 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier Basis Density Model
Feb 23, 2024
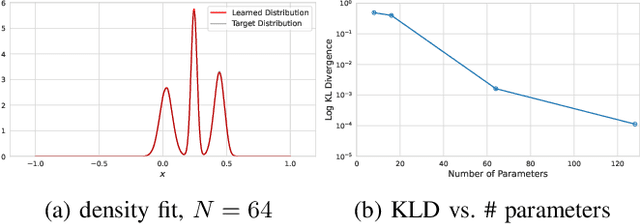

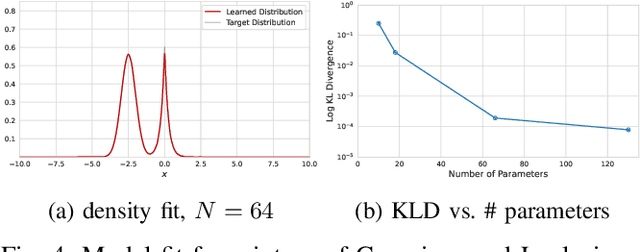
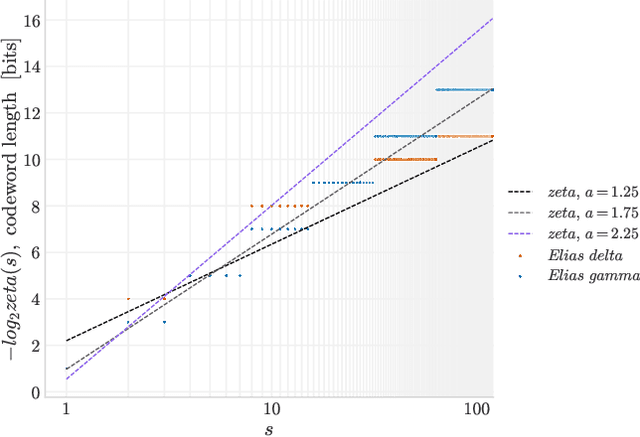
We introduce a lightweight, flexible and end-to-end trainable probability density model parameterized by a constrained Fourier basis. We assess its performance at approximating a range of multi-modal 1D densities, which are generally difficult to fit. In comparison to the deep factorized model introduced in [1], our model achieves a lower cross entropy at a similar computational budget. In addition, we also evaluate our method on a toy compression task, demonstrating its utility in learned compression.
Neural Distributed Compressor Discovers Binning
Oct 25, 2023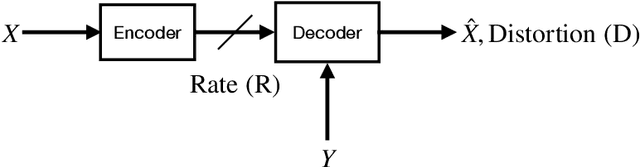
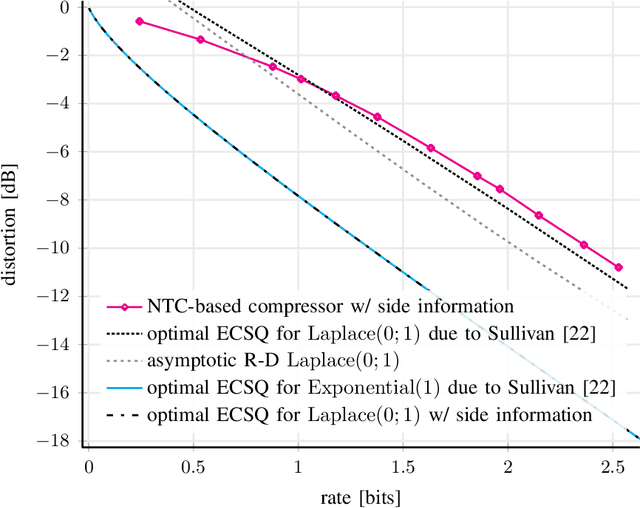
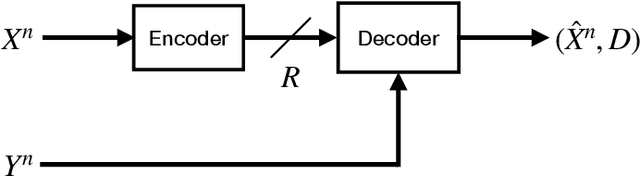
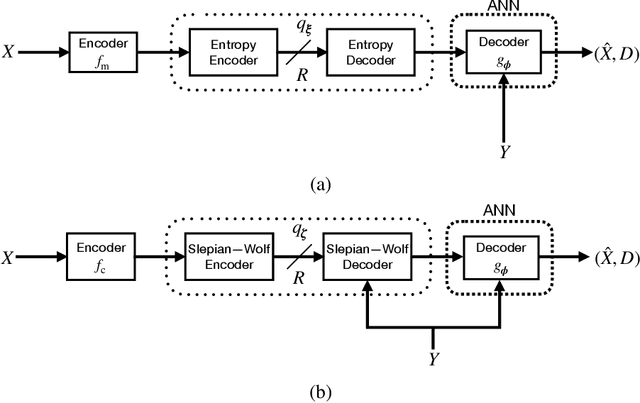
We consider lossy compression of an information source when the decoder has lossless access to a correlated one. This setup, also known as the Wyner-Ziv problem, is a special case of distributed source coding. To this day, practical approaches for the Wyner-Ziv problem have neither been fully developed nor heavily investigated. We propose a data-driven method based on machine learning that leverages the universal function approximation capability of artificial neural networks. We find that our neural network-based compression scheme, based on variational vector quantization, recovers some principles of the optimum theoretical solution of the Wyner-Ziv setup, such as binning in the source space as well as optimal combination of the quantization index and side information, for exemplary sources. These behaviors emerge although no structure exploiting knowledge of the source distributions was imposed. Binning is a widely used tool in information theoretic proofs and methods, and to our knowledge, this is the first time it has been explicitly observed to emerge from data-driven learning.
