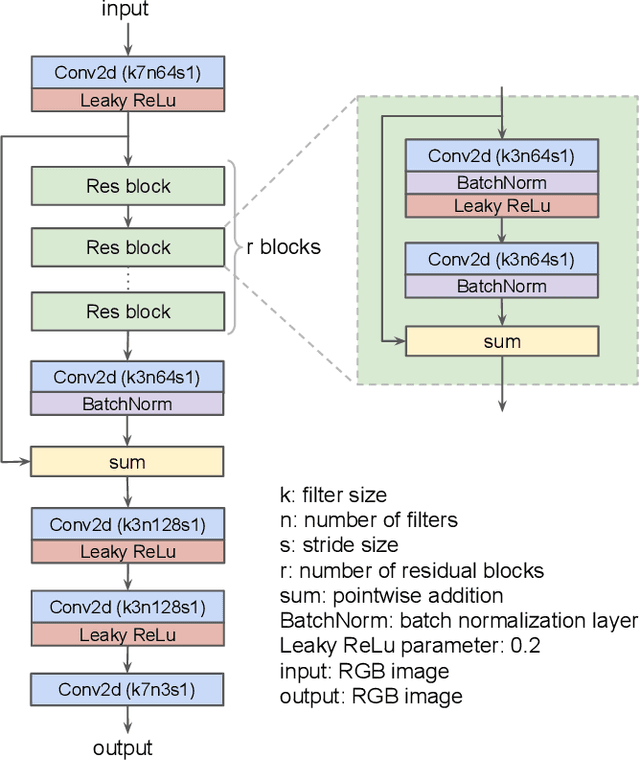
Could we compress images via standard codecs while avoiding artifacts? The answer is obvious -- this is doable as long as the bit budget is generous enough. What if the allocated bit-rate for compression is insufficient? Then unfortunately, artifacts are a fact of life. Many attempts were made over the years to fight this phenomenon, with various degrees of success. In this work we aim to break the unholy connection between bit-rate and image quality, and propose a way to circumvent compression artifacts by pre-editing the incoming image and modifying its content to fit the given bits. We design this editing operation as a learned convolutional neural network, and formulate an optimization problem for its training. Our loss takes into account a proximity between the original image and the edited one, a bit-budget penalty over the proposed image, and a no-reference image quality measure for forcing the outcome to be visually pleasing. The proposed approach is demonstrated on the popular JPEG compression, showing savings in bits and/or improvements in visual quality, obtained with intricate editing effects.
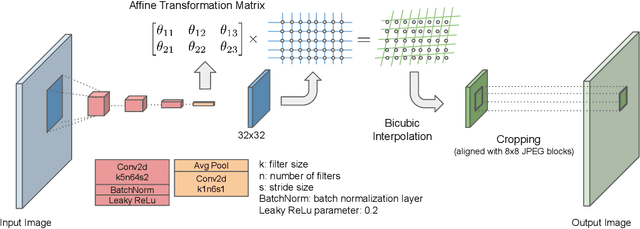
Distortion Agnostic Deep Watermarking
Jan 14, 2020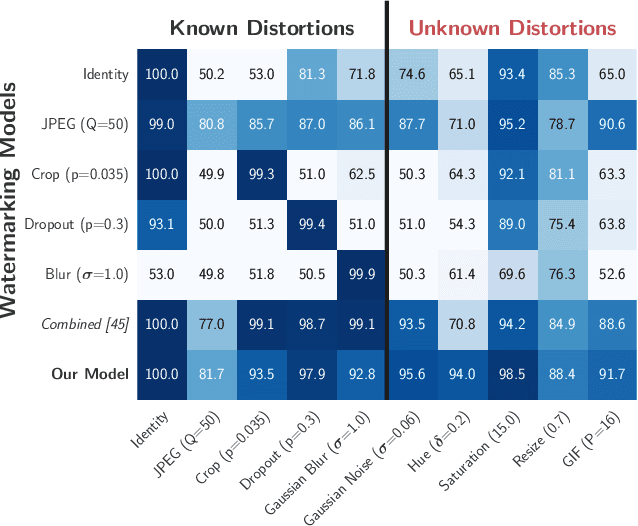


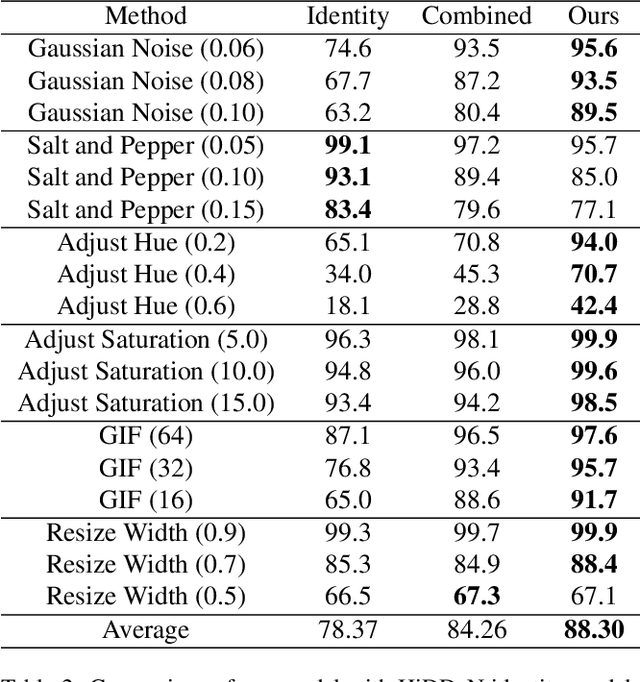
