 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Shortcut-aware Video-QA Benchmark for Physical Understanding via Minimal Video Pairs
Jun 11, 2025



Existing benchmarks for assessing the spatio-temporal understanding and reasoning abilities of video language models are susceptible to score inflation due to the presence of shortcut solutions based on superficial visual or textual cues. This paper mitigates the challenges in accurately assessing model performance by introducing the Minimal Video Pairs (MVP) benchmark, a simple shortcut-aware video QA benchmark for assessing the physical understanding of video language models. The benchmark is comprised of 55K high-quality multiple-choice video QA examples focusing on physical world understanding. Examples are curated from nine video data sources, spanning first-person egocentric and exocentric videos, robotic interaction data, and cognitive science intuitive physics benchmarks. To mitigate shortcut solutions that rely on superficial visual or textual cues and biases, each sample in MVP has a minimal-change pair -- a visually similar video accompanied by an identical question but an opposing answer. To answer a question correctly, a model must provide correct answers for both examples in the minimal-change pair; as such, models that solely rely on visual or textual biases would achieve below random performance. Human performance on MVP is 92.9\%, while the best open-source state-of-the-art video-language model achieves 40.2\% compared to random performance at 25\%.
Seeing Voices: Generating A-Roll Video from Audio with Mirage
Jun 09, 2025



From professional filmmaking to user-generated content, creators and consumers have long recognized that the power of video depends on the harmonious integration of what we hear (the video's audio track) with what we see (the video's image sequence). Current approaches to video generation either ignore sound to focus on general-purpose but silent image sequence generation or address both visual and audio elements but focus on restricted application domains such as re-dubbing. We introduce Mirage, an audio-to-video foundation model that excels at generating realistic, expressive output imagery from scratch given an audio input. When integrated with existing methods for speech synthesis (text-to-speech, or TTS), Mirage results in compelling multimodal video. When trained on audio-video footage of people talking (A-roll) and conditioned on audio containing speech, Mirage generates video of people delivering a believable interpretation of the performance implicit in input audio. Our central technical contribution is a unified method for training self-attention-based audio-to-video generation models, either from scratch or given existing weights. This methodology allows Mirage to retain generality as an approach to audio-to-video generation while producing outputs of superior subjective quality to methods that incorporate audio-specific architectures or loss components specific to people, speech, or details of how images or audio are captured. We encourage readers to watch and listen to the results of Mirage for themselves (see paper and comments for links).
