 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo
Mar 12, 2025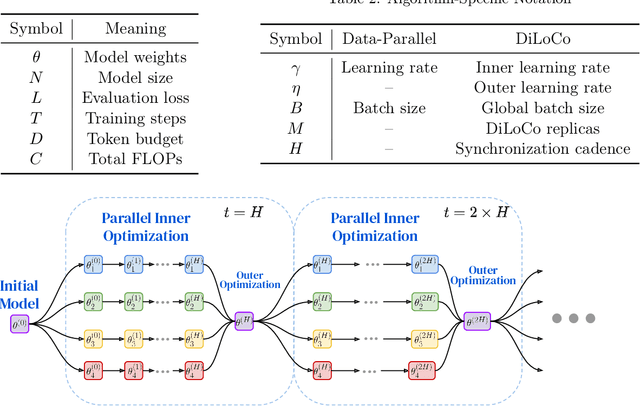
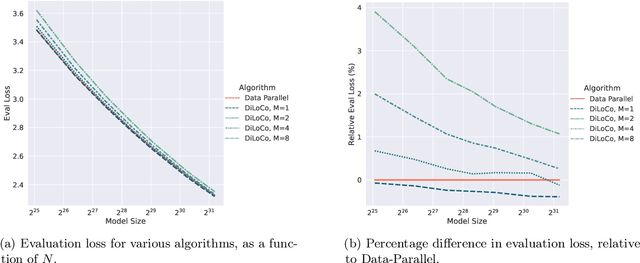
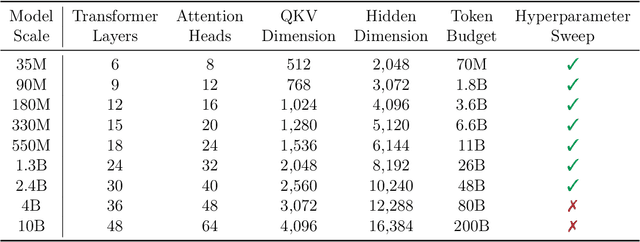
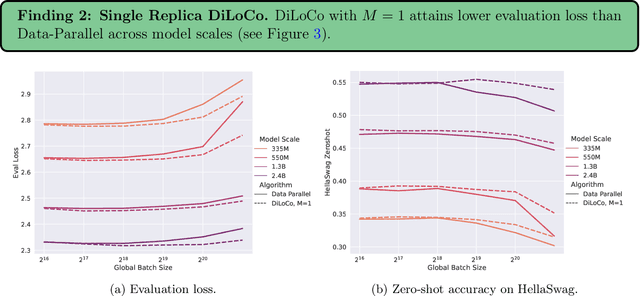
As we scale to more massive machine learning models, the frequent synchronization demands inherent in data-parallel approaches create significant slowdowns, posing a critical challenge to further scaling. Recent work develops an approach (DiLoCo) that relaxes synchronization demands without compromising model quality. However, these works do not carefully analyze how DiLoCo's behavior changes with model size. In this work, we study the scaling law behavior of DiLoCo when training LLMs under a fixed compute budget. We focus on how algorithmic factors, including number of model replicas, hyperparameters, and token budget affect training in ways that can be accurately predicted via scaling laws. We find that DiLoCo scales both predictably and robustly with model size. When well-tuned, DiLoCo scales better than data-parallel training with model size, and can outperform data-parallel training even at small model sizes. Our results showcase a more general set of benefits of DiLoCo than previously documented, including increased optimal batch sizes, improved downstream generalization with scale, and improved evaluation loss for a fixed token budget.
Scaling Laws for Differentially Private Language Models
Jan 31, 2025Scaling laws have emerged as important components of large language model (LLM) training as they can predict performance gains through scale, and provide guidance on important hyper-parameter choices that would otherwise be expensive. LLMs also rely on large, high-quality training datasets, like those sourced from (sometimes sensitive) user data. Training models on this sensitive user data requires careful privacy protections like differential privacy (DP). However, the dynamics of DP training are significantly different, and consequently their scaling laws are not yet fully understood. In this work, we establish scaling laws that accurately model the intricacies of DP LLM training, providing a complete picture of the compute-privacy-utility tradeoffs and the optimal training configurations in many settings.
Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
Jan 30, 2025Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at each and every single gradient step, all devices need to be co-located using low-latency high-bandwidth communication links to support the required high volume of exchanged bits. Recently, distributed algorithms like DiLoCo have relaxed such co-location constraint: accelerators can be grouped into ``workers'', where synchronizations between workers only occur infrequently. This in turn means that workers can afford being connected by lower bandwidth communication links without affecting learning quality. However, in these methods, communication across workers still requires the same peak bandwidth as before, as the synchronizations require all parameters to be exchanged across all workers. In this paper, we improve DiLoCo in three ways. First, we synchronize only subsets of parameters in sequence, rather than all at once, which greatly reduces peak bandwidth. Second, we allow workers to continue training while synchronizing, which decreases wall clock time. Third, we quantize the data exchanged by workers, which further reduces bandwidth across workers. By properly combining these modifications, we show experimentally that we can distribute training of billion-scale parameters and reach similar quality as before, but reducing required bandwidth by two orders of magnitude.
Fine-Tuning Large Language Models with User-Level Differential Privacy
Jul 10, 2024We investigate practical and scalable algorithms for training large language models (LLMs) with user-level differential privacy (DP) in order to provably safeguard all the examples contributed by each user. We study two variants of DP-SGD with: (1) example-level sampling (ELS) and per-example gradient clipping, and (2) user-level sampling (ULS) and per-user gradient clipping. We derive a novel user-level DP accountant that allows us to compute provably tight privacy guarantees for ELS. Using this, we show that while ELS can outperform ULS in specific settings, ULS generally yields better results when each user has a diverse collection of examples. We validate our findings through experiments in synthetic mean estimation and LLM fine-tuning tasks under fixed compute budgets. We find that ULS is significantly better in settings where either (1) strong privacy guarantees are required, or (2) the compute budget is large. Notably, our focus on LLM-compatible training algorithms allows us to scale to models with hundreds of millions of parameters and datasets with hundreds of thousands of users.
FAX: Scalable and Differentiable Federated Primitives in JAX
Mar 11, 2024



We present FAX, a JAX-based library designed to support large-scale distributed and federated computations in both data center and cross-device applications. FAX leverages JAX's sharding mechanisms to enable native targeting of TPUs and state-of-the-art JAX runtimes, including Pathways. FAX embeds building blocks for federated computations as primitives in JAX. This enables three key benefits. First, FAX computations can be translated to XLA HLO. Second, FAX provides a full implementation of federated automatic differentiation, greatly simplifying the expression of federated computations. Last, FAX computations can be interpreted out to existing production cross-device federated compute systems. We show that FAX provides an easily programmable, performant, and scalable framework for federated computations in the data center. FAX is available at https://github.com/google-research/google-research/tree/master/fax .
