 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeq2Slate: Re-ranking and Slate Optimization with RNNs
Oct 04, 2018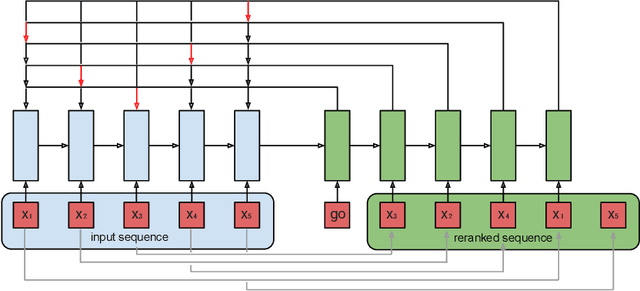
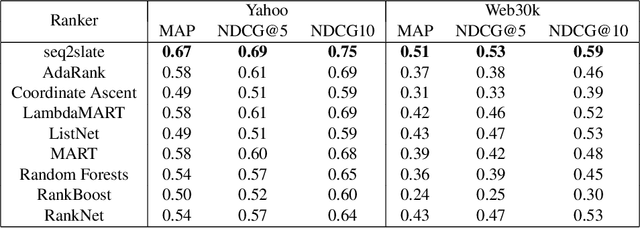

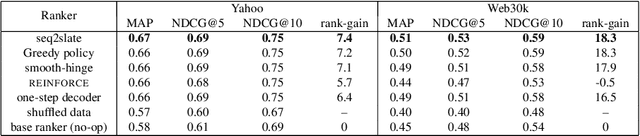
Ranking is a central task in machine learning and information retrieval. In this task, it is especially important to present the user with a slate of items that is appealing as a whole. This in turn requires taking into account interactions between items, since intuitively, placing an item on the slate affects the decision of which other items should be placed alongside it. In this work, we propose a sequence-to-sequence model for ranking called seq2slate. At each step, the model predicts the next item to place on the slate given the items already selected. The recurrent nature of the model allows complex dependencies between items to be captured directly in a flexible and scalable way. We show how to learn the model end-to-end from weak supervision in the form of easily obtained click-through data. We further demonstrate the usefulness of our approach in experiments on standard ranking benchmarks as well as in a real-world recommendation system.
Constrained Classification and Ranking via Quantiles
Feb 28, 2018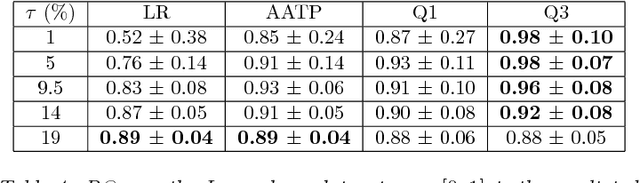
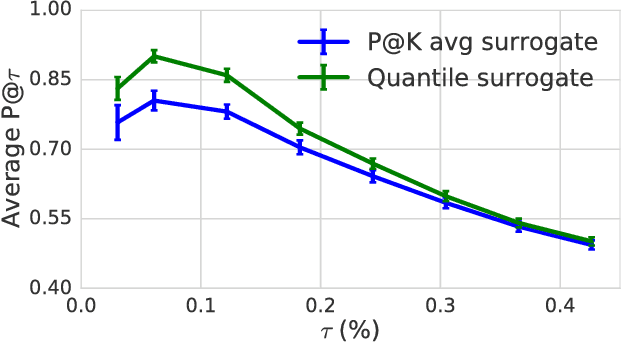
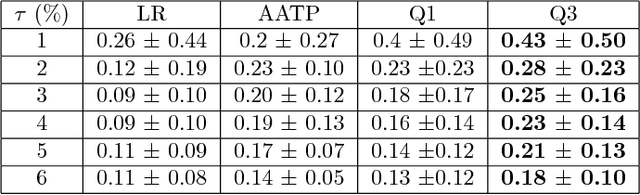
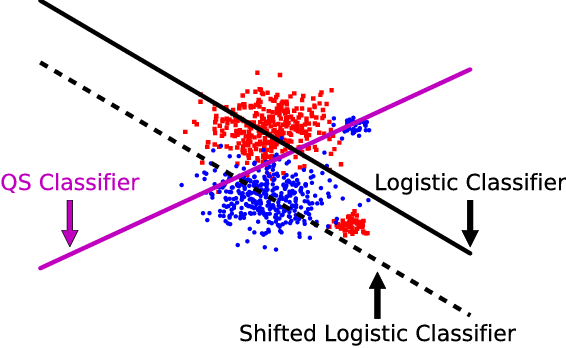
In most machine learning applications, classification accuracy is not the primary metric of interest. Binary classifiers which face class imbalance are often evaluated by the $F_\beta$ score, area under the precision-recall curve, Precision at K, and more. The maximization of many of these metrics can be expressed as a constrained optimization problem, where the constraint is a function of the classifier's predictions. In this paper we propose a novel framework