 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProduction Machine Learning Pipelines: Empirical Analysis and Optimization Opportunities
Mar 30, 2021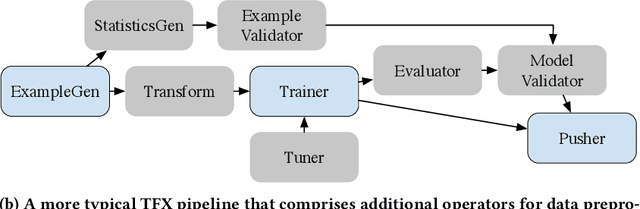
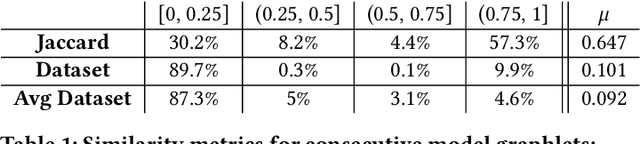
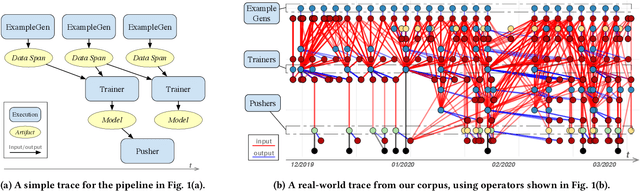
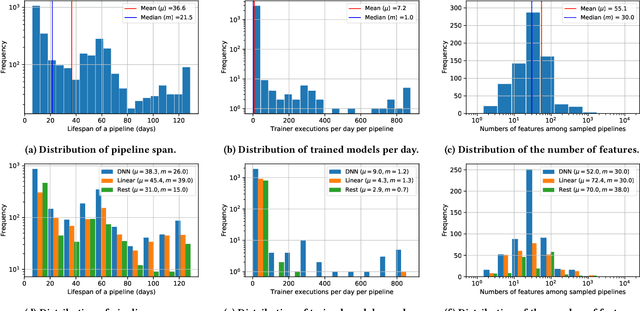
Machine learning (ML) is now commonplace, powering data-driven applications in various organizations. Unlike the traditional perception of ML in research, ML production pipelines are complex, with many interlocking analytical components beyond training, whose sub-parts are often run multiple times on overlapping subsets of data. However, there is a lack of quantitative evidence regarding the lifespan, architecture, frequency, and complexity of these pipelines to understand how data management research can be used to make them more efficient, effective, robust, and reproducible. To that end, we analyze the provenance graphs of 3000 production ML pipelines at Google, comprising over 450,000 models trained, spanning a period of over four months, in an effort to understand the complexity and challenges underlying production ML. Our analysis reveals the characteristics, components, and topologies of typical industry-strength ML pipelines at various granularities. Along the way, we introduce a specialized data model for representing and reasoning about repeatedly run components in these ML pipelines, which we call model graphlets. We identify several rich opportunities for optimization, leveraging traditional data management ideas. We show how targeting even one of these opportunities, i.e., identifying and pruning wasted computation that does not translate to model deployment, can reduce wasted computation cost by 50% without compromising the model deployment cadence.