Leveraging Function Space Aggregation for Federated Learning at Scale
Nov 17, 2023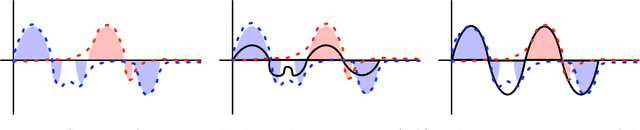
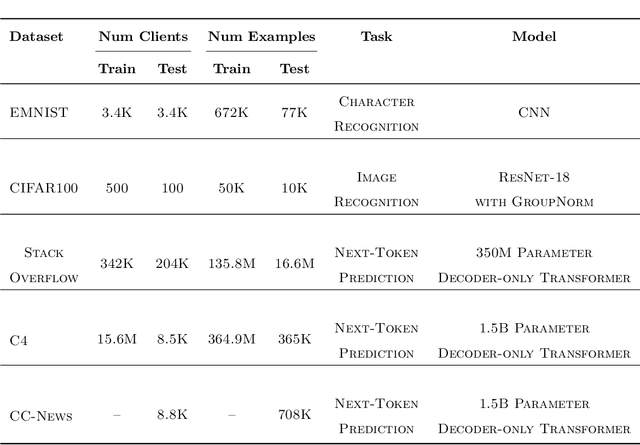
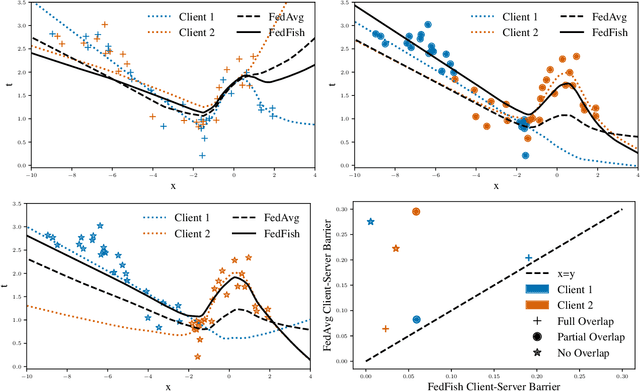
The federated learning paradigm has motivated the development of methods for aggregating multiple client updates into a global server model, without sharing client data. Many federated learning algorithms, including the canonical Federated Averaging (FedAvg), take a direct (possibly weighted) average of the client parameter updates, motivated by results in distributed optimization. In this work, we adopt a function space perspective and propose a new algorithm, FedFish, that aggregates local approximations to the functions learned by clients, using an estimate based on their Fisher information. We evaluate FedFish on realistic, large-scale cross-device benchmarks. While the performance of FedAvg can suffer as client models drift further apart, we demonstrate that FedFish is more robust to longer local training. Our evaluation across several settings in image and language benchmarks shows that FedFish outperforms FedAvg as local training epochs increase. Further, FedFish results in global networks that are more amenable to efficient personalization via local fine-tuning on the same or shifted data distributions. For instance, federated pretraining on the C4 dataset, followed by few-shot personalization on Stack Overflow, results in a 7% improvement in next-token prediction by FedFish over FedAvg.
Towards Federated Foundation Models: Scalable Dataset Pipelines for Group-Structured Learning
Jul 18, 2023We introduce a library, Dataset Grouper, to create large-scale group-structured (e.g., federated) datasets, enabling federated learning simulation at the scale of foundation models. This library allows the creation of group-structured versions of existing datasets based on user-specified partitions, and directly leads to a variety of useful heterogeneous datasets that can be plugged into existing software frameworks. Dataset Grouper offers three key advantages. First, it scales to settings where even a single group's dataset is too large to fit in memory. Second, it provides flexibility, both in choosing the base (non-partitioned) dataset and in defining partitions. Finally, it is framework-agnostic. We empirically demonstrate that Dataset Grouper allows for large-scale federated language modeling simulations on datasets that are orders of magnitude larger than in previous work. Our experimental results show that algorithms like FedAvg operate more as meta-learning methods than as empirical risk minimization methods at this scale, suggesting their utility in downstream personalization and task-specific adaptation.
Convergence of Gradient Descent with Linearly Correlated Noise and Applications to Differentially Private Learning
Feb 02, 2023



We study stochastic optimization with linearly correlated noise. Our study is motivated by recent methods for optimization with differential privacy (DP), such as DP-FTRL, which inject noise via matrix factorization mechanisms. We propose an optimization problem that distils key facets of these DP methods and that involves perturbing gradients by linearly correlated noise. We derive improved convergence rates for gradient descent in this framework for convex and non-convex loss functions. Our theoretical analysis is novel and might be of independent interest. We use these convergence rates to develop new, effective matrix factorizations for differentially private optimization, and highlight the benefits of these factorizations theoretically and empirically.
