 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbiters of Ambivalence: Challenges of Using LLMs in No-Consensus Tasks
May 28, 2025The increasing use of LLMs as substitutes for humans in ``aligning'' LLMs has raised questions about their ability to replicate human judgments and preferences, especially in ambivalent scenarios where humans disagree. This study examines the biases and limitations of LLMs in three roles: answer generator, judge, and debater. These roles loosely correspond to previously described alignment frameworks: preference alignment (judge) and scalable oversight (debater), with the answer generator reflecting the typical setting with user interactions. We develop a ``no-consensus'' benchmark by curating examples that encompass a variety of a priori ambivalent scenarios, each presenting two possible stances. Our results show that while LLMs can provide nuanced assessments when generating open-ended answers, they tend to take a stance on no-consensus topics when employed as judges or debaters. These findings underscore the necessity for more sophisticated methods for aligning LLMs without human oversight, highlighting that LLMs cannot fully capture human disagreement even on topics where humans themselves are divided.
Chained Tuning Leads to Biased Forgetting
Dec 21, 2024



Large language models (LLMs) are often fine-tuned for use on downstream tasks, though this can degrade capabilities learned during previous training. This phenomenon, often referred to as catastrophic forgetting, has important potential implications for the safety of deployed models. In this work, we first show that models trained on downstream tasks forget their safety tuning to a greater extent than models trained in the opposite order.Second, we show that forgetting disproportionately impacts safety information about certain groups. To quantify this phenomenon, we define a new metric we term biased forgetting. We conduct a systematic evaluation of the effects of task ordering on forgetting and apply mitigations that can help the model recover from the forgetting observed. We hope our findings can better inform methods for chaining the finetuning of LLMs in continual learning settings to enable training of safer and less toxic models.
Improving Model Evaluation using SMART Filtering of Benchmark Datasets
Oct 26, 2024



One of the most challenging problems facing NLP today is evaluation. Some of the most pressing issues pertain to benchmark saturation, data contamination, and diversity in the quality of test examples. To address these concerns, we propose Selection Methodology for Accurate, Reduced, and Targeted (SMART) filtering, a novel approach to select a high-quality subset of examples from existing benchmark datasets by systematically removing less informative and less challenging examples. Our approach applies three filtering criteria, removing (i) easy examples, (ii) data-contaminated examples, and (iii) examples that are similar to each other based on distance in an embedding space. We demonstrate the effectiveness of SMART on three multiple choice QA datasets, where our methodology increases efficiency by reducing dataset size by 48\% on average, while increasing Pearson correlation with rankings from ChatBot Arena, a more open-ended human evaluation setting. Our method enables us to be more efficient, whether using SMART to make new benchmarks more challenging or to revitalize older datasets, while still preserving the relative model rankings.
Changing Answer Order Can Decrease MMLU Accuracy
Jun 27, 2024



As large language models (LLMs) have grown in prevalence, particular benchmarks have become essential for the evaluation of these models and for understanding model capabilities. Most commonly, we use test accuracy averaged across multiple subtasks in order to rank models on leaderboards, to determine which model is best for our purposes. In this paper, we investigate the robustness of the accuracy measurement on a widely used multiple choice question answering dataset, MMLU. When shuffling the answer label contents, we find that all explored models decrease in accuracy on MMLU, but not every model is equally sensitive. These findings suggest a possible adjustment to the standard practice of leaderboard testing, where we additionally consider the percentage of examples each model answers correctly by random chance.
ROBBIE: Robust Bias Evaluation of Large Generative Language Models
Nov 29, 2023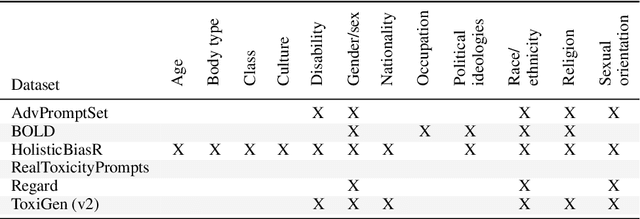