The Unreasonable Effectiveness of Linear Prediction as a Perceptual Metric
Oct 06, 2023



We show how perceptual embeddings of the visual system can be constructed at inference-time with no training data or deep neural network features. Our perceptual embeddings are solutions to a weighted least squares (WLS) problem, defined at the pixel-level, and solved at inference-time, that can capture global and local image characteristics. The distance in embedding space is used to define a perceptual similarity metric which we call LASI: Linear Autoregressive Similarity Index. Experiments on full-reference image quality assessment datasets show LASI performs competitively with learned deep feature based methods like LPIPS (Zhang et al., 2018) and PIM (Bhardwaj et al., 2020), at a similar computational cost to hand-crafted methods such as MS-SSIM (Wang et al., 2003). We found that increasing the dimensionality of the embedding space consistently reduces the WLS loss while increasing performance on perceptual tasks, at the cost of increasing the computational complexity. LASI is fully differentiable, scales cubically with the number of embedding dimensions, and can be parallelized at the pixel-level. A Maximum Differentiation (MAD) competition (Wang & Simoncelli, 2008) between LASI and LPIPS shows that both methods are capable of finding failure points for the other, suggesting these metrics can be combined.
Wasserstein Distortion: Unifying Fidelity and Realism
Oct 05, 2023



We introduce a distortion measure for images, Wasserstein distortion, that simultaneously generalizes pixel-level fidelity on the one hand and realism on the other. We show how Wasserstein distortion reduces mathematically to a pure fidelity constraint or a pure realism constraint under different parameter choices. Pairs of images that are close under Wasserstein distortion illustrate its utility. In particular, we generate random textures that have high fidelity to a reference texture in one location of the image and smoothly transition to an independent realization of the texture as one moves away from this point. Connections between Wasserstein distortion and models of the human visual system are noted.
Learned Wyner-Ziv Compressors Recover Binning
May 07, 2023


We consider lossy compression of an information source when the decoder has lossless access to a correlated one. This setup, also known as the Wyner-Ziv problem, is a special case of distributed source coding. To this day, real-world applications of this problem have neither been fully developed nor heavily investigated. We propose a data-driven method based on machine learning that leverages the universal function approximation capability of artificial neural networks. We find that our neural network-based compression scheme re-discovers some principles of the optimum theoretical solution of the Wyner-Ziv setup, such as binning in the source space as well as linear decoder behavior within each quantization index, for the quadratic-Gaussian case. These behaviors emerge although no structure exploiting knowledge of the source distributions was imposed. Binning is a widely used tool in information theoretic proofs and methods, and to our knowledge, this is the first time it has been explicitly observed to emerge from data-driven learning.
Do Neural Networks Compress Manifolds Optimally?
