 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Monocular Depth Learning in Dynamic Scenes
Nov 07, 2020


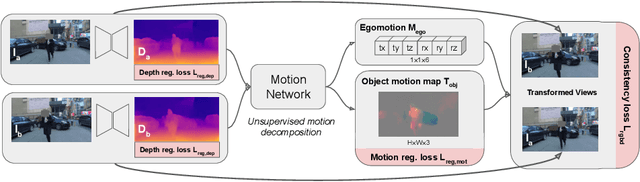
We present a method for jointly training the estimation of depth, ego-motion, and a dense 3D translation field of objects relative to the scene, with monocular photometric consistency being the sole source of supervision. We show that this apparently heavily underdetermined problem can be regularized by imposing the following prior knowledge about 3D translation fields: they are sparse, since most of the scene is static, and they tend to be constant for rigid moving objects. We show that this regularization alone is sufficient to train monocular depth prediction models that exceed the accuracy achieved in prior work for dynamic scenes, including methods that require semantic input. Code is at https://github.com/google-research/google-research/tree/master/depth_and_motion_learning .
What Matters in Unsupervised Optical Flow
Jun 08, 2020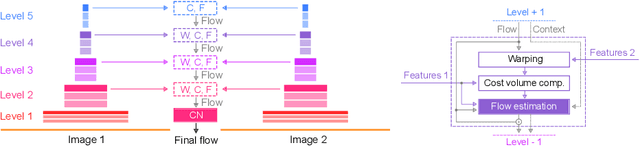
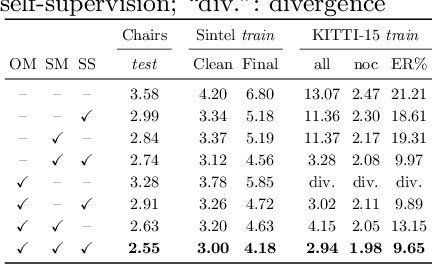


We systematically compare and analyze a set of key components in unsupervised optical flow to identify which photometric loss, occlusion handling, and smoothness regularization is most effective. Alongside this investigation we construct a number of novel improvements to unsupervised flow models, such as cost volume normalization, stopping the gradient at the occlusion mask, encouraging smoothness before upsampling the flow field, and continual self-supervision with image resizing. By combining the results of our investigation with our improved model components, we are able to present a new unsupervised flow technique that significantly outperforms the previous unsupervised state-of-the-art and performs on par with supervised FlowNet2 on the KITTI 2015 dataset, while also being significantly simpler than related approaches.
Taskology: Utilizing Task Relations at Scale
May 14, 2020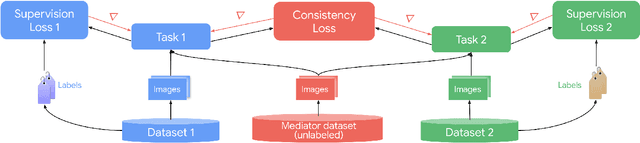
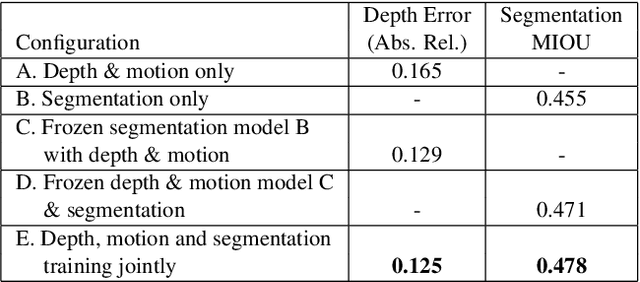
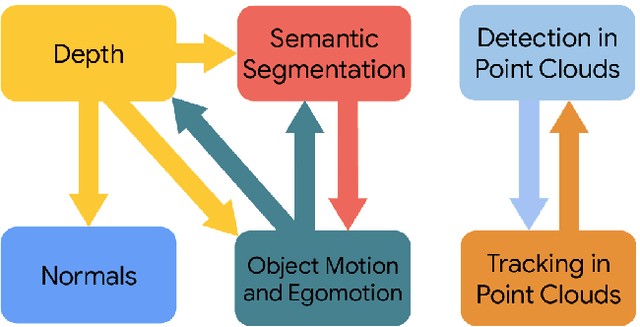
