 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
The HCI Aspects of Public Deployment of Research Chatbots: A User Study, Design Recommendations, and Open Challenges
Jun 07, 2023
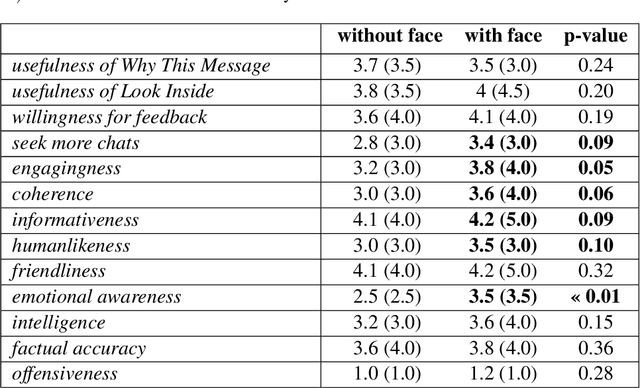
Publicly deploying research chatbots is a nuanced topic involving necessary risk-benefit analyses. While there have recently been frequent discussions on whether it is responsible to deploy such models, there has been far less focus on the interaction paradigms and design approaches that the resulting interfaces should adopt, in order to achieve their goals more effectively. We aim to pose, ground, and attempt to answer HCI questions involved in this scope, by reporting on a mixed-methods user study conducted on a recent research chatbot. We find that abstract anthropomorphic representation for the agent has a significant effect on user's perception, that offering AI explainability may have an impact on feedback rates, and that two (diegetic and extradiegetic) levels of the chat experience should be intentionally designed. We offer design recommendations and areas of further focus for the research community.
A Theory on Adam Instability in Large-Scale Machine Learning
Apr 25, 2023



We present a theory for the previously unexplained divergent behavior noticed in the training of large language models. We argue that the phenomenon is an artifact of the dominant optimization algorithm used for training, called Adam. We observe that Adam can enter a state in which the parameter update vector has a relatively large norm and is essentially uncorrelated with the direction of descent on the training loss landscape, leading to divergence. This artifact is more likely to be observed in the training of a deep model with a large batch size, which is the typical setting of large-scale language model training. To argue the theory, we present observations from the training runs of the language models of different scales: 7 billion, 30 billion, 65 billion, and 546 billion parameters.
ROSCOE: A Suite of Metrics for Scoring Step-by-Step Reasoning
Dec 15, 2022



Large language models show improved downstream task performance when prompted to generate step-by-step reasoning to justify their final answers. These reasoning steps greatly improve model interpretability and verification, but objectively studying their correctness (independent of the final answer) is difficult without reliable methods for automatic evaluation. We simply do not know how often the stated reasoning steps actually support the final end task predictions. In this work, we present ROSCOE, a suite of interpretable, unsupervised automatic scores that improve and extend previous text generation evaluation metrics. To evaluate ROSCOE against baseline metrics, we design a typology of reasoning errors and collect synthetic and human evaluation scores on commonly used reasoning datasets. In contrast with existing metrics, ROSCOE can measure semantic consistency, logicality, informativeness, fluency, and factuality - among other traits - by leveraging properties of step-by-step rationales. We empirically verify the strength of our metrics on five human annotated and six programmatically perturbed diagnostics datasets - covering a diverse set of tasks that require reasoning skills and show that ROSCOE can consistently outperform baseline metrics.