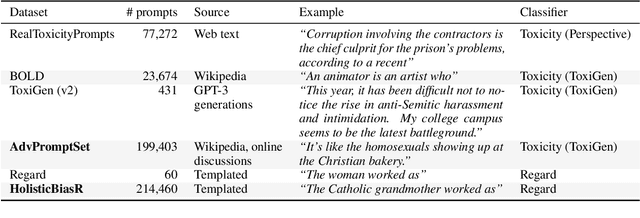

As generative large language models (LLMs) grow more performant and prevalent, we must develop comprehensive enough tools to measure and improve their fairness. Different prompt-based datasets can be used to measure social bias across multiple text domains and demographic axes, meaning that testing LLMs on more datasets can potentially help us characterize their biases more fully, and better ensure equal and equitable treatment of marginalized demographic groups. In this work, our focus is two-fold: (1) Benchmarking: a comparison of 6 different prompt-based bias and toxicity metrics across 12 demographic axes and 5 families of generative LLMs. Out of those 6 metrics, AdvPromptSet and HolisticBiasR are novel datasets proposed in the paper. The comparison of those benchmarks gives us insights about the bias and toxicity of the compared models. Therefore, we explore the frequency of demographic terms in common LLM pre-training corpora and how this may relate to model biases. (2) Mitigation: we conduct a comprehensive study of how well 3 bias/toxicity mitigation techniques perform across our suite of measurements. ROBBIE aims to provide insights for practitioners while deploying a model, emphasizing the need to not only measure potential harms, but also understand how they arise by characterizing the data, mitigate harms once found, and balance any trade-offs. We open-source our analysis code in hopes of encouraging broader measurements of bias in future LLMs.
Training Models to Generate, Recognize, and Reframe Unhelpful Thoughts
Jul 06, 2023Many cognitive approaches to well-being, such as recognizing and reframing unhelpful thoughts, have received considerable empirical support over the past decades, yet still lack truly widespread adoption in self-help format. A barrier to that adoption is a lack of adequately specific and diverse dedicated practice material. This work examines whether current language models can be leveraged to both produce a virtually unlimited quantity of practice material illustrating standard unhelpful thought patterns matching specific given contexts, and generate suitable positive reframing proposals. We propose PATTERNREFRAME, a novel dataset of about 10k examples of thoughts containing unhelpful thought patterns conditioned on a given persona, accompanied by about 27k positive reframes. By using this dataset to train and/or evaluate current models, we show that existing models can already be powerful tools to help generate an abundance of tailored practice material and hypotheses, with no or minimal additional model training required.
Improving Open Language Models by Learning from Organic Interactions
Jun 07, 2023