It has been recognized that the joint training of computer vision tasks with shared network components enables higher performance for each individual task. Training tasks together allows learning the inherent relationships among them; however, this requires large sets of labeled data. Instead, we argue that utilizing the known relationships between tasks explicitly allows improving their performance with less labeled data. To this end, we aim to establish and explore a novel approach for the collective training of computer vision tasks. In particular, we focus on utilizing the inherent relations of tasks by employing consistency constraints derived from physics, geometry, and logic. We show that collections of models can be trained without shared components, interacting only through the consistency constraints as supervision (peer-supervision). The consistency constraints enforce the structural priors between tasks, which enables their mutually consistent training, and -- in turn -- leads to overall higher performance. Treating individual tasks as modules, agnostic to their implementation, reduces the engineering overhead to collectively train many tasks to a minimum. Furthermore, the collective training can be distributed among multiple compute nodes, which further facilitates training at scale. We demonstrate our framework on subsets of the following collection of tasks: depth and normal prediction, semantic segmentation, 3D motion estimation, and object tracking and detection in point clouds.
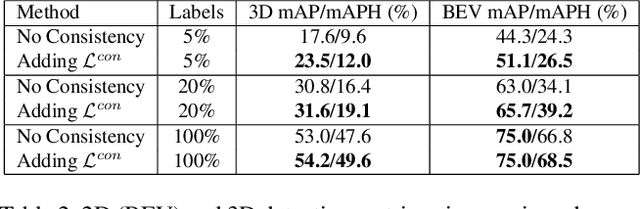
Improving Semantic Segmentation through Spatio-Temporal Consistency Learned from Videos
Apr 11, 2020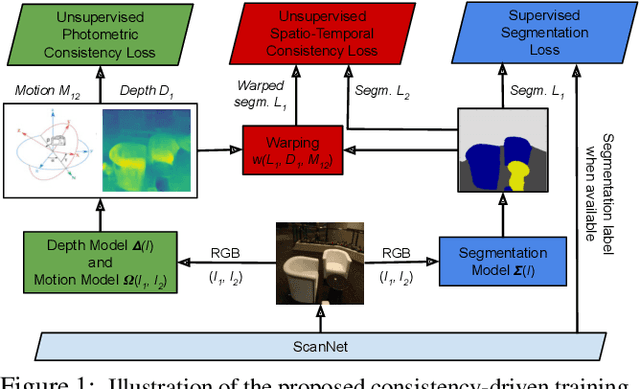

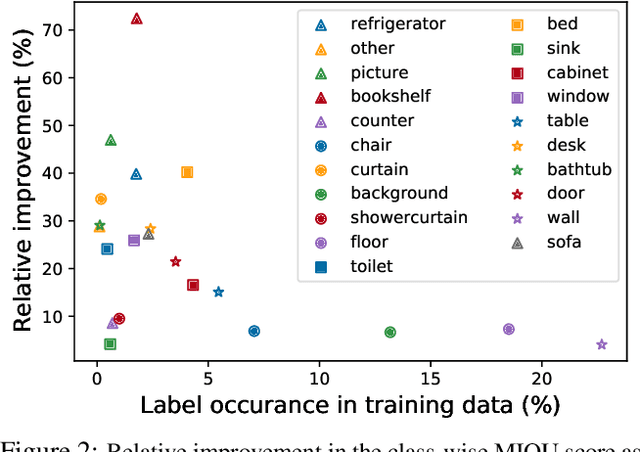
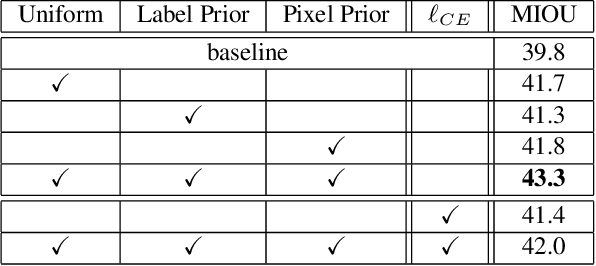
We leverage unsupervised learning of depth, egomotion, and camera intrinsics to improve the performance of single-image semantic segmentation, by enforcing 3D-geometric and temporal consistency of segmentation masks across video frames. The predicted depth, egomotion, and camera intrinsics are used to provide an additional supervision signal to the segmentation model, significantly enhancing its quality, or, alternatively, reducing the number of labels the segmentation model needs. Our experiments were performed on the ScanNet dataset.