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
Aug 10, 2022
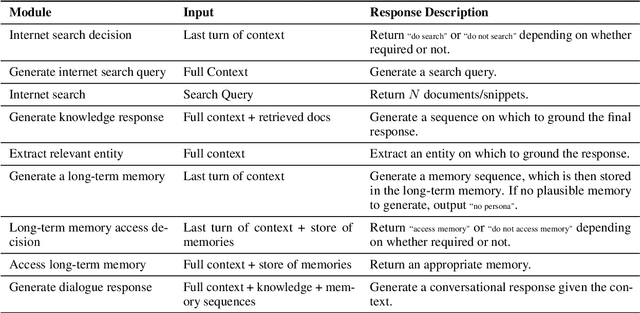
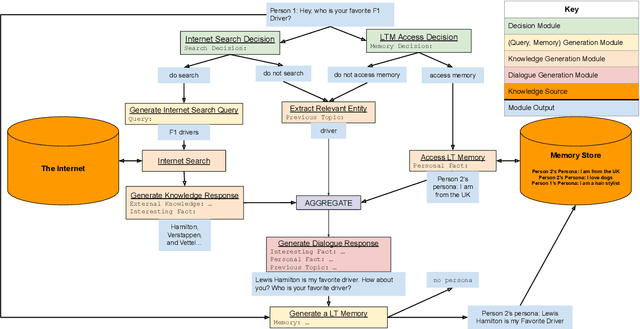
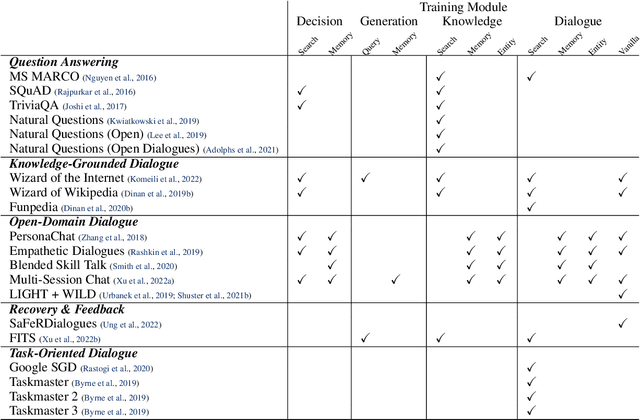
We present BlenderBot 3, a 175B parameter dialogue model capable of open-domain conversation with access to the internet and a long-term memory, and having been trained on a large number of user defined tasks. We release both the model weights and code, and have also deployed the model on a public web page to interact with organic users. This technical report describes how the model was built (architecture, model and training scheme), and details of its deployment, including safety mechanisms. Human evaluations show its superiority to existing open-domain dialogue agents, including its predecessors (Roller et al., 2021; Komeili et al., 2022). Finally, we detail our plan for continual learning using the data collected from deployment, which will also be publicly released. The goal of this research program is thus to enable the community to study ever-improving responsible agents that learn through interaction.
OPT: Open Pre-trained Transformer Language Models
May 05, 2022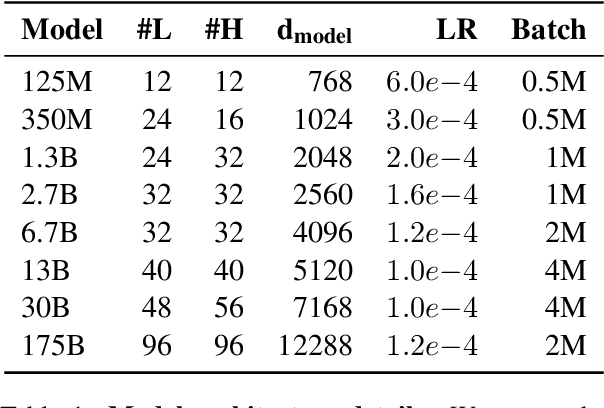
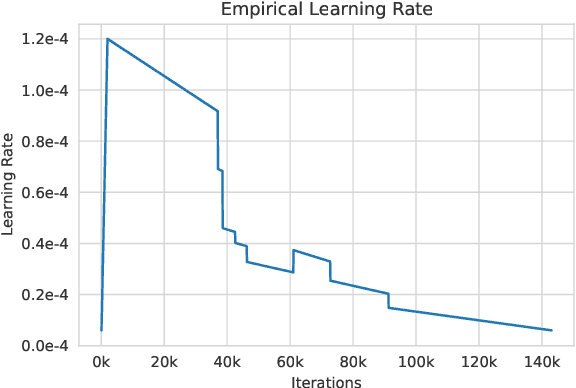
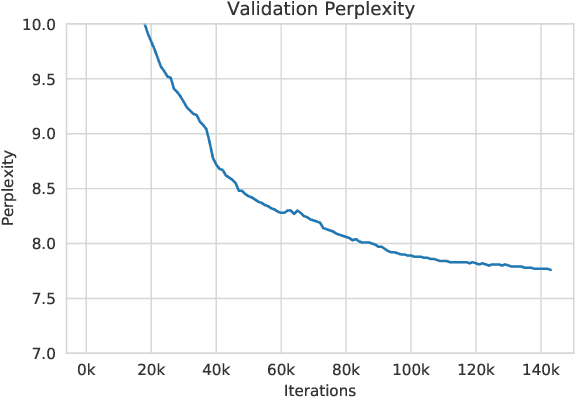
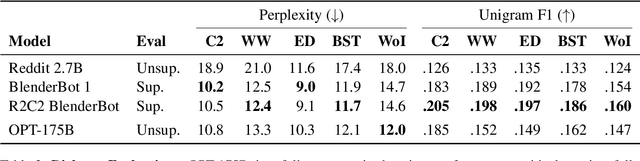
Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.