Federated Automatic Differentiation
Jan 18, 2023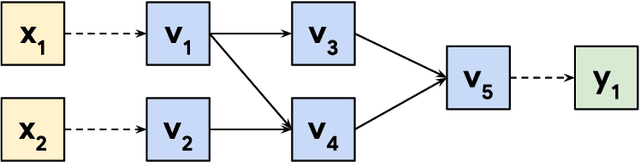
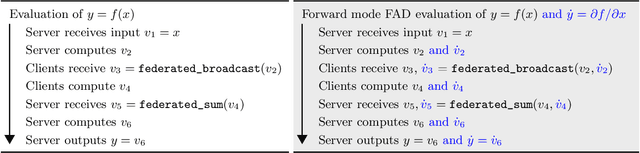
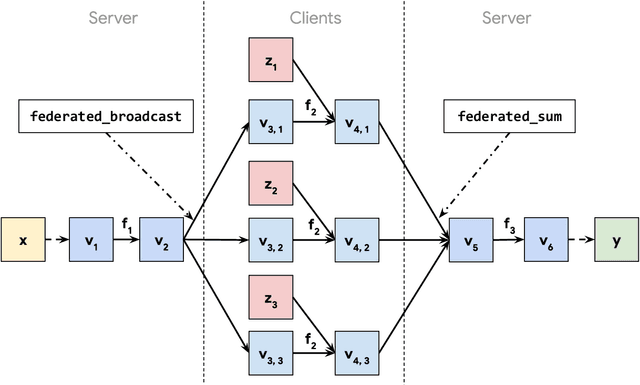

Federated learning (FL) is a general framework for learning across heterogeneous clients while preserving data privacy, under the orchestration of a central server. FL methods often compute gradients of loss functions purely locally (ie. entirely at each client, or entirely at the server), typically using automatic differentiation (AD) techniques. We propose a federated automatic differentiation (FAD) framework that 1) enables computing derivatives of functions involving client and server computation as well as communication between them and 2) operates in a manner compatible with existing federated technology. In other words, FAD computes derivatives across communication boundaries. We show, in analogy with traditional AD, that FAD may be implemented using various accumulation modes, which introduce distinct computation-communication trade-offs and systems requirements. Further, we show that a broad class of federated computations is closed under these various modes of FAD, implying in particular that if the original computation can be implemented using privacy-preserving primitives, its derivative may be computed using only these same primitives. We then show how FAD can be used to create algorithms that dynamically learn components of the algorithm itself. In particular, we show that FedAvg-style algorithms can exhibit significantly improved performance by using FAD to adjust the server optimization step automatically, or by using FAD to learn weighting schemes for computing weighted averages across clients.
Federated Select: A Primitive for Communication- and Memory-Efficient Federated Learning
Aug 19, 2022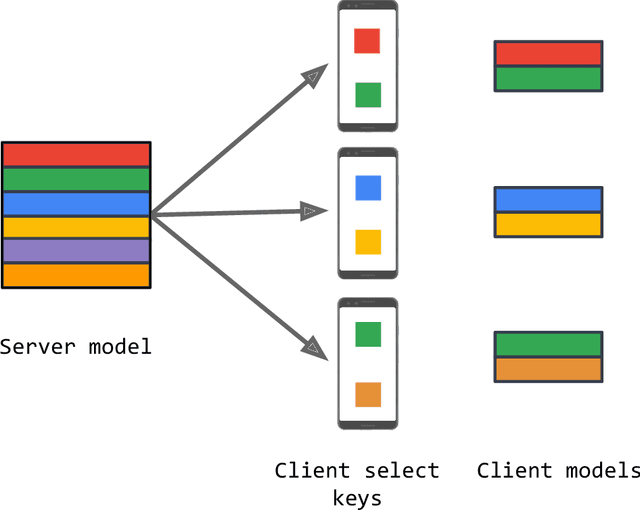

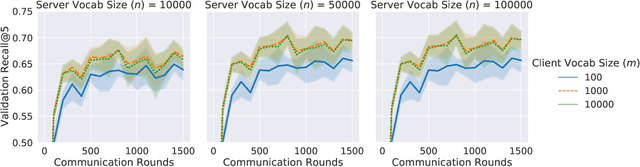
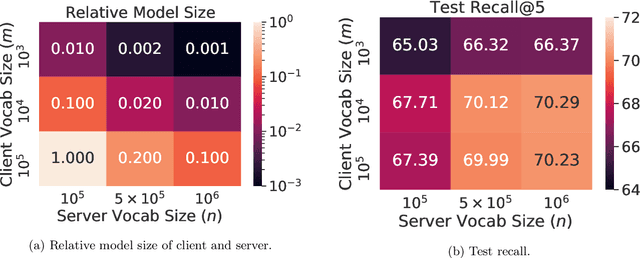
Federated learning (FL) is a framework for machine learning across heterogeneous client devices in a privacy-preserving fashion. To date, most FL algorithms learn a "global" server model across multiple rounds. At each round, the same server model is broadcast to all participating clients, updated locally, and then aggregated across clients. In this work, we propose a more general procedure in which clients "select" what values are sent to them. Notably, this allows clients to operate on smaller, data-dependent slices. In order to make this practical, we outline a primitive, federated select, which enables client-specific selection in realistic FL systems. We discuss how to use federated select for model training and show that it can lead to drastic reductions in communication and client memory usage, potentially enabling the training of models too large to fit on-device. We also discuss the implications of federated select on privacy and trust, which in turn affect possible system constraints and design. Finally, we discuss open questions concerning model architectures, privacy-preserving technologies, and practical FL systems.