 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedEx: Beyond Fixed Representation Methods via Convex Optimization
Jan 15, 2024Optimizing Neural networks is a difficult task which is still not well understood. On the other hand, fixed representation methods such as kernels and random features have provable optimization guarantees but inferior performance due to their inherent inability to learn the representations. In this paper, we aim at bridging this gap by presenting a novel architecture called RedEx (Reduced Expander Extractor) that is as expressive as neural networks and can also be trained in a layer-wise fashion via a convex program with semi-definite constraints and optimization guarantees. We also show that RedEx provably surpasses fixed representation methods, in the sense that it can efficiently learn a family of target functions which fixed representation methods cannot.
Locally Optimal Descent for Dynamic Stepsize Scheduling
Nov 23, 2023



We introduce a novel dynamic learning-rate scheduling scheme grounded in theory with the goal of simplifying the manual and time-consuming tuning of schedules in practice. Our approach is based on estimating the locally-optimal stepsize, guaranteeing maximal descent in the direction of the stochastic gradient of the current step. We first establish theoretical convergence bounds for our method within the context of smooth non-convex stochastic optimization, matching state-of-the-art bounds while only assuming knowledge of the smoothness parameter. We then present a practical implementation of our algorithm and conduct systematic experiments across diverse datasets and optimization algorithms, comparing our scheme with existing state-of-the-art learning-rate schedulers. Our findings indicate that our method needs minimal tuning when compared to existing approaches, removing the need for auxiliary manual schedules and warm-up phases and achieving comparable performance with drastically reduced parameter tuning.
The Temporal Structure of Language Processing in the Human Brain Corresponds to The Layered Hierarchy of Deep Language Models
Oct 11, 2023Deep Language Models (DLMs) provide a novel computational paradigm for understanding the mechanisms of natural language processing in the human brain. Unlike traditional psycholinguistic models, DLMs use layered sequences of continuous numerical vectors to represent words and context, allowing a plethora of emerging applications such as human-like text generation. In this paper we show evidence that the layered hierarchy of DLMs may be used to model the temporal dynamics of language comprehension in the brain by demonstrating a strong correlation between DLM layer depth and the time at which layers are most predictive of the human brain. Our ability to temporally resolve individual layers benefits from our use of electrocorticography (ECoG) data, which has a much higher temporal resolution than noninvasive methods like fMRI. Using ECoG, we record neural activity from participants listening to a 30-minute narrative while also feeding the same narrative to a high-performing DLM (GPT2-XL). We then extract contextual embeddings from the different layers of the DLM and use linear encoding models to predict neural activity. We first focus on the Inferior Frontal Gyrus (IFG, or Broca's area) and then extend our model to track the increasing temporal receptive window along the linguistic processing hierarchy from auditory to syntactic and semantic areas. Our results reveal a connection between human language processing and DLMs, with the DLM's layer-by-layer accumulation of contextual information mirroring the timing of neural activity in high-order language areas.
Adversarial Robustness of Streaming Algorithms through Importance Sampling
Jun 28, 2021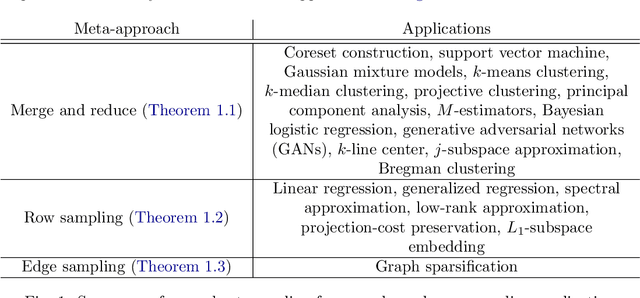
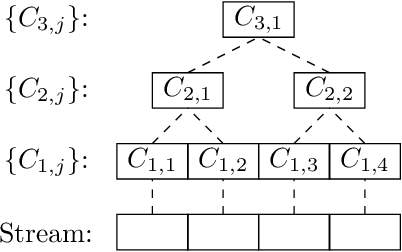
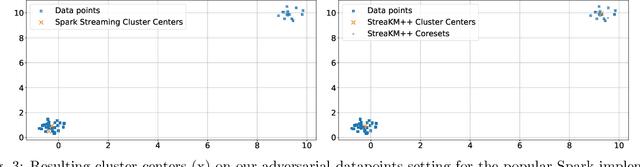

