 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Learning Can Improve Worst-Group Outcomes
Paper and Code
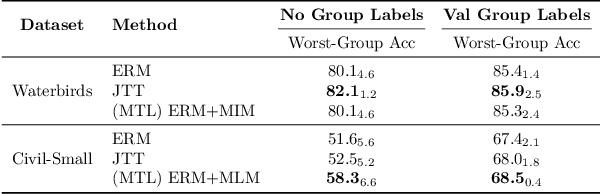
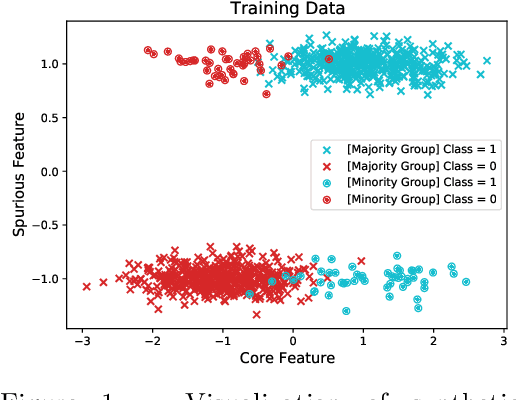
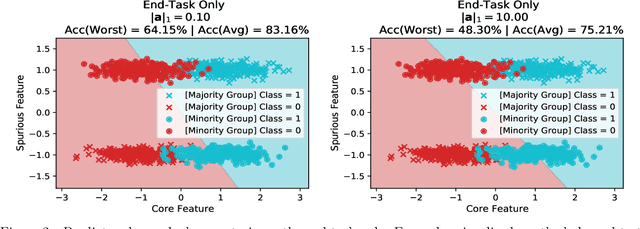

In order to create machine learning systems that serve a variety of users well, it is vital to not only achieve high average performance but also ensure equitable outcomes across diverse groups. However, most machine learning methods are designed to improve a model's average performance on a chosen end task without consideration for their impact on worst group error. Multitask learning (MTL) is one such widely used technique. In this paper, we seek not only to understand the impact of MTL on worst-group accuracy but also to explore its potential as a tool to address the challenge of group-wise fairness. We primarily consider the common setting of fine-tuning a pre-trained model, where, following recent work (Gururangan et al., 2020; Dery et al., 2023), we multitask the end task with the pre-training objective constructed from the end task data itself. In settings with few or no group annotations, we find that multitasking often, but not always, achieves better worst-group accuracy than Just-Train-Twice (JTT; Liu et al. (2021)) -- a representative distributionally robust optimization (DRO) method. Leveraging insights from synthetic data experiments, we propose to modify standard MTL by regularizing the joint multitask representation space. We run a large number of fine-tuning experiments across computer vision and natural language and find that our regularized MTL approach consistently outperforms JTT on both worst and average group outcomes. Our official code can be found here: https://github.com/atharvajk98/MTL-group-robustness.