Detecting Deficient Coverage in Colonoscopies
Jan 26, 2020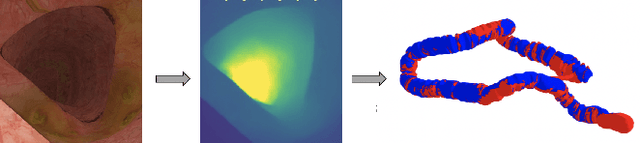
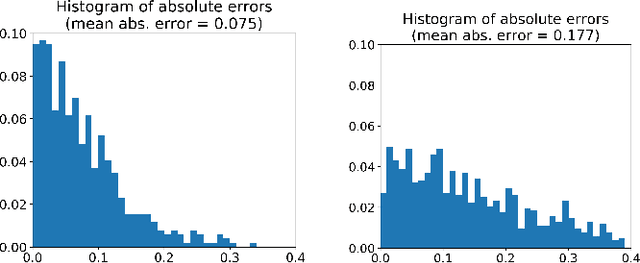
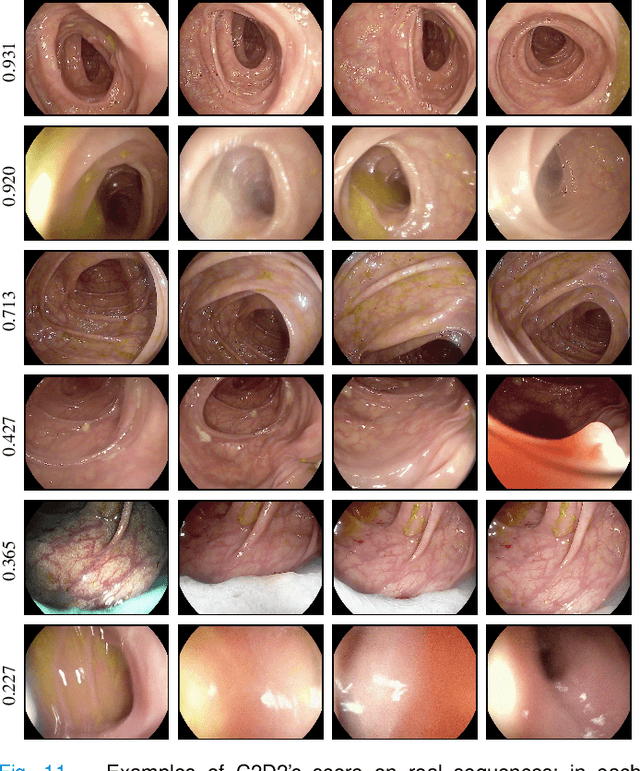
Colorectal Cancer (CRC) is a global health problem, resulting in 900K deaths per year. Colonoscopy is the tool of choice for preventing CRC, by detecting polyps before they become cancerous, and removing them. However, colonoscopy is hampered by the fact that endoscopists routinely miss an average of 22-28% of polyps. While some of these missed polyps appear in the endoscopist's field of view, others are missed simply because of substandard coverage of the procedure, i.e. not all of the colon is seen. This paper attempts to rectify the problem of substandard coverage in colonoscopy through the introduction of the C2D2 (Colonoscopy Coverage Deficiency via Depth) algorithm which detects deficient coverage, and can thereby alert the endoscopist to revisit a given area. More specifically, C2D2 consists of two separate algorithms: the first performs depth estimation of the colon given an ordinary RGB video stream; while the second computes coverage given these depth estimates. Rather than compute coverage for the entire colon, our algorithm computes coverage locally, on a segment-by-segment basis; C2D2 can then indicate in real-time whether a particular area of the colon has suffered from deficient coverage, and if so the endoscopist can return to that area. Our coverage algorithm is the first such algorithm to be evaluated in a large-scale way; while our depth estimation technique is the first calibration-free unsupervised method applied to colonoscopies. The C2D2 algorithm achieves state of the art results in the detection of deficient coverage: it is 2.4 times more accurate than human experts.