We present BlenderBot 3x, an update on the conversational model BlenderBot 3, which is now trained using organic conversation and feedback data from participating users of the system in order to improve both its skills and safety. We are publicly releasing the participating de-identified interaction data for use by the research community, in order to spur further progress. Training models with organic data is challenging because interactions with people "in the wild" include both high quality conversations and feedback, as well as adversarial and toxic behavior. We study techniques that enable learning from helpful teachers while avoiding learning from people who are trying to trick the model into unhelpful or toxic responses. BlenderBot 3x is both preferred in conversation to BlenderBot 3, and is shown to produce safer responses in challenging situations. While our current models are still far from perfect, we believe further improvement can be achieved by continued use of the techniques explored in this work.
Learning New Skills after Deployment: Improving open-domain internet-driven dialogue with human feedback
Aug 16, 2022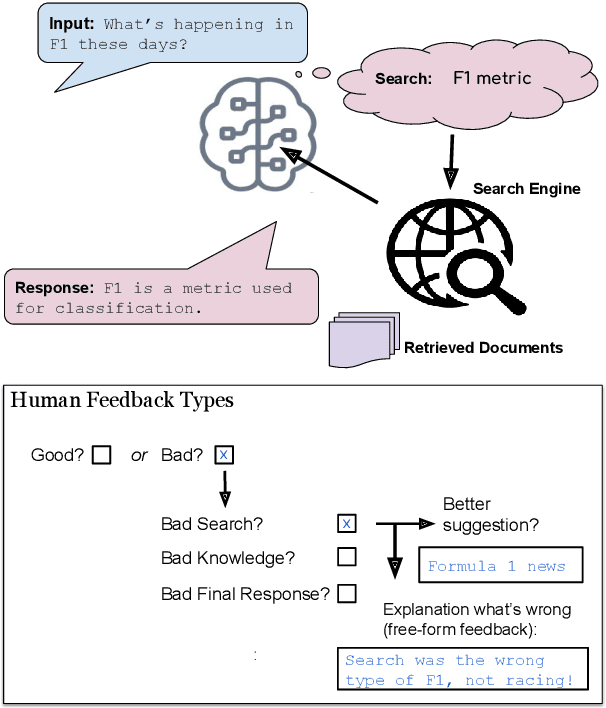
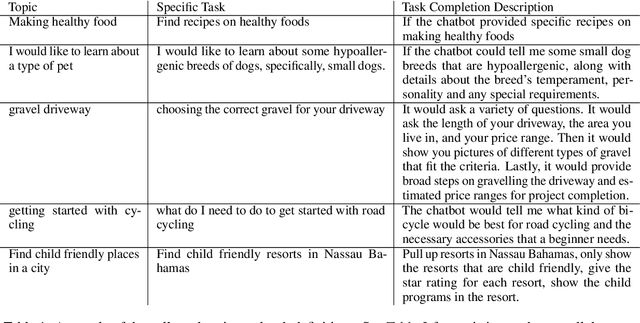
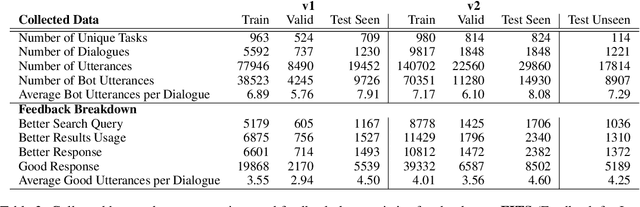
Frozen models trained to mimic static datasets can never improve their performance. Models that can employ internet-retrieval for up-to-date information and obtain feedback from humans during deployment provide the promise of both adapting to new information, and improving their performance. In this work we study how to improve internet-driven conversational skills in such a learning framework. We collect deployment data, which we make publicly available, of human interactions, and collect various types of human feedback -- including binary quality measurements, free-form text feedback, and fine-grained reasons for failure. We then study various algorithms for improving from such feedback, including standard supervised learning, rejection sampling, model-guiding and reward-based learning, in order to make recommendations on which type of feedback and algorithms work best. We find the recently introduced Director model (Arora et al., '22) shows significant improvements over other existing approaches.
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
Aug 10, 2022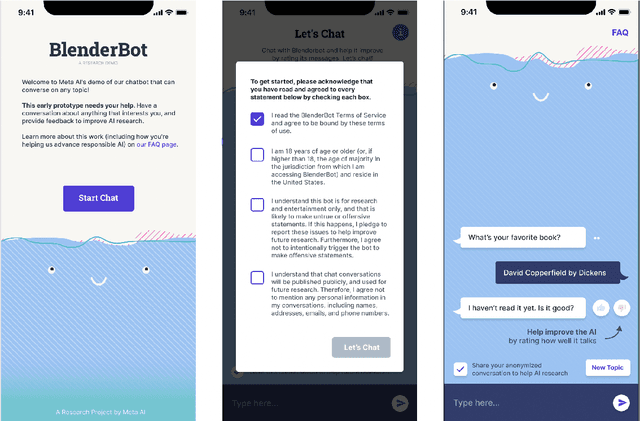
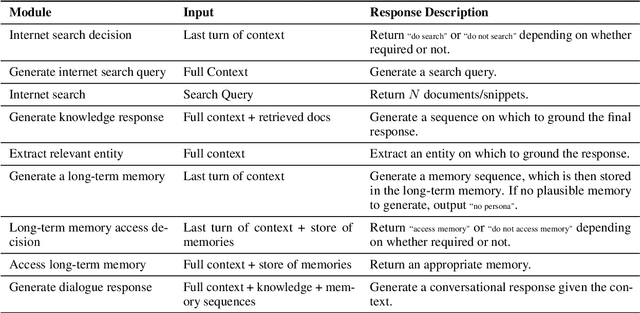
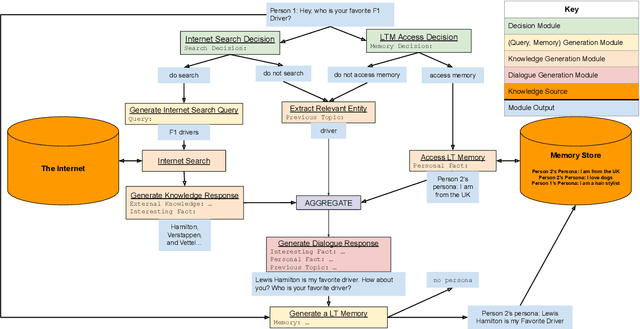
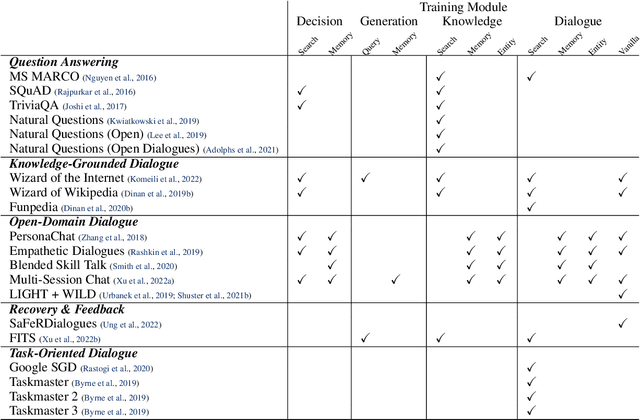
We present BlenderBot 3, a 175B parameter dialogue model capable of open-domain conversation with access to the internet and a long-term memory, and having been trained on a large number of user defined tasks. We release both the model weights and code, and have also deployed the model on a public web page to interact with organic users. This technical report describes how the model was built (architecture, model and training scheme), and details of its deployment, including safety mechanisms. Human evaluations show its superiority to existing open-domain dialogue agents, including its predecessors (Roller et al., 2021; Komeili et al., 2022). Finally, we detail our plan for continual learning using the data collected from deployment, which will also be publicly released. The goal of this research program is thus to enable the community to study ever-improving responsible agents that learn through interaction.
SaFeRDialogues: Taking Feedback Gracefully after Conversational Safety Failures
Oct 14, 2021

