 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo
Mar 12, 2025
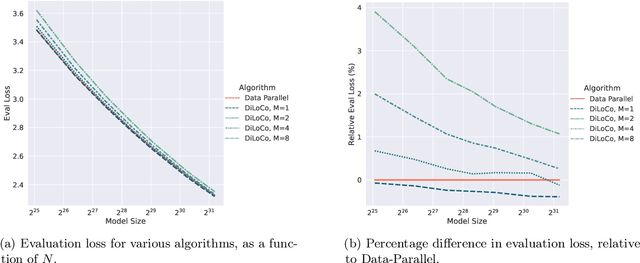
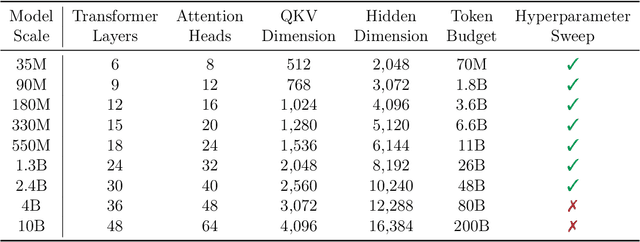
As we scale to more massive machine learning models, the frequent synchronization demands inherent in data-parallel approaches create significant slowdowns, posing a critical challenge to further scaling. Recent work develops an approach (DiLoCo) that relaxes synchronization demands without compromising model quality. However, these works do not carefully analyze how DiLoCo's behavior changes with model size. In this work, we study the scaling law behavior of DiLoCo when training LLMs under a fixed compute budget. We focus on how algorithmic factors, including number of model replicas, hyperparameters, and token budget affect training in ways that can be accurately predicted via scaling laws. We find that DiLoCo scales both predictably and robustly with model size. When well-tuned, DiLoCo scales better than data-parallel training with model size, and can outperform data-parallel training even at small model sizes. Our results showcase a more general set of benefits of DiLoCo than previously documented, including increased optimal batch sizes, improved downstream generalization with scale, and improved evaluation loss for a fixed token budget.
Everybody Prune Now: Structured Pruning of LLMs with only Forward Passes
Feb 09, 2024



Given the generational gap in available hardware between lay practitioners and the most endowed institutions, LLMs are becoming increasingly inaccessible as they grow in size. Whilst many approaches have been proposed to compress LLMs to make their resource consumption manageable, these methods themselves tend to be resource intensive, putting them out of the reach of the very user groups they target. In this work, we explore the problem of structured pruning of LLMs using only forward passes. We seek to empower practitioners to prune models so large that their available hardware has just enough memory to run inference. We develop Bonsai, a gradient-free, perturbative pruning method capable of delivering small, fast, and accurate pruned models. We observe that Bonsai outputs pruned models that (i) outperform those generated by more expensive gradient-based structured pruning methods, and (ii) are twice as fast (with comparable accuracy) as those generated by semi-structured pruning methods requiring comparable resources as Bonsai. We also leverage Bonsai to produce a new sub-2B model using a single A6000 that yields state-of-the-art performance on 4/6 tasks on the Huggingface Open LLM leaderboard.
Multitask Learning Can Improve Worst-Group Outcomes
Dec 05, 2023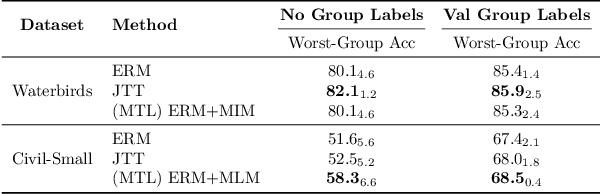
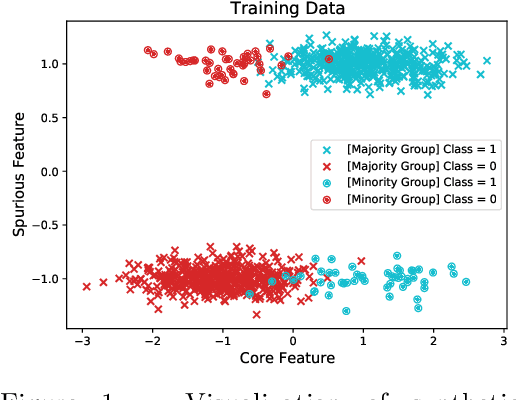
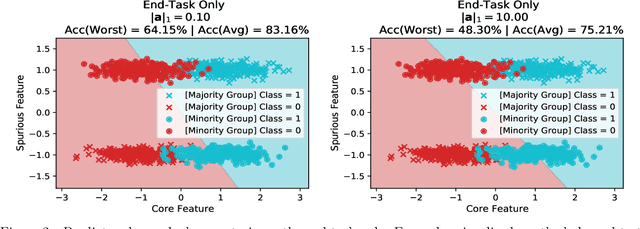

In order to create machine learning systems that serve a variety of users well, it is vital to not only achieve high average performance but also ensure equitable outcomes across diverse groups. However, most machine learning methods are designed to improve a model's average performance on a chosen end task without consideration for their impact on worst group error. Multitask learning (MTL) is one such widely used technique. In this paper, we seek not only to understand the impact of MTL on worst-group accuracy but also to explore its potential as a tool to address the challenge of group-wise fairness. We primarily consider the common setting of fine-tuning a pre-trained model, where, following recent work (Gururangan et al., 2020; Dery et al., 2023), we multitask the end task with the pre-training objective constructed from the end task data itself. In settings with few or no group annotations, we find that multitasking often, but not always, achieves better worst-group accuracy than Just-Train-Twice (JTT; Liu et al. (2021)) -- a representative distributionally robust optimization (DRO) method. Leveraging insights from synthetic data experiments, we propose to modify standard MTL by regularizing the joint multitask representation space. We run a large number of fine-tuning experiments across computer vision and natural language and find that our regularized MTL approach consistently outperforms JTT on both worst and average group outcomes. Our official code can be found here: https://github.com/atharvajk98/MTL-group-robustness.
Transfer Learning for Structured Pruning under Limited Task Data
Nov 10, 2023



Large, pre-trained models are problematic to use in resource constrained applications. Fortunately, task-aware structured pruning methods offer a solution. These approaches reduce model size by dropping structural units like layers and attention heads in a manner that takes into account the end-task. However, these pruning algorithms require more task-specific data than is typically available. We propose a framework which combines structured pruning with transfer learning to reduce the need for task-specific data. Our empirical results answer questions such as: How should the two tasks be coupled? What parameters should be transferred? And, when during training should transfer learning be introduced? Leveraging these insights, we demonstrate that our framework results in pruned models with improved generalization over strong baselines.
DeMuX: Data-efficient Multilingual Learning
Nov 10, 2023



We consider the task of optimally fine-tuning pre-trained multilingual models, given small amounts of unlabelled target data and an annotation budget. In this paper, we introduce DEMUX, a framework that prescribes the exact data-points to label from vast amounts of unlabelled multilingual data, having unknown degrees of overlap with the target set. Unlike most prior works, our end-to-end framework is language-agnostic, accounts for model representations, and supports multilingual target configurations. Our active learning strategies rely upon distance and uncertainty measures to select task-specific neighbors that are most informative to label, given a model. DeMuX outperforms strong baselines in 84% of the test cases, in the zero-shot setting of disjoint source and target language sets (including multilingual target pools), across three models and four tasks. Notably, in low-budget settings (5-100 examples), we observe gains of up to 8-11 F1 points for token-level tasks, and 2-5 F1 for complex tasks. Our code is released here: https://github.com/simran-khanuja/demux.