Whither AutoML? Understanding the Role of Automation in Machine Learning Workflows
Jan 13, 2021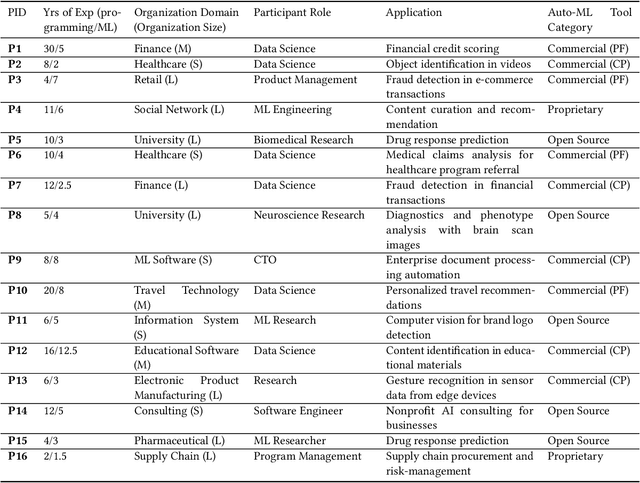
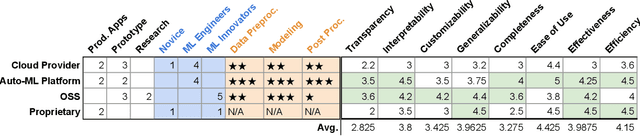
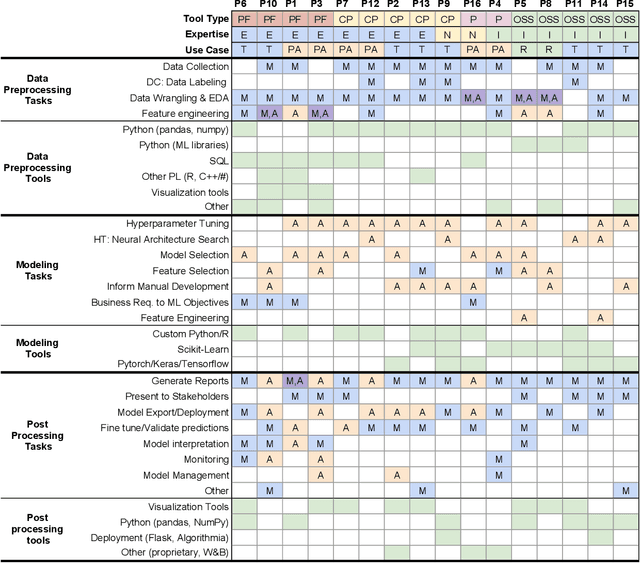
Efforts to make machine learning more widely accessible have led to a rapid increase in Auto-ML tools that aim to automate the process of training and deploying machine learning. To understand how Auto-ML tools are used in practice today, we performed a qualitative study with participants ranging from novice hobbyists to industry researchers who use Auto-ML tools. We present insights into the benefits and deficiencies of existing tools, as well as the respective roles of the human and automation in ML workflows. Finally, we discuss design implications for the future of Auto-ML tool development. We argue that instead of full automation being the ultimate goal of Auto-ML, designers of these tools should focus on supporting a partnership between the user and the Auto-ML tool. This means that a range of Auto-ML tools will need to be developed to support varying user goals such as simplicity, reproducibility, and reliability.
Demystifying a Dark Art: Understanding Real-World Machine Learning Model Development