for learning with constraints that can be expressed as a predicted positive rate (or negative rate) on a subset of the training data. We explicitly model the threshold at which a classifier must operate to satisfy the constraint, yielding a surrogate loss function which avoids the complexity of constrained optimization. The method is model-agnostic and only marginally more expensive than minimization of the unconstrained loss. Experiments on a variety of benchmarks show competitive performance relative to existing baselines.
Scalable Learning of Non-Decomposable Objectives
Mar 01, 2017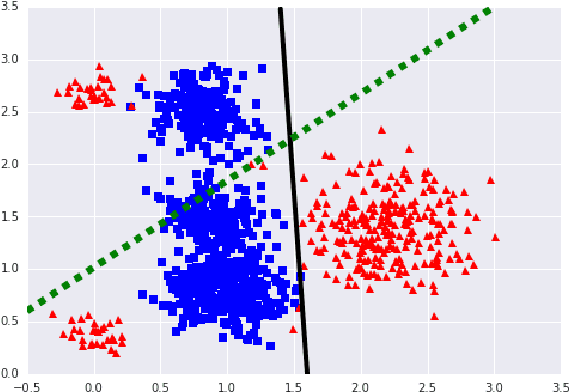
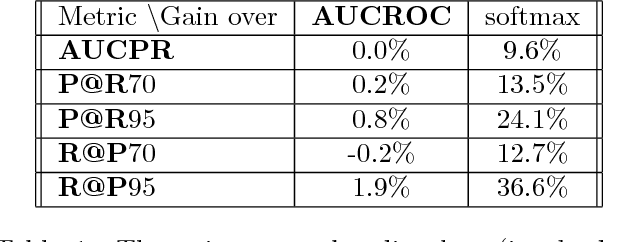
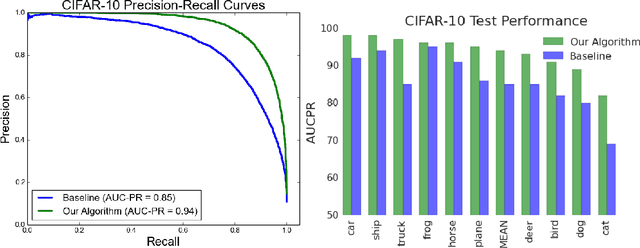
Modern retrieval systems are often driven by an underlying machine learning model. The goal of such systems is to identify and possibly rank the few most relevant items for a given query or context. Thus, such systems are typically evaluated using a ranking-based performance metric such as the area under the precision-recall curve, the $F_\beta$ score, precision at fixed recall, etc. Obviously, it is desirable to train such systems to optimize the metric of interest. In practice, due to the scalability limitations of existing approaches for optimizing such objectives, large-scale retrieval systems are instead trained to maximize classification accuracy, in the hope that performance as measured via the true objective will also be favorable. In this work we present a unified framework that, using straightforward building block bounds, allows for highly scalable optimization of a wide range of ranking-based objectives. We demonstrate the advantage of our approach on several real-life retrieval problems that are significantly larger than those considered in the literature, while achieving substantial improvement in performance over the accuracy-objective baseline.