VEDIT: Latent Prediction Architecture For Procedural Video Representation Learning
Oct 04, 2024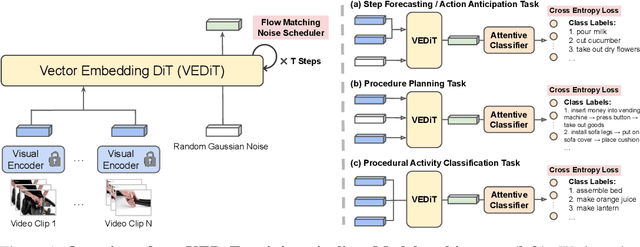
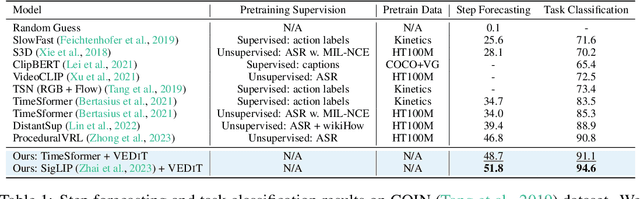
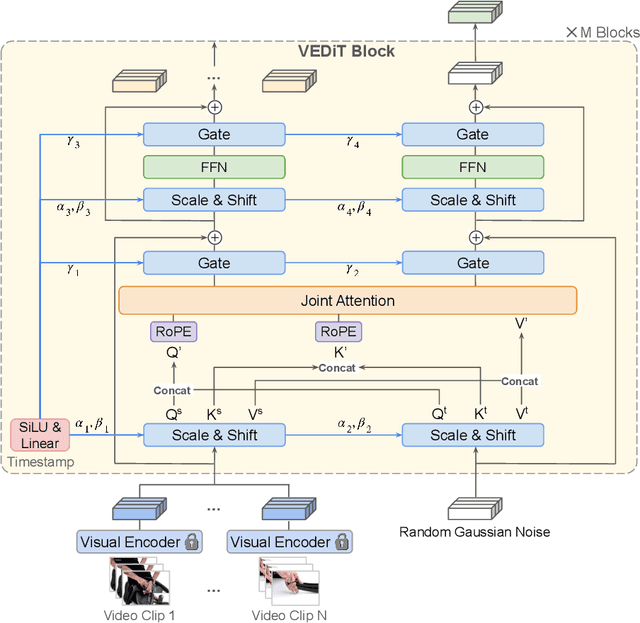
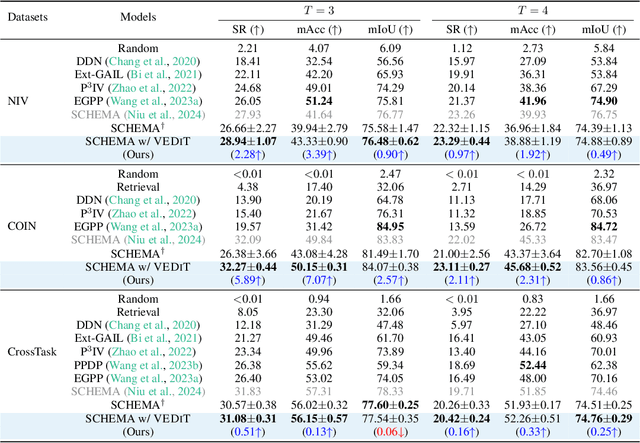
Procedural video representation learning is an active research area where the objective is to learn an agent which can anticipate and forecast the future given the present video input, typically in conjunction with textual annotations. Prior works often rely on large-scale pretraining of visual encoders and prediction models with language supervision. However, the necessity and effectiveness of extending compute intensive pretraining to learn video clip sequences with noisy text supervision have not yet been fully validated by previous works. In this work, we show that a strong off-the-shelf frozen pretrained visual encoder, along with a well designed prediction model, can achieve state-of-the-art (SoTA) performance in forecasting and procedural planning without the need for pretraining the prediction model, nor requiring additional supervision from language or ASR. Instead of learning representations from pixel space, our method utilizes the latent embedding space of publicly available vision encoders. By conditioning on frozen clip-level embeddings from observed steps to predict the actions of unseen steps, our prediction model is able to learn robust representations for forecasting through iterative denoising - leveraging the recent advances in diffusion transformers (Peebles & Xie, 2023). Empirical studies over a total of five procedural learning tasks across four datasets (NIV, CrossTask, COIN and Ego4D-v2) show that our model advances the strong baselines in long-horizon action anticipation (+2.6% in Verb ED@20, +3.1% in Noun ED@20), and significantly improves the SoTA in step forecasting (+5.0%), task classification (+3.8%), and procedure planning tasks (up to +2.28% in success rate, +3.39% in mAcc, and +0.90% in mIoU).
Chain-of-Verification Reduces Hallucination in Large Language Models
Sep 25, 2023



Generation of plausible yet incorrect factual information, termed hallucination, is an unsolved issue in large language models. We study the ability of language models to deliberate on the responses they give in order to correct their mistakes. We develop the Chain-of-Verification (CoVe) method whereby the model first (i) drafts an initial response; then (ii) plans verification questions to fact-check its draft; (iii) answers those questions independently so the answers are not biased by other responses; and (iv) generates its final verified response. In experiments, we show CoVe decreases hallucinations across a variety of tasks, from list-based questions from Wikidata, closed book MultiSpanQA and longform text generation.
