 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo
Mar 12, 2025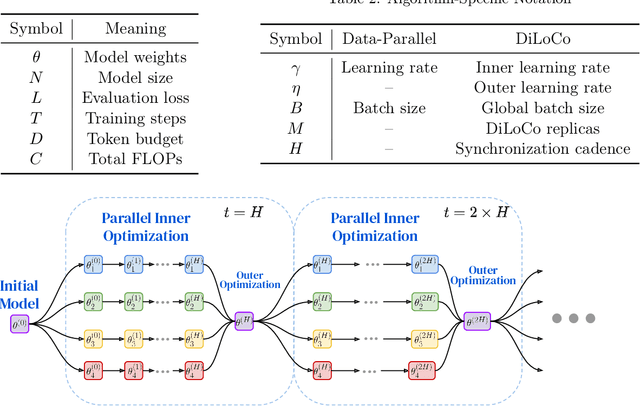
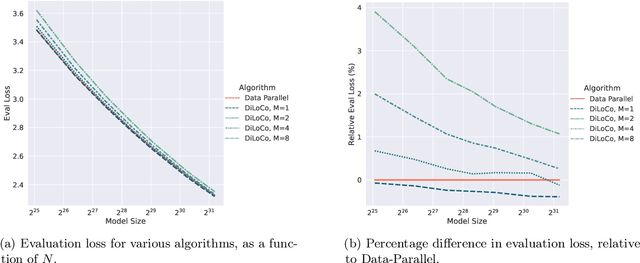
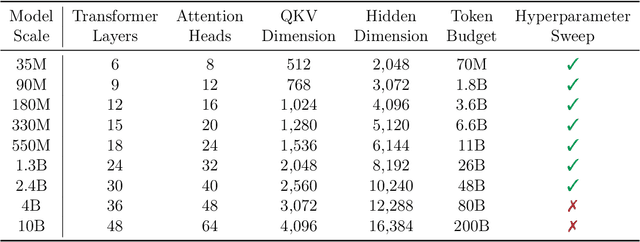
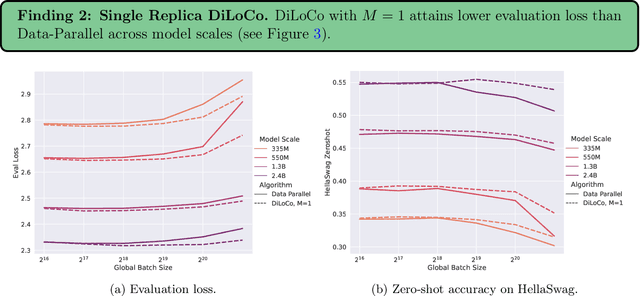
As we scale to more massive machine learning models, the frequent synchronization demands inherent in data-parallel approaches create significant slowdowns, posing a critical challenge to further scaling. Recent work develops an approach (DiLoCo) that relaxes synchronization demands without compromising model quality. However, these works do not carefully analyze how DiLoCo's behavior changes with model size. In this work, we study the scaling law behavior of DiLoCo when training LLMs under a fixed compute budget. We focus on how algorithmic factors, including number of model replicas, hyperparameters, and token budget affect training in ways that can be accurately predicted via scaling laws. We find that DiLoCo scales both predictably and robustly with model size. When well-tuned, DiLoCo scales better than data-parallel training with model size, and can outperform data-parallel training even at small model sizes. Our results showcase a more general set of benefits of DiLoCo than previously documented, including increased optimal batch sizes, improved downstream generalization with scale, and improved evaluation loss for a fixed token budget.
Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
Jan 30, 2025Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at each and every single gradient step, all devices need to be co-located using low-latency high-bandwidth communication links to support the required high volume of exchanged bits. Recently, distributed algorithms like DiLoCo have relaxed such co-location constraint: accelerators can be grouped into ``workers'', where synchronizations between workers only occur infrequently. This in turn means that workers can afford being connected by lower bandwidth communication links without affecting learning quality. However, in these methods, communication across workers still requires the same peak bandwidth as before, as the synchronizations require all parameters to be exchanged across all workers. In this paper, we improve DiLoCo in three ways. First, we synchronize only subsets of parameters in sequence, rather than all at once, which greatly reduces peak bandwidth. Second, we allow workers to continue training while synchronizing, which decreases wall clock time. Third, we quantize the data exchanged by workers, which further reduces bandwidth across workers. By properly combining these modifications, we show experimentally that we can distribute training of billion-scale parameters and reach similar quality as before, but reducing required bandwidth by two orders of magnitude.
Deliberation in Latent Space via Differentiable Cache Augmentation
Dec 23, 2024