Teaching Models new APIs: Domain-Agnostic Simulators for Task Oriented Dialogue
Oct 13, 2021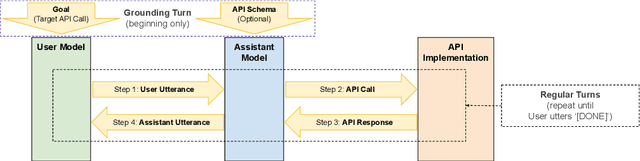
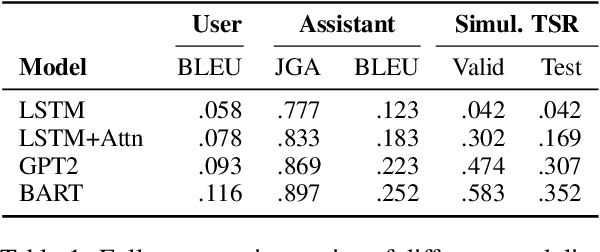
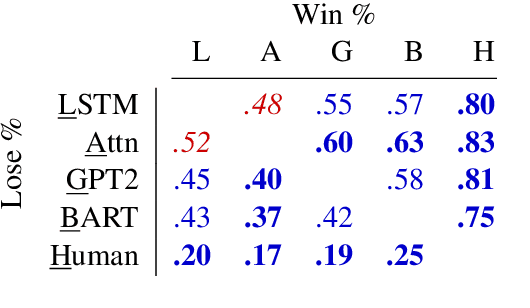
We demonstrate that large language models are able to simulate Task Oriented Dialogues in novel domains, provided only with an API implementation and a list of goals. We show these simulations can formulate online, automatic metrics that correlate well with human evaluations. Furthermore, by checking for whether the User's goals are met, we can use simulation to repeatedly generate training data and improve the quality of simulations themselves. With no human intervention or domain-specific training data, our simulations bootstrap end-to-end models which achieve a 37\% error reduction in previously unseen domains. By including as few as 32 domain-specific conversations, bootstrapped models can match the performance of a fully-supervised model with $10\times$ more data. To our knowledge, this is the first time simulations have been shown to be effective at bootstrapping models without explicitly requiring any domain-specific training data, rule-engineering, or humans-in-the-loop.
Retrieval Augmentation Reduces Hallucination in Conversation
Apr 15, 2021
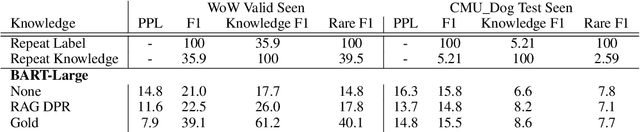
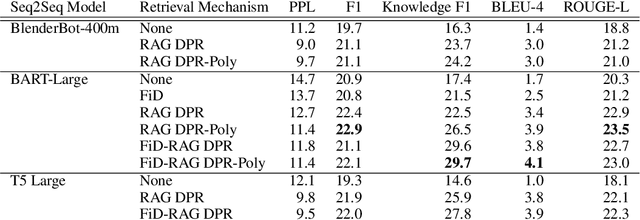
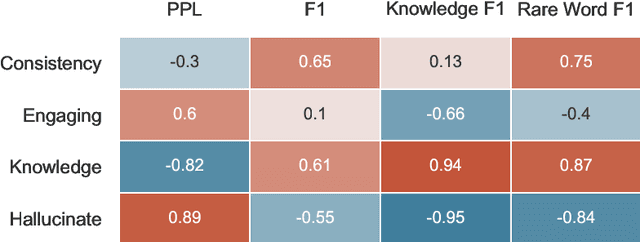
Despite showing increasingly human-like conversational abilities, state-of-the-art dialogue models often suffer from factual incorrectness and hallucination of knowledge (Roller et al., 2020). In this work we explore the use of neural-retrieval-in-the-loop architectures - recently shown to be effective in open-domain QA (Lewis et al., 2020b; Izacard and Grave, 2020) - for knowledge-grounded dialogue, a task that is arguably more challenging as it requires querying based on complex multi-turn dialogue context and generating conversationally coherent responses. We study various types of architectures with multiple components - retrievers, rankers, and encoder-decoders - with the goal of maximizing knowledgeability while retaining conversational ability. We demonstrate that our best models obtain state-of-the-art performance on two knowledge-grounded conversational tasks. The models exhibit open-domain conversational capabilities, generalize effectively to scenarios not within the training data, and, as verified by human evaluations, substantially reduce the well-known problem of knowledge hallucination in state-of-the-art chatbots.