May 04, 2020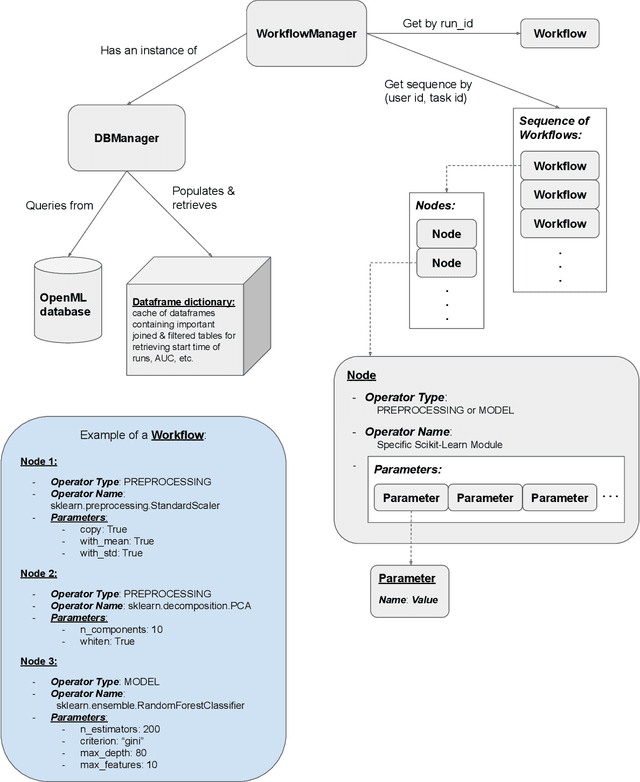
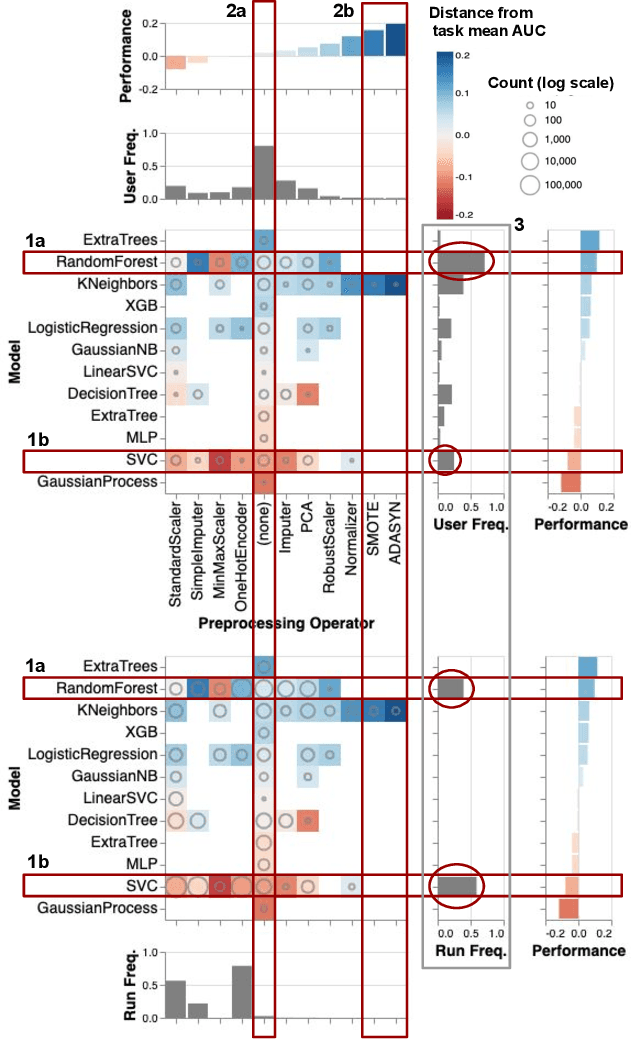
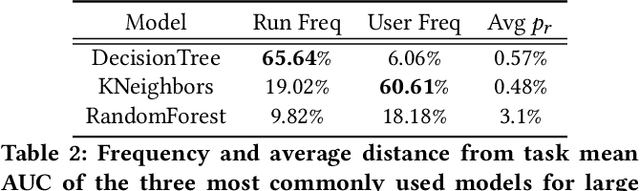
It is well-known that the process of developing machine learning (ML) workflows is a dark-art; even experts struggle to find an optimal workflow leading to a high accuracy model. Users currently rely on empirical trial-and-error to obtain their own set of battle-tested guidelines to inform their modeling decisions. In this study, we aim to demystify this dark art by understanding how people iterate on ML workflows in practice. We analyze over 475k user-generated workflows on OpenML, an open-source platform for tracking and sharing ML workflows. We find that users often adopt a manual, automated, or mixed approach when iterating on their workflows. We observe that manual approaches result in fewer wasted iterations compared to automated approaches. Yet, automated approaches often involve more preprocessing and hyperparameter options explored, resulting in higher performance overall--suggesting potential benefits for a human-in-the-loop ML system that appropriately recommends a clever combination of the two strategies.