Watermarking is the process of embedding information into an image that can survive under distortions, while requiring the encoded image to have little or no perceptual difference from the original image. Recently, deep learning-based methods achieved impressive results in both visual quality and message payload under a wide variety of image distortions. However, these methods all require differentiable models for the image distortions at training time, and may generalize poorly to unknown distortions. This is undesirable since the types of distortions applied to watermarked images are usually unknown and non-differentiable. In this paper, we propose a new framework for distortion-agnostic watermarking, where the image distortion is not explicitly modeled during training. Instead, the robustness of our system comes from two sources: adversarial training and channel coding. Compared to training on a fixed set of distortions and noise levels, our method achieves comparable or better results on distortions available during training, and better performance on unknown distortions.
A Study on Graph-Structured Recurrent Neural Networks and Sparsification with Application to Epidemic Forecasting
Feb 13, 2019
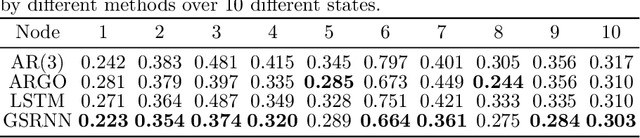


We study epidemic forecasting on real-world health data by a graph-structured recurrent neural network (GSRNN). We achieve state-of-the-art forecasting accuracy on the benchmark CDC dataset. To improve model efficiency, we sparsify the network weights via transformed-$\ell_1$ penalty and maintain prediction accuracy at the same level with 70% of the network weights being zero.