Parallel computation using active self-assembly
Sep 05, 2014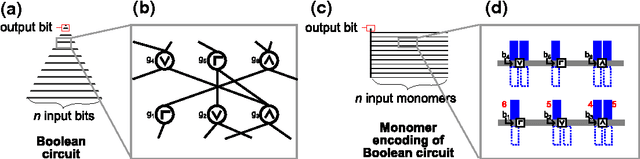
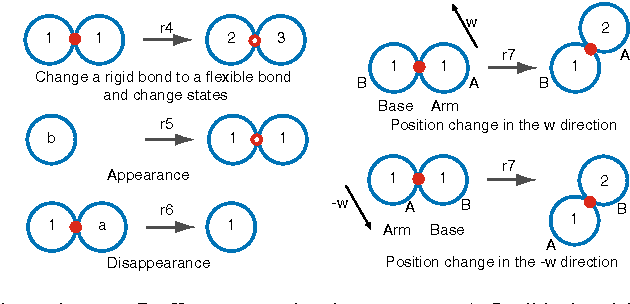

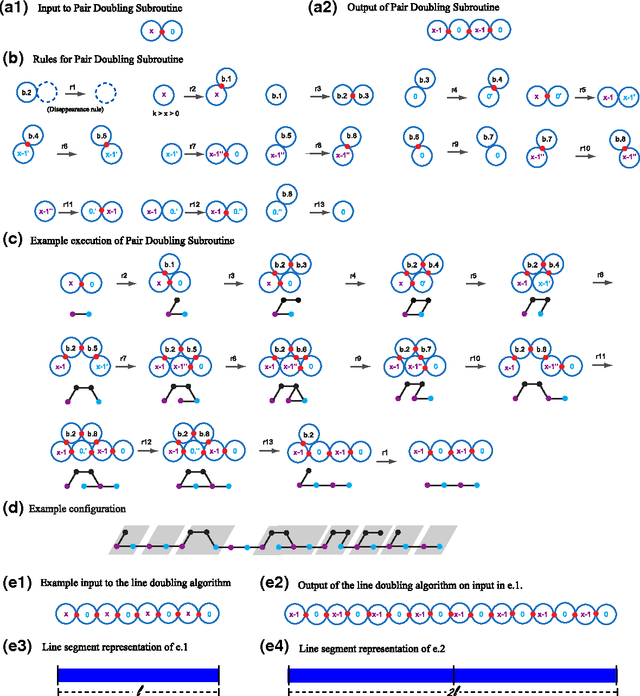
We study the computational complexity of the recently proposed nubot model of molecular-scale self-assembly. The model generalises asynchronous cellular automata to have non-local movement where large assemblies of molecules can be pushed and pulled around, analogous to millions of molecular motors in animal muscle effecting the rapid movement of macroscale arms and legs. We show that the nubot model is capable of simulating Boolean circuits of polylogarithmic depth and polynomial size, in only polylogarithmic expected time. In computational complexity terms, we show that any problem from the complexity class NC is solvable in polylogarithmic expected time and polynomial workspace using nubots. Along the way, we give fast parallel nubot algorithms for a number of problems including line growth, sorting, Boolean matrix multiplication and space-bounded Turing machine simulation, all using a constant number of nubot states (monomer types). Circuit depth is a well-studied notion of parallel time, and our result implies that the nubot model is a highly parallel model of computation in a formal sense. Asynchronous cellular automata are not capable of this parallelism, and our result shows that adding a rigid-body movement primitive to such a model, to get the nubot model, drastically increases parallel processing abilities.