Extending Relational Query Processing with ML Inference
Nov 01, 2019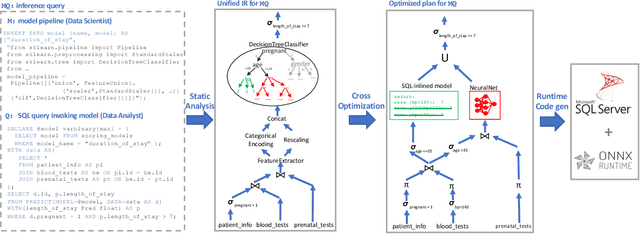

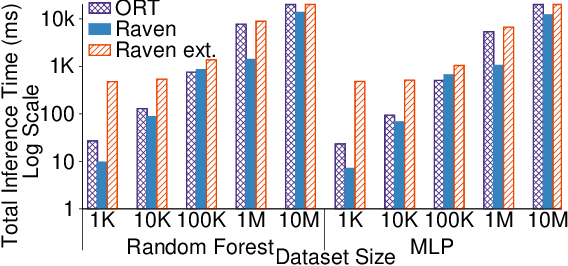
The broadening adoption of machine learning in the enterprise is increasing the pressure for strict governance and cost-effective performance, in particular for the common and consequential steps of model storage and inference. The RDBMS provides a natural starting point, given its mature infrastructure for fast data access and processing, along with support for enterprise features (e.g., encryption, auditing, high-availability). To take advantage of all of the above, we need to address a key concern: Can in-RDBMS scoring of ML models match (outperform?) the performance of dedicated frameworks? We answer the above positively by building Raven, a system that leverages native integration of ML runtimes (i.e., ONNX Runtime) deep within SQL Server, and a unified intermediate representation (IR) to enable advanced cross-optimizations between ML and DB operators. In this optimization space, we discover the most exciting research opportunities that combine DB/Compiler/ML thinking. Our initial evaluation on real data demonstrates performance gains of up to 5.5x from the native integration of ML in SQL Server, and up to 24x from cross-optimizations--we will demonstrate Raven live during the conference talk.
Helix: Holistic Optimization for Accelerating Iterative Machine Learning
Dec 14, 2018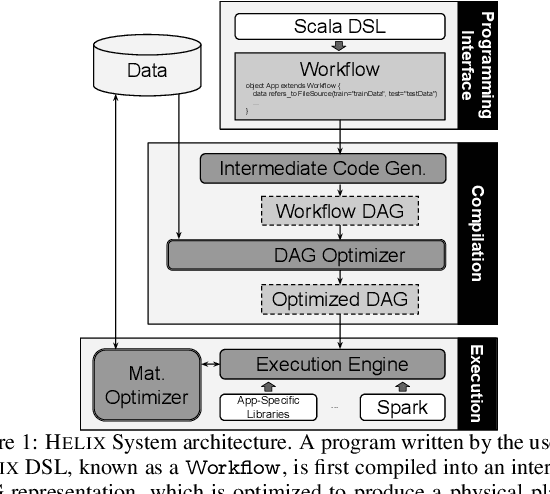
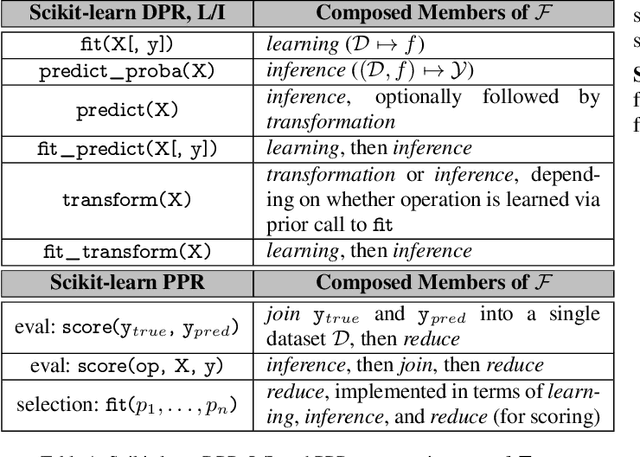
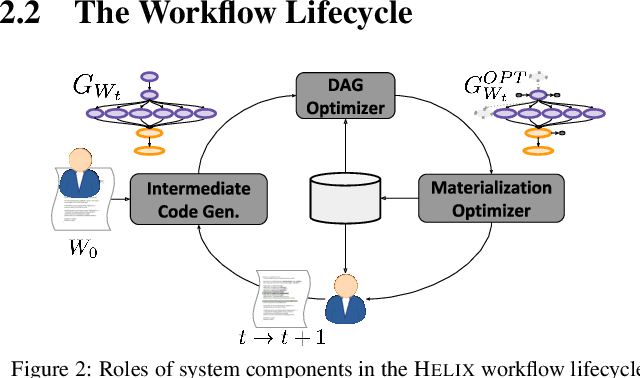
Machine learning workflow development is a process of trial-and-error: developers iterate on workflows by testing out small modifications until the desired accuracy is achieved. Unfortunately, existing machine learning systems focus narrowly on model training---a small fraction of the overall development time---and neglect to address iterative development. We propose Helix, a machine learning system that optimizes the execution across iterations---intelligently caching and reusing, or recomputing intermediates as appropriate. Helix captures a wide variety of application needs within its Scala DSL, with succinct syntax defining unified processes for data preprocessing, model specification, and learning. We demonstrate that the reuse problem can be cast as a Max-Flow problem, while the caching problem is NP-Hard. We develop effective lightweight heuristics for the latter. Empirical evaluation shows that Helix is not only able to handle a wide variety of use cases in one unified workflow but also much faster, providing run time reductions of up to 19x over state-of-the-art systems, such as DeepDive or KeystoneML, on four real-world applications in natural language processing, computer vision, social and natural sciences.