May 17, 2022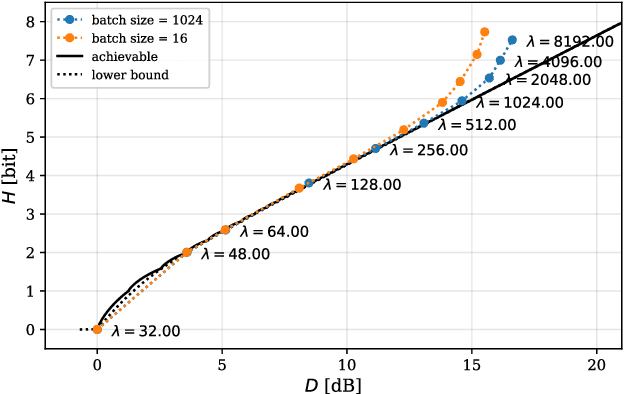
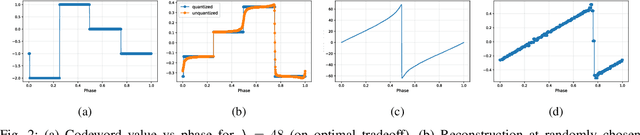
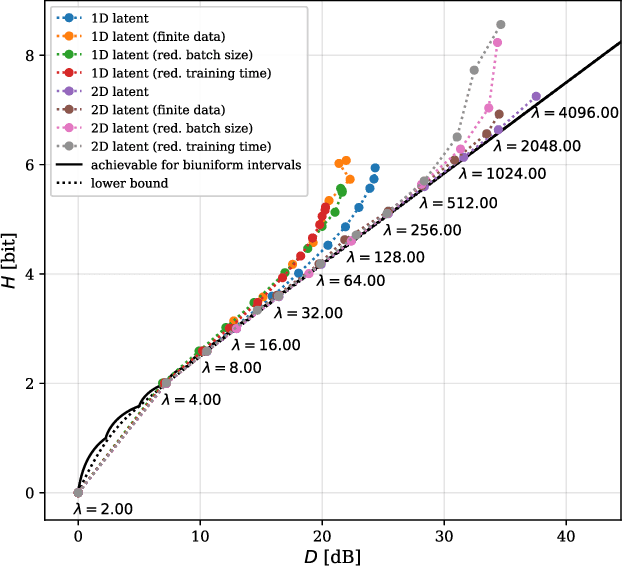
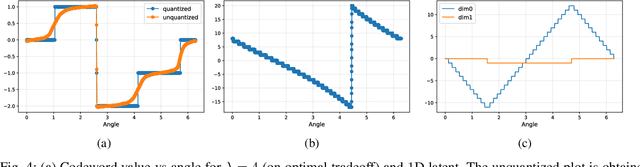
Artificial Neural-Network-based (ANN-based) lossy compressors have recently obtained striking results on several sources. Their success may be ascribed to an ability to identify the structure of low-dimensional manifolds in high-dimensional ambient spaces. Indeed, prior work has shown that ANN-based compressors can achieve the optimal entropy-distortion curve for some such sources. In contrast, we determine the optimal entropy-distortion tradeoffs for two low-dimensional manifolds with circular structure and show that state-of-the-art ANN-based compressors fail to optimally compress the sources, especially at high rates.
Optimizing the Communication-Accuracy Trade-off in Federated Learning with Rate-Distortion Theory
Jan 07, 2022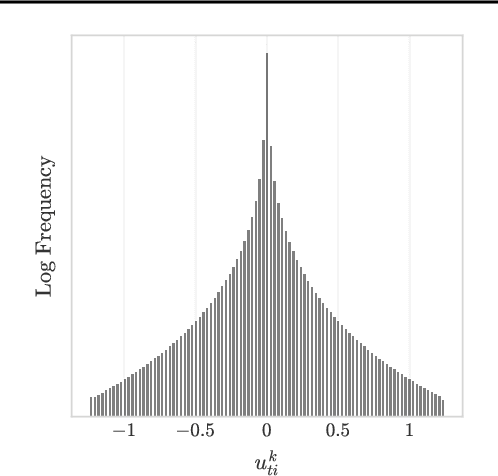

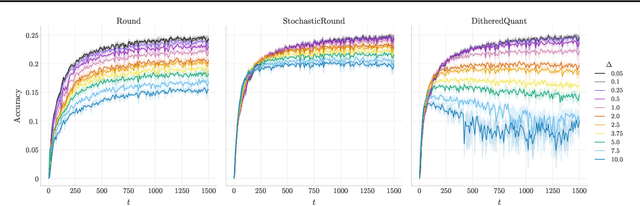
A significant bottleneck in federated learning is the network communication cost of sending model updates from client devices to the central server. We propose a method to reduce this cost. Our method encodes quantized updates with an appropriate universal code, taking into account their empirical distribution. Because quantization introduces error, we select quantization levels by optimizing for the desired trade-off in average total bitrate and gradient distortion. We demonstrate empirically that in spite of the non-i.i.d. nature of federated learning, the rate-distortion frontier is consistent across datasets, optimizers, clients and training rounds, and within each setting, distortion reliably predicts model performance. This allows for a remarkably simple compression scheme that is near-optimal in many use cases, and outperforms Top-K, DRIVE, 3LC and QSGD on the Stack Overflow next-word prediction benchmark.