Laplacian Smoothing Gradient Descent
Oct 17, 2018
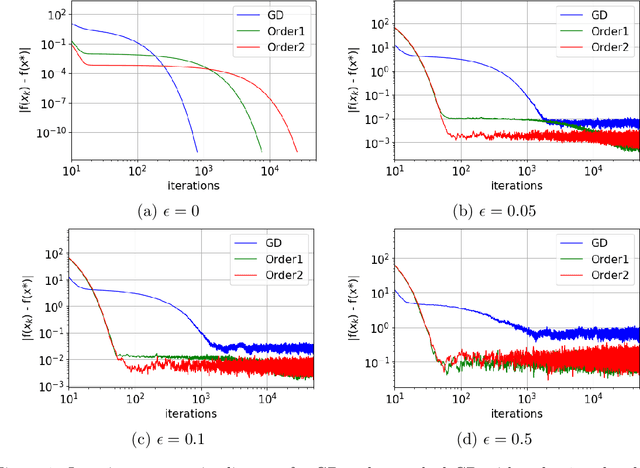

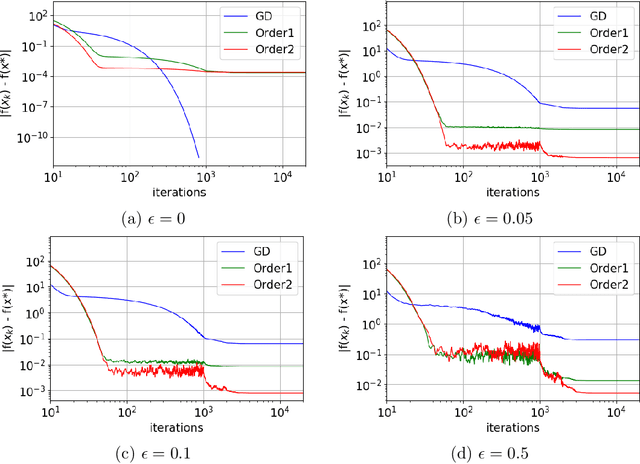
We propose a very simple modification of gradient descent and stochastic gradient descent. We show that when applied to a variety of machine learning models including softmax regression, convolutional neural nets, generative adversarial nets, and deep reinforcement learning, this very simple surrogate can dramatically reduce the variance and improve the accuracy of the generalization. The new algorithm, (which depends on one nonnegative parameter) when applied to non-convex minimization, tends to avoid sharp local minima. Instead it seeks somewhat flatter local (and often global) minima. The method only involves preconditioning the gradient by the inverse of a tri-diagonal matrix that is positive definite. The motivation comes from the theory of Hamilton-Jacobi partial differential equations. This theory demonstrates that the new algorithm is almost the same as doing gradient descent on a new function which (a) has the same global minima as the original function and (b) is "more convex". Again, the programming effort in doing this is minimal, in cost, complexity and effort. We implement our algorithm into both PyTorch and Tensorflow platforms, which will be made publicly available.
Seq2Slate: Re-ranking and Slate Optimization with RNNs
Oct 04, 2018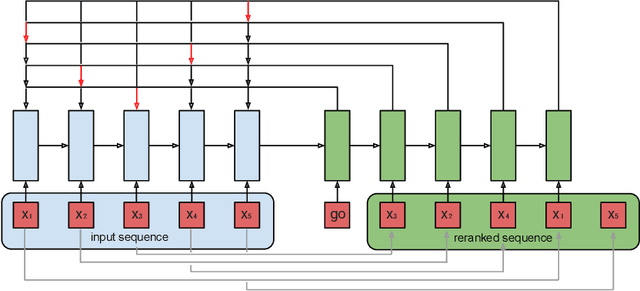
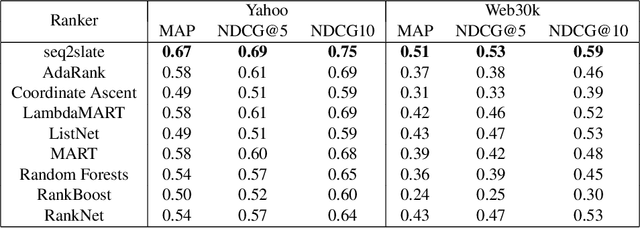

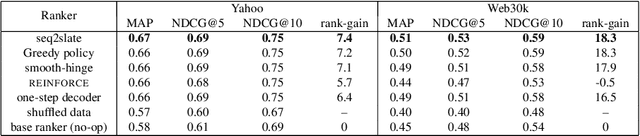
Ranking is a central task in machine learning and information retrieval. In this task, it is especially important to present the user with a slate of items that is appealing as a whole. This in turn requires taking into account interactions between items, since intuitively, placing an item on the slate affects the decision of which other items should be placed alongside it. In this work, we propose a sequence-to-sequence model for ranking called seq2slate. At each step, the model predicts the next item to place on the slate given the items already selected. The recurrent nature of the model allows complex dependencies between items to be captured directly in a flexible and scalable way. We show how to learn the model end-to-end from weak supervision in the form of easily obtained click-through data. We further demonstrate the usefulness of our approach in experiments on standard ranking benchmarks as well as in a real-world recommendation system.