Helix: Accelerating Human-in-the-loop Machine Learning
Aug 03, 2018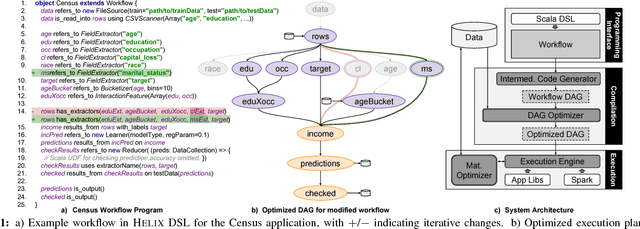
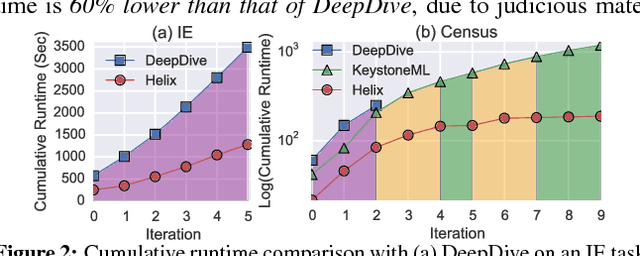
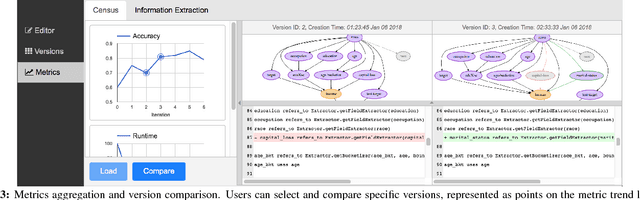
Data application developers and data scientists spend an inordinate amount of time iterating on machine learning (ML) workflows -- by modifying the data pre-processing, model training, and post-processing steps -- via trial-and-error to achieve the desired model performance. Existing work on accelerating machine learning focuses on speeding up one-shot execution of workflows, failing to address the incremental and dynamic nature of typical ML development. We propose Helix, a declarative machine learning system that accelerates iterative development by optimizing workflow execution end-to-end and across iterations. Helix minimizes the runtime per iteration via program analysis and intelligent reuse of previous results, which are selectively materialized -- trading off the cost of materialization for potential future benefits -- to speed up future iterations. Additionally, Helix offers a graphical interface to visualize workflow DAGs and compare versions to facilitate iterative development. Through two ML applications, in classification and in structured prediction, attendees will experience the succinctness of Helix programming interface and the speed and ease of iterative development using Helix. In our evaluations, Helix achieved up to an order of magnitude reduction in cumulative run time compared to state-of-the-art machine learning tools.