Techniques enabling large language models (LLMs) to "think more" by generating and attending to intermediate reasoning steps have shown promise in solving complex problems. However, the standard approaches generate sequences of discrete tokens immediately before responding, and so they can incur significant latency costs and be challenging to optimize. In this work, we demonstrate that a frozen LLM can be augmented with an offline coprocessor that operates on the model's key-value (kv) cache. This coprocessor augments the cache with a set of latent embeddings designed to improve the fidelity of subsequent decoding. We train this coprocessor using the language modeling loss from the decoder on standard pretraining data, while keeping the decoder itself frozen. This approach enables the model to learn, in an end-to-end differentiable fashion, how to distill additional computation into its kv-cache. Because the decoder remains unchanged, the coprocessor can operate offline and asynchronously, and the language model can function normally if the coprocessor is unavailable or if a given cache is deemed not to require extra computation. We show experimentally that when a cache is augmented, the decoder achieves lower perplexity on numerous subsequent tokens. Furthermore, even without any task-specific training, our experiments demonstrate that cache augmentation consistently reduces perplexity and improves performance across a range of reasoning-intensive tasks.
DiPaCo: Distributed Path Composition
Mar 15, 2024Progress in machine learning (ML) has been fueled by scaling neural network models. This scaling has been enabled by ever more heroic feats of engineering, necessary for accommodating ML approaches that require high bandwidth communication between devices working in parallel. In this work, we propose a co-designed modular architecture and training approach for ML models, dubbed DIstributed PAth COmposition (DiPaCo). During training, DiPaCo distributes computation by paths through a set of shared modules. Together with a Local-SGD inspired optimization (DiLoCo) that keeps modules in sync with drastically reduced communication, Our approach facilitates training across poorly connected and heterogeneous workers, with a design that ensures robustness to worker failures and preemptions. At inference time, only a single path needs to be executed for each input, without the need for any model compression. We consider this approach as a first prototype towards a new paradigm of large-scale learning, one that is less synchronous and more modular. Our experiments on the widely used C4 benchmark show that, for the same amount of training steps but less wall-clock time, DiPaCo exceeds the performance of a 1 billion-parameter dense transformer language model by choosing one of 256 possible paths, each with a size of 150 million parameters.
Asynchronous Local-SGD Training for Language Modeling
Jan 17, 2024



Local stochastic gradient descent (Local-SGD), also referred to as federated averaging, is an approach to distributed optimization where each device performs more than one SGD update per communication. This work presents an empirical study of {\it asynchronous} Local-SGD for training language models; that is, each worker updates the global parameters as soon as it has finished its SGD steps. We conduct a comprehensive investigation by examining how worker hardware heterogeneity, model size, number of workers, and optimizer could impact the learning performance. We find that with naive implementations, asynchronous Local-SGD takes more iterations to converge than its synchronous counterpart despite updating the (global) model parameters more frequently. We identify momentum acceleration on the global parameters when worker gradients are stale as a key challenge. We propose a novel method that utilizes a delayed Nesterov momentum update and adjusts the workers' local training steps based on their computation speed. This approach, evaluated with models up to 150M parameters on the C4 dataset, matches the performance of synchronous Local-SGD in terms of perplexity per update step, and significantly surpasses it in terms of wall clock time.
DiLoCo: Distributed Low-Communication Training of Language Models
Nov 14, 2023