Computationally Efficient Neural Image Compression
Dec 18, 2019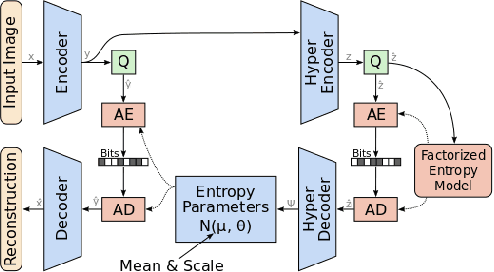


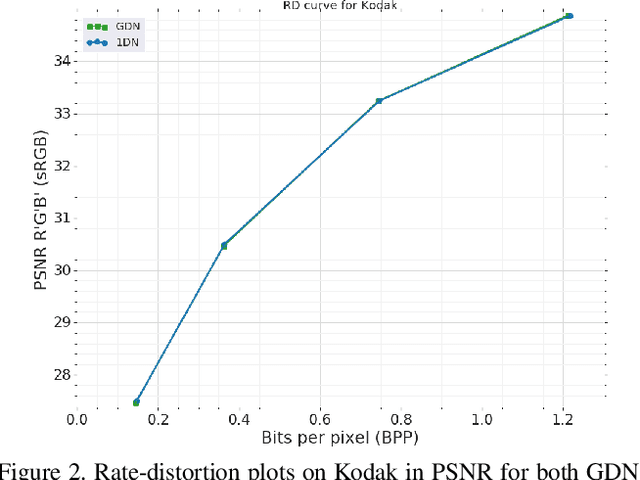
Image compression using neural networks have reached or exceeded non-neural methods (such as JPEG, WebP, BPG). While these networks are state of the art in ratedistortion performance, computational feasibility of these models remains a challenge. We apply automatic network optimization techniques to reduce the computational complexity of a popular architecture used in neural image compression, analyze the decoder complexity in execution runtime and explore the trade-offs between two distortion metrics, rate-distortion performance and run-time performance to design and research more computationally efficient neural image compression. We find that our method decreases the decoder run-time requirements by over 50% for a stateof-the-art neural architecture.