How Developers Iterate on Machine Learning Workflows -- A Survey of the Applied Machine Learning Literature
May 17, 2018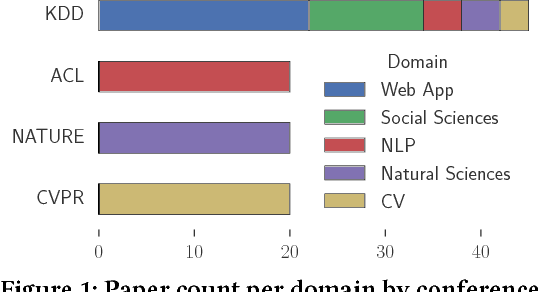

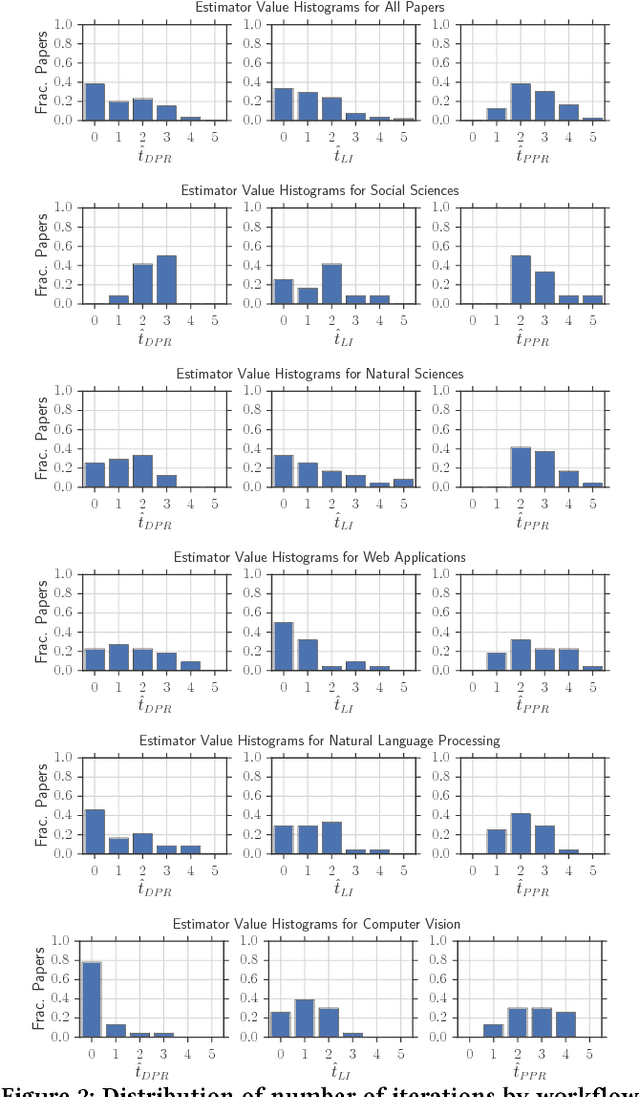

Machine learning workflow development is anecdotally regarded to be an iterative process of trial-and-error with humans-in-the-loop. However, we are not aware of quantitative evidence corroborating this popular belief. A quantitative characterization of iteration can serve as a benchmark for machine learning workflow development in practice, and can aid the development of human-in-the-loop machine learning systems. To this end, we conduct a small-scale survey of the applied machine learning literature from five distinct application domains. We collect and distill statistics on the role of iteration within machine learning workflow development, and report preliminary trends and insights from our investigation, as a starting point towards this benchmark. Based on our findings, we finally describe desiderata for effective and versatile human-in-the-loop machine learning systems that can cater to users in diverse domains.
MLlib: Machine Learning in Apache Spark
May 26, 2015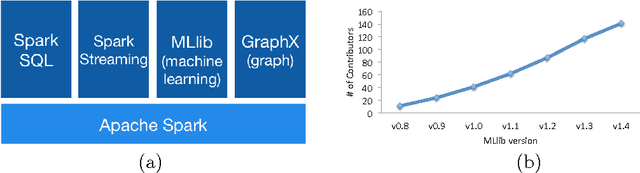
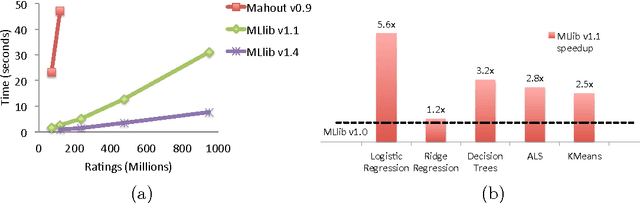
Apache Spark is a popular open-source platform for large-scale data processing that is well-suited for iterative machine learning tasks. In this paper we present MLlib, Spark's open-source distributed machine learning library. MLlib provides efficient functionality for a wide range of learning settings and includes several underlying statistical, optimization, and linear algebra primitives. Shipped with Spark, MLlib supports several languages and provides a high-level API that leverages Spark's rich ecosystem to simplify the development of end-to-end machine learning pipelines. MLlib has experienced a rapid growth due to its vibrant open-source community of over 140 contributors, and includes extensive documentation to support further growth and to let users quickly get up to speed.