Towards Generative Video Compression
Jul 26, 2021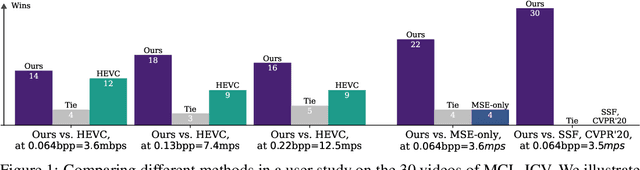
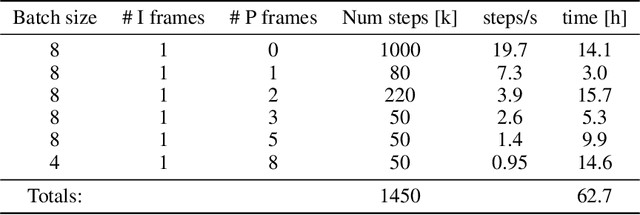
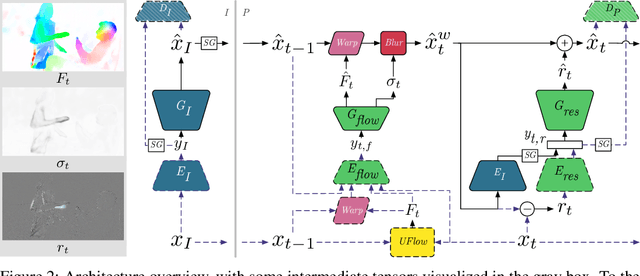
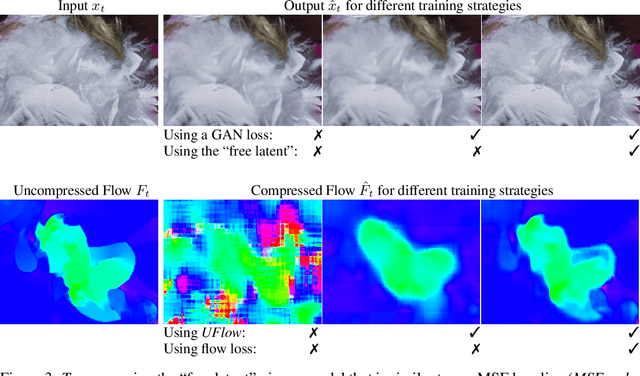
We present a neural video compression method based on generative adversarial networks (GANs) that outperforms previous neural video compression methods and is comparable to HEVC in a user study. We propose a technique to mitigate temporal error accumulation caused by recursive frame compression that uses randomized shifting and un-shifting, motivated by a spectral analysis. We present in detail the network design choices, their relative importance, and elaborate on the challenges of evaluating video compression methods in user studies.
On the relation between statistical learning and perceptual distances
Jun 08, 2021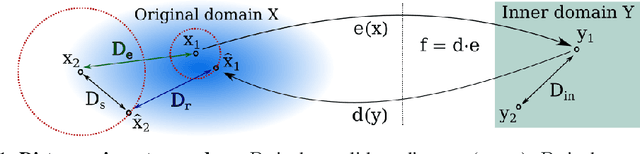
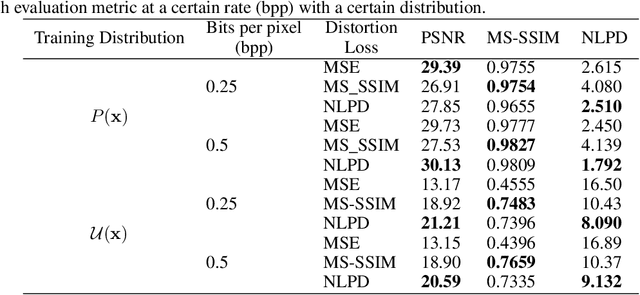
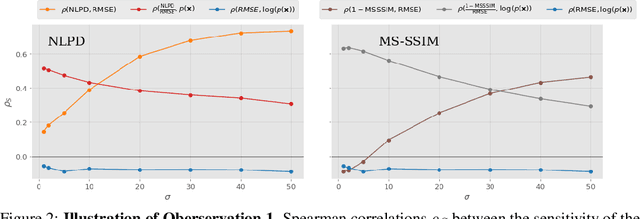
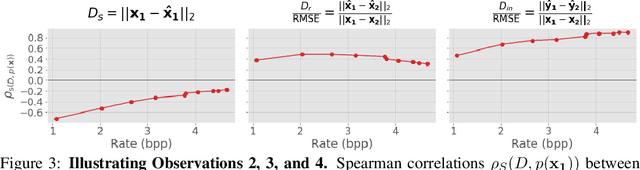
It has been demonstrated many times that the behavior of the human visual system is connected to the statistics of natural images. Since machine learning relies on the statistics of training data as well, the above connection has interesting implications when using perceptual distances (which mimic the behavior of the human visual system) as a loss function. In this paper, we aim to unravel the non-trivial relationship between the probability distribution of the data, perceptual distances, and unsupervised machine learning. To this end, we show that perceptual sensitivity is correlated with the probability of an image in its close neighborhood. We also explore the relation between distances induced by autoencoders and the probability distribution of the data used for training them, as well as how these induced distances are correlated with human perception. Finally, we discuss why perceptual distances might not lead to noticeable gains in performance over standard Euclidean distances in common image processing tasks except when data is scarce and the perceptual distance provides regularization.