Large language models (LLM) have become a critical component in many applications of machine learning. However, standard approaches to training LLM require a large number of tightly interconnected accelerators, with devices exchanging gradients and other intermediate states at each optimization step. While it is difficult to build and maintain a single computing cluster hosting many accelerators, it might be easier to find several computing clusters each hosting a smaller number of devices. In this work, we propose a distributed optimization algorithm, Distributed Low-Communication (DiLoCo), that enables training of language models on islands of devices that are poorly connected. The approach is a variant of federated averaging, where the number of inner steps is large, the inner optimizer is AdamW, and the outer optimizer is Nesterov momentum. On the widely used C4 dataset, we show that DiLoCo on 8 workers performs as well as fully synchronous optimization while communicating 500 times less. DiLoCo exhibits great robustness to the data distribution of each worker. It is also robust to resources becoming unavailable over time, and vice versa, it can seamlessly leverage resources that become available during training.
A Data Source for Reasoning Embodied Agents
Sep 14, 2023



Recent progress in using machine learning models for reasoning tasks has been driven by novel model architectures, large-scale pre-training protocols, and dedicated reasoning datasets for fine-tuning. In this work, to further pursue these advances, we introduce a new data generator for machine reasoning that integrates with an embodied agent. The generated data consists of templated text queries and answers, matched with world-states encoded into a database. The world-states are a result of both world dynamics and the actions of the agent. We show the results of several baseline models on instantiations of train sets. These include pre-trained language models fine-tuned on a text-formatted representation of the database, and graph-structured Transformers operating on a knowledge-graph representation of the database. We find that these models can answer some questions about the world-state, but struggle with others. These results hint at new research directions in designing neural reasoning models and database representations. Code to generate the data will be released at github.com/facebookresearch/neuralmemory
Transforming Human-Centered AI Collaboration: Redefining Embodied Agents Capabilities through Interactive Grounded Language Instructions
May 18, 2023



Human intelligence's adaptability is remarkable, allowing us to adjust to new tasks and multi-modal environments swiftly. This skill is evident from a young age as we acquire new abilities and solve problems by imitating others or following natural language instructions. The research community is actively pursuing the development of interactive "embodied agents" that can engage in natural conversations with humans and assist them with real-world tasks. These agents must possess the ability to promptly request feedback in case communication breaks down or instructions are unclear. Additionally, they must demonstrate proficiency in learning new vocabulary specific to a given domain. In this paper, we made the following contributions: (1) a crowd-sourcing tool for collecting grounded language instructions; (2) the largest dataset of grounded language instructions; and (3) several state-of-the-art baselines. These contributions are suitable as a foundation for further research.
Learning to Reason and Memorize with Self-Notes
May 01, 2023



Large language models have been shown to struggle with limited context memory and multi-step reasoning. We propose a simple method for solving both of these problems by allowing the model to take Self-Notes. Unlike recent scratchpad approaches, the model can deviate from the input context at any time to explicitly think. This allows the model to recall information and perform reasoning on the fly as it reads the context, thus extending its memory and enabling multi-step reasoning. Our experiments on multiple tasks demonstrate that our method can successfully generalize to longer and more complicated instances from their training setup by taking Self-Notes at inference time.
Multi-Party Chat: Conversational Agents in Group Settings with Humans and Models
Apr 26, 2023



Current dialogue research primarily studies pairwise (two-party) conversations, and does not address the everyday setting where more than two speakers converse together. In this work, we both collect and evaluate multi-party conversations to study this more general case. We use the LIGHT environment to construct grounded conversations, where each participant has an assigned character to role-play. We thus evaluate the ability of language models to act as one or more characters in such conversations. Models require two skills that pairwise-trained models appear to lack: (1) being able to decide when to talk; (2) producing coherent utterances grounded on multiple characters. We compare models trained on our new dataset to existing pairwise-trained dialogue models, as well as large language models with few-shot prompting. We find that our new dataset, MultiLIGHT, which we will publicly release, can help bring significant improvements in the group setting.