The HCI Aspects of Public Deployment of Research Chatbots: A User Study, Design Recommendations, and Open Challenges
Jun 07, 2023
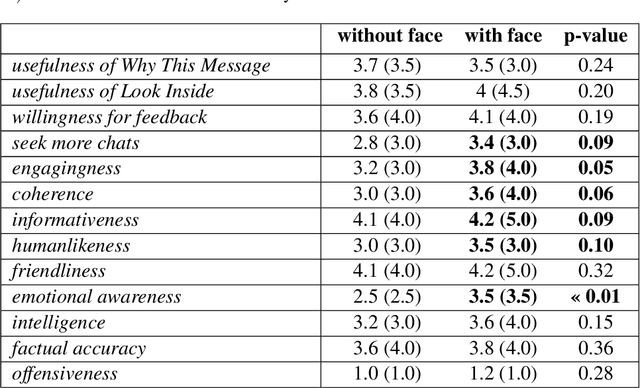
Publicly deploying research chatbots is a nuanced topic involving necessary risk-benefit analyses. While there have recently been frequent discussions on whether it is responsible to deploy such models, there has been far less focus on the interaction paradigms and design approaches that the resulting interfaces should adopt, in order to achieve their goals more effectively. We aim to pose, ground, and attempt to answer HCI questions involved in this scope, by reporting on a mixed-methods user study conducted on a recent research chatbot. We find that abstract anthropomorphic representation for the agent has a significant effect on user's perception, that offering AI explainability may have an impact on feedback rates, and that two (diegetic and extradiegetic) levels of the chat experience should be intentionally designed. We offer design recommendations and areas of further focus for the research community.
Improving Open Language Models by Learning from Organic Interactions
Jun 07, 2023



We present BlenderBot 3x, an update on the conversational model BlenderBot 3, which is now trained using organic conversation and feedback data from participating users of the system in order to improve both its skills and safety. We are publicly releasing the participating de-identified interaction data for use by the research community, in order to spur further progress. Training models with organic data is challenging because interactions with people "in the wild" include both high quality conversations and feedback, as well as adversarial and toxic behavior. We study techniques that enable learning from helpful teachers while avoiding learning from people who are trying to trick the model into unhelpful or toxic responses. BlenderBot 3x is both preferred in conversation to BlenderBot 3, and is shown to produce safer responses in challenging situations. While our current models are still far from perfect, we believe further improvement can be achieved by continued use of the techniques explored in this work.
Multi-Party Chat: Conversational Agents in Group Settings with Humans and Models
Apr 26, 2023



Current dialogue research primarily studies pairwise (two-party) conversations, and does not address the everyday setting where more than two speakers converse together. In this work, we both collect and evaluate multi-party conversations to study this more general case. We use the LIGHT environment to construct grounded conversations, where each participant has an assigned character to role-play. We thus evaluate the ability of language models to act as one or more characters in such conversations. Models require two skills that pairwise-trained models appear to lack: (1) being able to decide when to talk; (2) producing coherent utterances grounded on multiple characters. We compare models trained on our new dataset to existing pairwise-trained dialogue models, as well as large language models with few-shot prompting. We find that our new dataset, MultiLIGHT, which we will publicly release, can help bring significant improvements in the group setting.
Infusing Commonsense World Models with Graph Knowledge
Jan 13, 2023While language models have become more capable of producing compelling language, we find there are still gaps in maintaining consistency, especially when describing events in a dynamically changing world. We study the setting of generating narratives in an open world text adventure game, where a graph representation of the underlying game state can be used to train models that consume and output both grounded graph representations and natural language descriptions and actions. We build a large set of tasks by combining crowdsourced and simulated gameplays with a novel dataset of complex actions in order to to construct such models. We find it is possible to improve the consistency of action narration models by training on graph contexts and targets, even if graphs are not present at test time. This is shown both in automatic metrics and human evaluations. We plan to release our code, the new set of tasks, and best performing models.