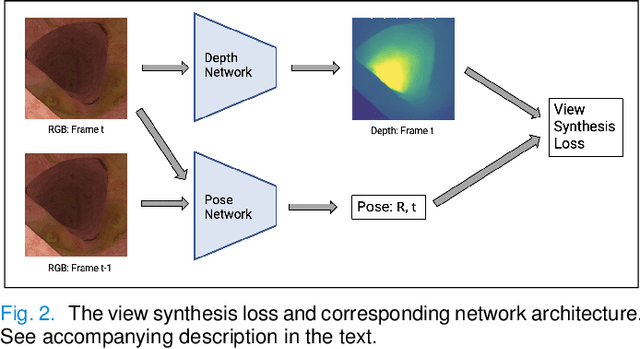
Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras
Apr 10, 2019
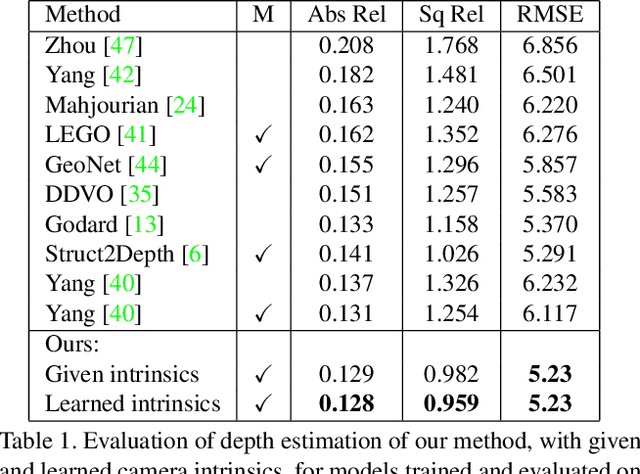
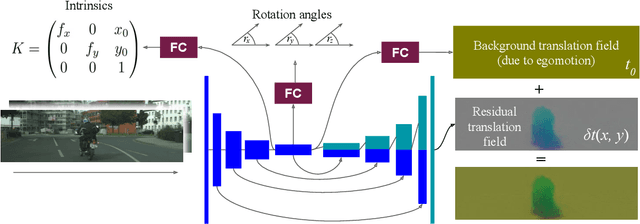
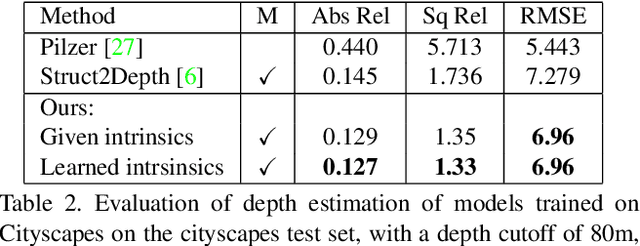
We present a novel method for simultaneous learning of depth, egomotion, object motion, and camera intrinsics from monocular videos, using only consistency across neighboring video frames as supervision signal. Similarly to prior work, our method learns by applying differentiable warping to frames and comparing the result to adjacent ones, but it provides several improvements: We address occlusions geometrically and differentiably, directly using the depth maps as predicted during training. We introduce randomized layer normalization, a novel powerful regularizer, and we account for object motion relative to the scene. To the best of our knowledge, our work is the first to learn the camera intrinsic parameters, including lens distortion, from video in an unsupervised manner, thereby allowing us to extract accurate depth and motion from arbitrary videos of unknown origin at scale. We evaluate our results on the Cityscapes, KITTI and EuRoC datasets, establishing new state of the art on depth prediction and odometry, and demonstrate qualitatively that depth prediction can be learned from a collection of YouTube videos.
MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks
Apr 17, 2018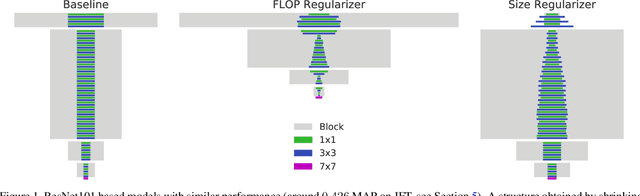
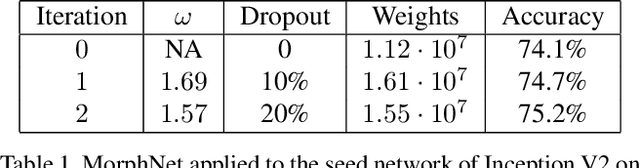
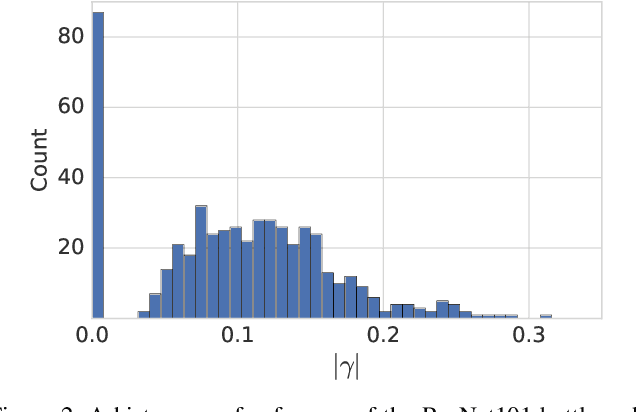
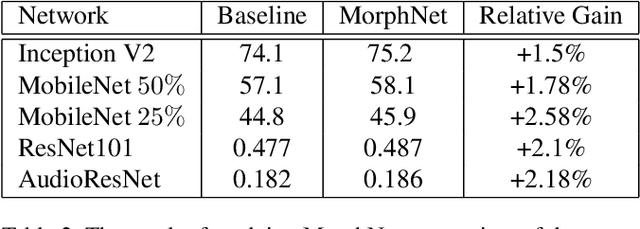