In this paper, we introduce adversarially robust streaming algorithms for central machine learning and algorithmic tasks, such as regression and clustering, as well as their more general counterparts, subspace embedding, low-rank approximation, and coreset construction. For regression and other numerical linear algebra related tasks, we consider the row arrival streaming model. Our results are based on a simple, but powerful, observation that many importance sampling-based algorithms give rise to adversarial robustness which is in contrast to sketching based algorithms, which are very prevalent in the streaming literature but suffer from adversarial attacks. In addition, we show that the well-known merge and reduce paradigm in streaming is adversarially robust. Since the merge and reduce paradigm allows coreset constructions in the streaming setting, we thus obtain robust algorithms for $k$-means, $k$-median, $k$-center, Bregman clustering, projective clustering, principal component analysis (PCA) and non-negative matrix factorization. To the best of our knowledge, these are the first adversarially robust results for these problems yet require no new algorithmic implementations. Finally, we empirically confirm the robustness of our algorithms on various adversarial attacks and demonstrate that by contrast, some common existing algorithms are not robust. (Abstract shortened to meet arXiv limits)
Asynchronous Stochastic Optimization Robust to Arbitrary Delays
Jun 22, 2021

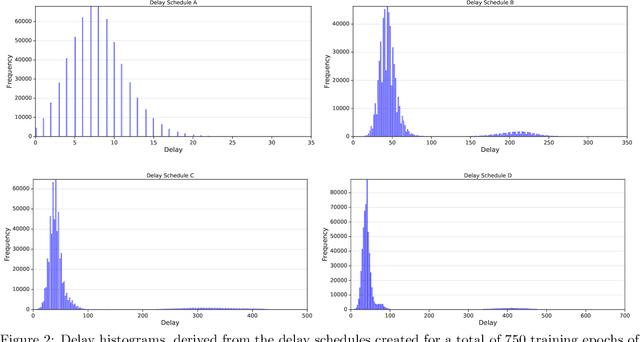

We consider stochastic optimization with delayed gradients where, at each time step $t$, the algorithm makes an update using a stale stochastic gradient from step $t - d_t$ for some arbitrary delay $d_t$. This setting abstracts asynchronous distributed optimization where a central server receives gradient updates computed by worker machines. These machines can experience computation and communication loads that might vary significantly over time. In the general non-convex smooth optimization setting, we give a simple and efficient algorithm that requires $O( \sigma^2/\epsilon^4 + \tau/\epsilon^2 )$ steps for finding an $\epsilon$-stationary point $x$, where $\tau$ is the \emph{average} delay $\smash{\frac{1}{T}\sum_{t=1}^T d_t}$ and $\sigma^2$ is the variance of the stochastic gradients. This improves over previous work, which showed that stochastic gradient decent achieves the same rate but with respect to the \emph{maximal} delay $\max_{t} d_t$, that can be significantly larger than the average delay especially in heterogeneous distributed systems. Our experiments demonstrate the efficacy and robustness of our algorithm in cases where the delay distribution is skewed or heavy-tailed.
Scalable Learning of Non-Decomposable Objectives
Mar 01, 2017
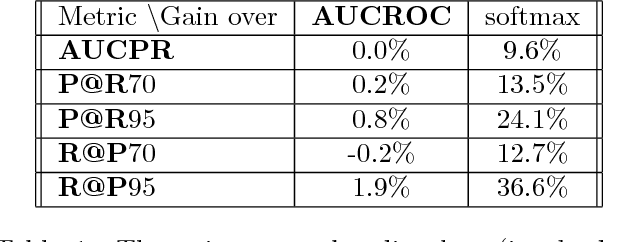
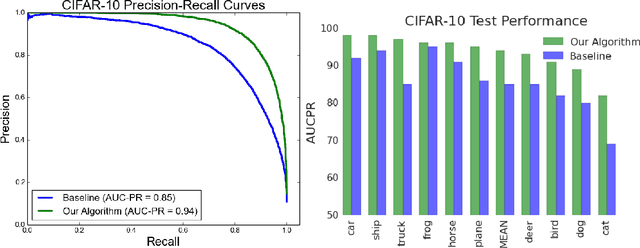
Modern retrieval systems are often driven by an underlying machine learning model. The goal of such systems is to identify and possibly rank the few most relevant items for a given query or context. Thus, such systems are typically evaluated using a ranking-based performance metric such as the area under the precision-recall curve, the $F_\beta$ score, precision at fixed recall, etc. Obviously, it is desirable to train such systems to optimize the metric of interest. In practice, due to the scalability limitations of existing approaches for optimizing such objectives, large-scale retrieval systems are instead trained to maximize classification accuracy, in the hope that performance as measured via the true objective will also be favorable. In this work we present a unified framework that, using straightforward building block bounds, allows for highly scalable optimization of a wide range of ranking-based objectives. We demonstrate the advantage of our approach on several real-life retrieval problems that are significantly larger than those considered in the literature, while achieving substantial improvement in performance over the accuracy-objective baseline.