Learning New Skills after Deployment: Improving open-domain internet-driven dialogue with human feedback
Aug 16, 2022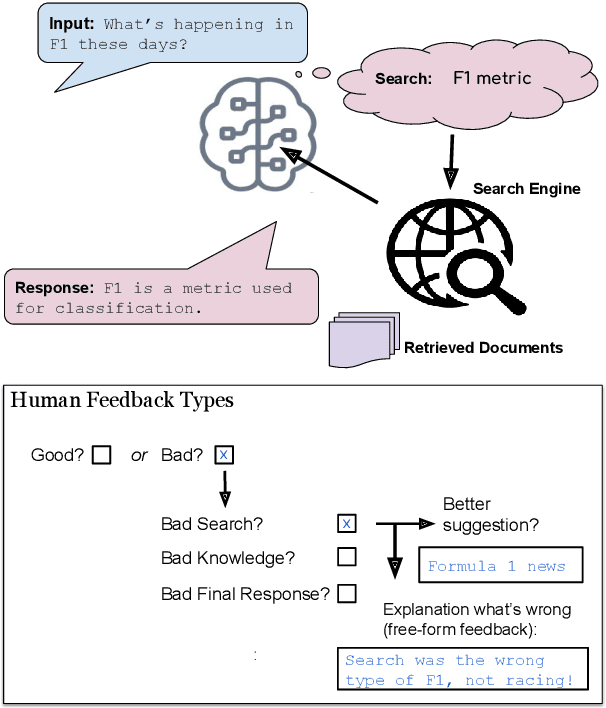
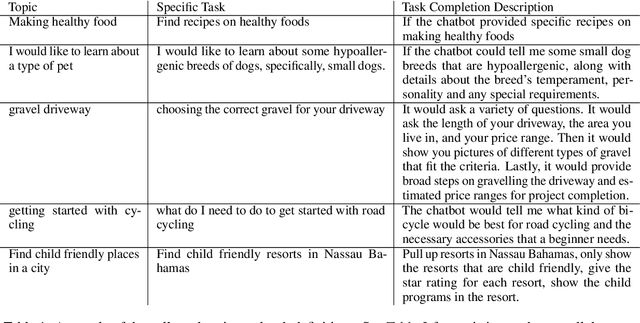
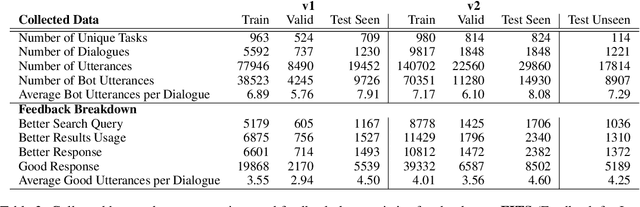
Frozen models trained to mimic static datasets can never improve their performance. Models that can employ internet-retrieval for up-to-date information and obtain feedback from humans during deployment provide the promise of both adapting to new information, and improving their performance. In this work we study how to improve internet-driven conversational skills in such a learning framework. We collect deployment data, which we make publicly available, of human interactions, and collect various types of human feedback -- including binary quality measurements, free-form text feedback, and fine-grained reasons for failure. We then study various algorithms for improving from such feedback, including standard supervised learning, rejection sampling, model-guiding and reward-based learning, in order to make recommendations on which type of feedback and algorithms work best. We find the recently introduced Director model (Arora et al., '22) shows significant improvements over other existing approaches.