3D Scene Compression through Entropy Penalized Neural Representation Functions
Apr 26, 2021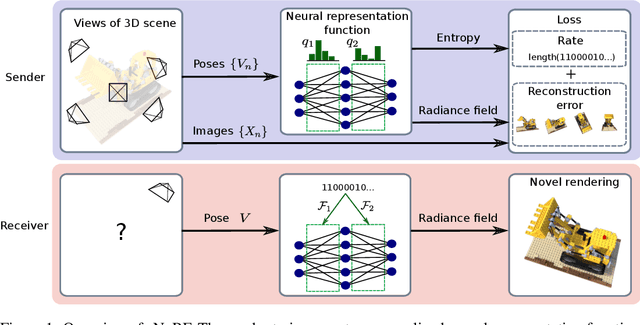
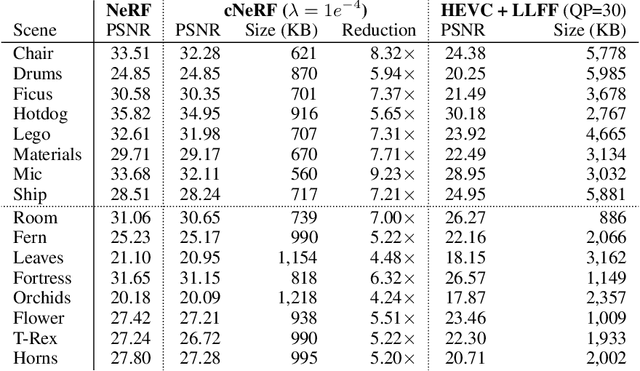
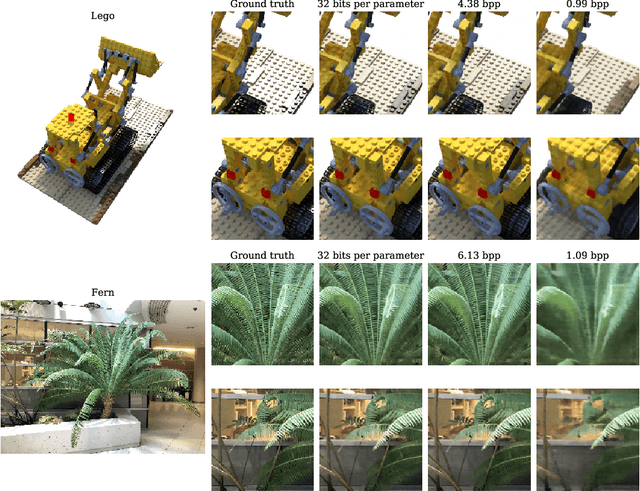
Some forms of novel visual media enable the viewer to explore a 3D scene from arbitrary viewpoints, by interpolating between a discrete set of original views. Compared to 2D imagery, these types of applications require much larger amounts of storage space, which we seek to reduce. Existing approaches for compressing 3D scenes are based on a separation of compression and rendering: each of the original views is compressed using traditional 2D image formats; the receiver decompresses the views and then performs the rendering. We unify these steps by directly compressing an implicit representation of the scene, a function that maps spatial coordinates to a radiance vector field, which can then be queried to render arbitrary viewpoints. The function is implemented as a neural network and jointly trained for reconstruction as well as compressibility, in an end-to-end manner, with the use of an entropy penalty on the parameters. Our method significantly outperforms a state-of-the-art conventional approach for scene compression, achieving simultaneously higher quality reconstructions and lower bitrates. Furthermore, we show that the performance at lower bitrates can be improved by jointly representing multiple scenes using a soft form of parameter sharing.