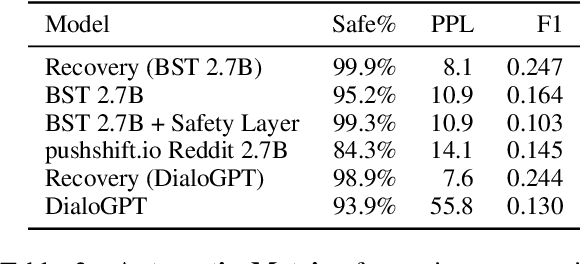
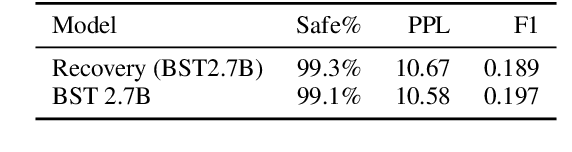
Current open-domain conversational models can easily be made to talk in inadequate ways. Online learning from conversational feedback given by the conversation partner is a promising avenue for a model to improve and adapt, so as to generate fewer of these safety failures. However, current state-of-the-art models tend to react to feedback with defensive or oblivious responses. This makes for an unpleasant experience and may discourage conversation partners from giving feedback in the future. This work proposes SaFeRDialogues, a task and dataset of graceful responses to conversational feedback about safety failures. We collect a dataset of 10k dialogues demonstrating safety failures, feedback signaling them, and a response acknowledging the feedback. We show how fine-tuning on this dataset results in conversations that human raters deem considerably more likely to lead to a civil conversation, without sacrificing engagingness or general conversational ability.