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
Aug 10, 2022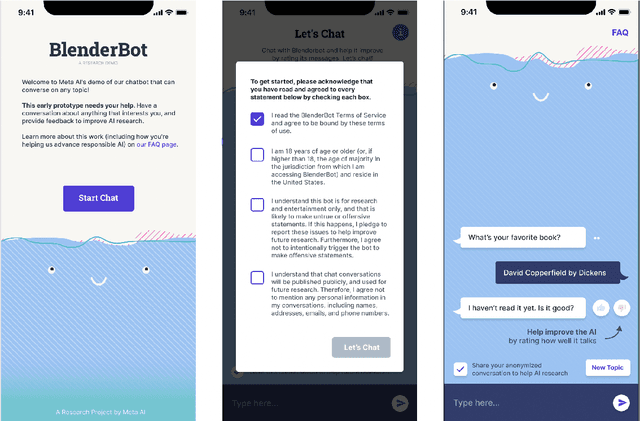
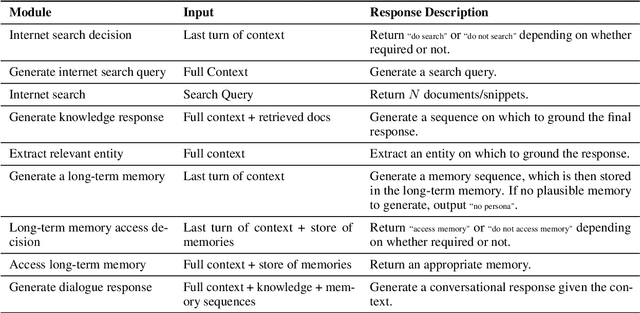
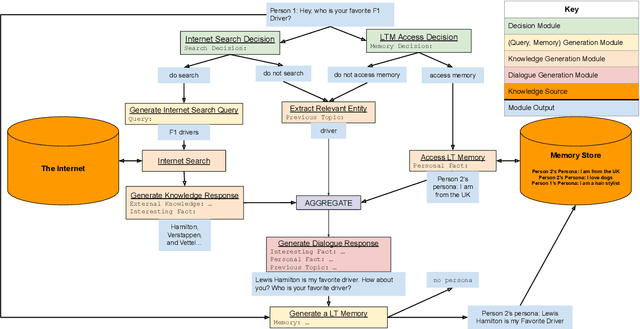
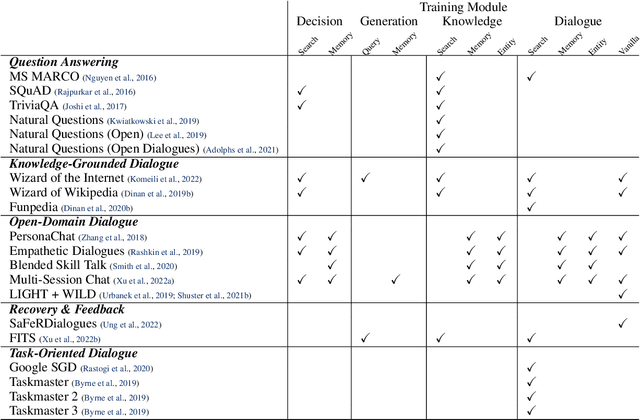
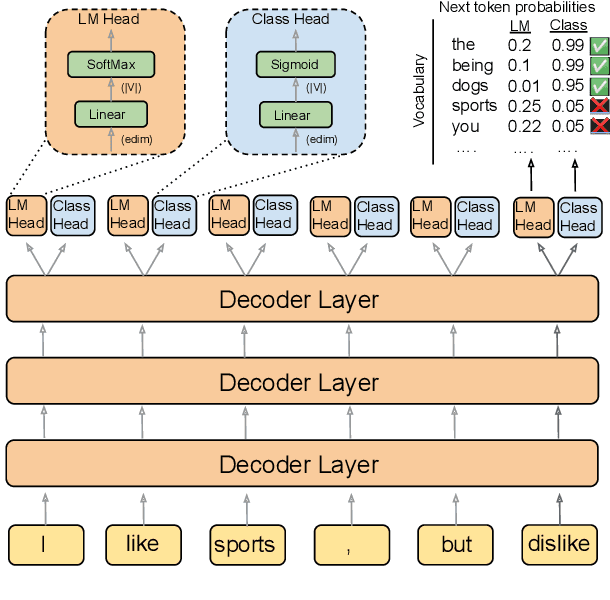
We present BlenderBot 3, a 175B parameter dialogue model capable of open-domain conversation with access to the internet and a long-term memory, and having been trained on a large number of user defined tasks. We release both the model weights and code, and have also deployed the model on a public web page to interact with organic users. This technical report describes how the model was built (architecture, model and training scheme), and details of its deployment, including safety mechanisms. Human evaluations show its superiority to existing open-domain dialogue agents, including its predecessors (Roller et al., 2021; Komeili et al., 2022). Finally, we detail our plan for continual learning using the data collected from deployment, which will also be publicly released. The goal of this research program is thus to enable the community to study ever-improving responsible agents that learn through interaction.