We present MorphNet, an approach to automate the design of neural network structures. MorphNet iteratively shrinks and expands a network, shrinking via a resource-weighted sparsifying regularizer on activations and expanding via a uniform multiplicative factor on all layers. In contrast to previous approaches, our method is scalable to large networks, adaptable to specific resource constraints (e.g. the number of floating-point operations per inference), and capable of increasing the network's performance. When applied to standard network architectures on a wide variety of datasets, our approach discovers novel structures in each domain, obtaining higher performance while respecting the resource constraint.
Scalable Learning of Non-Decomposable Objectives
Mar 01, 2017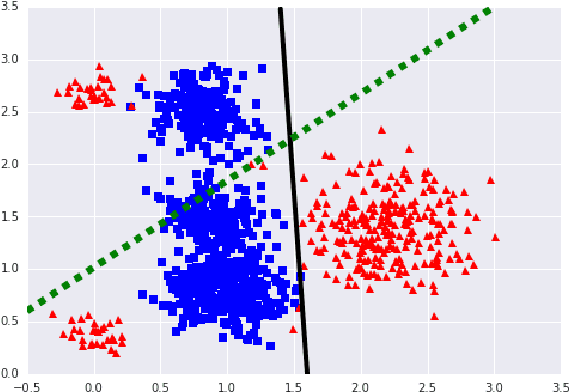
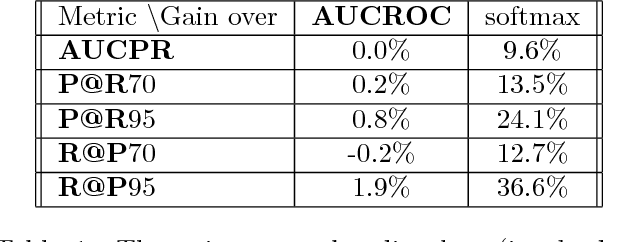
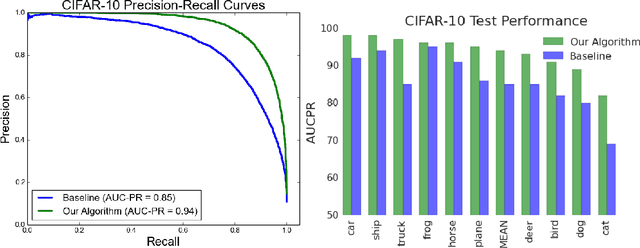
Modern retrieval systems are often driven by an underlying machine learning model. The goal of such systems is to identify and possibly rank the few most relevant items for a given query or context. Thus, such systems are typically evaluated using a ranking-based performance metric such as the area under the precision-recall curve, the $F_\beta$ score, precision at fixed recall, etc. Obviously, it is desirable to train such systems to optimize the metric of interest. In practice, due to the scalability limitations of existing approaches for optimizing such objectives, large-scale retrieval systems are instead trained to maximize classification accuracy, in the hope that performance as measured via the true objective will also be favorable. In this work we present a unified framework that, using straightforward building block bounds, allows for highly scalable optimization of a wide range of ranking-based objectives. We demonstrate the advantage of our approach on several real-life retrieval problems that are significantly larger than those considered in the literature, while achieving substantial improvement in performance over the accuracy-objective baseline.