Parallel computation using active self-assembly
Sep 05, 2014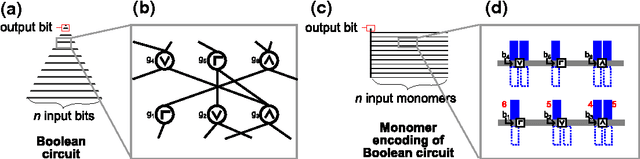
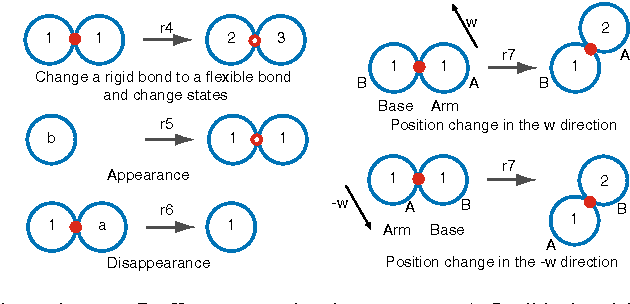

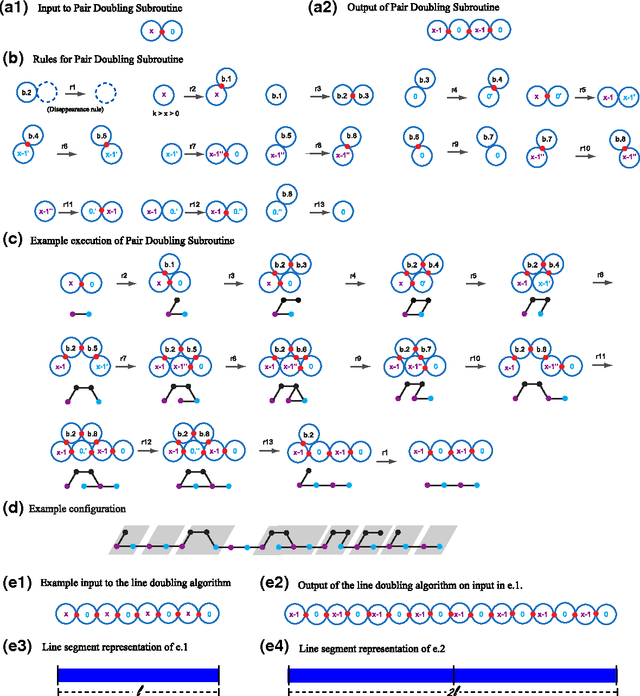
We study the computational complexity of the recently proposed nubot model of molecular-scale self-assembly. The model generalises asynchronous cellular automata to have non-local movement where large assemblies of molecules can be pushed and pulled around, analogous to millions of molecular motors in animal muscle effecting the rapid movement of macroscale arms and legs. We show that the nubot model is capable of simulating Boolean circuits of polylogarithmic depth and polynomial size, in only polylogarithmic expected time. In computational complexity terms, we show that any problem from the complexity class NC is solvable in polylogarithmic expected time and polynomial workspace using nubots. Along the way, we give fast parallel nubot algorithms for a number of problems including line growth, sorting, Boolean matrix multiplication and space-bounded Turing machine simulation, all using a constant number of nubot states (monomer types). Circuit depth is a well-studied notion of parallel time, and our result implies that the nubot model is a highly parallel model of computation in a formal sense. Asynchronous cellular automata are not capable of this parallelism, and our result shows that adding a rigid-body movement primitive to such a model, to get the nubot model, drastically increases parallel processing abilities.