 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(Beyond) Reasonable Doubt: Challenges that Public Defenders Face in Scrutinizing AI in Court
Mar 13, 2024
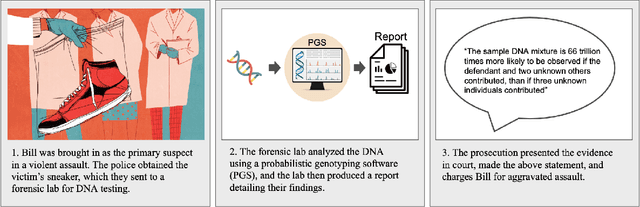
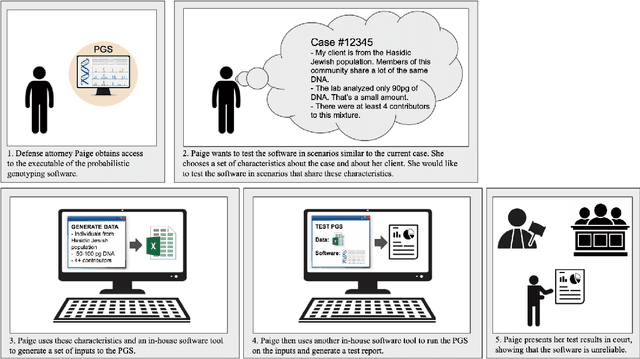

Accountable use of AI systems in high-stakes settings relies on making systems contestable. In this paper we study efforts to contest AI systems in practice by studying how public defenders scrutinize AI in court. We present findings from interviews with 17 people in the U.S. public defense community to understand their perceptions of and experiences scrutinizing computational forensic software (CFS) -- automated decision systems that the government uses to convict and incarcerate, such as facial recognition, gunshot detection, and probabilistic genotyping tools. We find that our participants faced challenges assessing and contesting CFS reliability due to difficulties (a) navigating how CFS is developed and used, (b) overcoming judges and jurors' non-critical perceptions of CFS, and (c) gathering CFS expertise. To conclude, we provide recommendations that center the technical, social, and institutional context to better position interventions such as performance evaluations to support contestability in practice.
Physician Detection of Clinical Harm in Machine Translation: Quality Estimation Aids in Reliance and Backtranslation Identifies Critical Errors
Oct 25, 2023A major challenge in the practical use of Machine Translation (MT) is that users lack guidance to make informed decisions about when to rely on outputs. Progress in quality estimation research provides techniques to automatically assess MT quality, but these techniques have primarily been evaluated in vitro by comparison against human judgments outside of a specific context of use. This paper evaluates quality estimation feedback in vivo with a human study simulating decision-making in high-stakes medical settings. Using Emergency Department discharge instructions, we study how interventions based on quality estimation versus backtranslation assist physicians in deciding whether to show MT outputs to a patient. We find that quality estimation improves appropriate reliance on MT, but backtranslation helps physicians detect more clinically harmful errors that QE alone often misses.
Beyond General Purpose Machine Translation: The Need for Context-specific Empirical Research to Design for Appropriate User Trust
May 13, 2022Machine Translation (MT) has the potential to help people overcome language barriers and is widely used in high-stakes scenarios, such as in hospitals. However, in order to use MT reliably and safely, users need to understand when to trust MT outputs and how to assess the quality of often imperfect translation results. In this paper, we discuss research directions to support users to calibrate trust in MT systems. We share findings from an empirical study in which we conducted semi-structured interviews with 20 clinicians to understand how they communicate with patients across language barriers, and if and how they use MT systems. Based on our findings, we advocate for empirical research on how MT systems are used in practice as an important first step to addressing the challenges in building appropriate trust between users and MT tools.
Whither AutoML? Understanding the Role of Automation in Machine Learning Workflows
Jan 13, 2021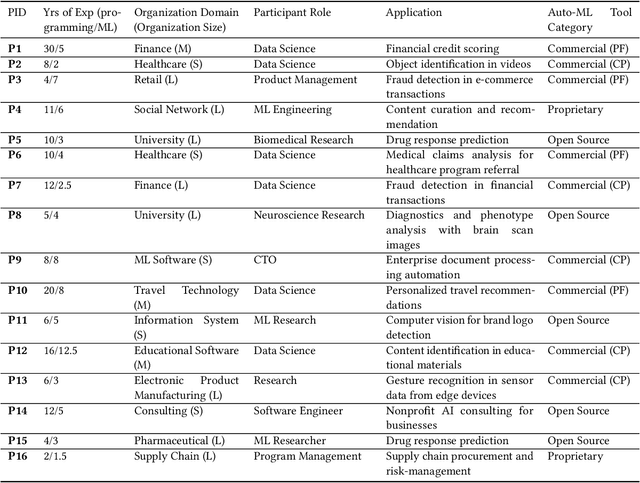
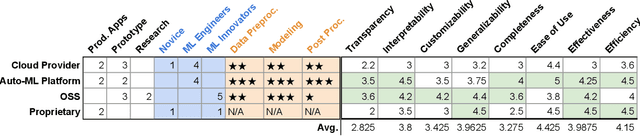
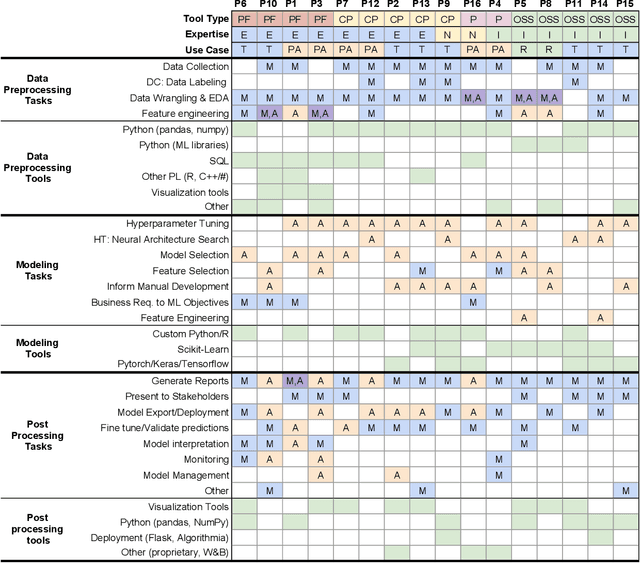
Efforts to make machine learning more widely accessible have led to a rapid increase in Auto-ML tools that aim to automate the process of training and deploying machine learning. To understand how Auto-ML tools are used in practice today, we performed a qualitative study with participants ranging from novice hobbyists to industry researchers who use Auto-ML tools. We present insights into the benefits and deficiencies of existing tools, as well as the respective roles of the human and automation in ML workflows. Finally, we discuss design implications for the future of Auto-ML tool development. We argue that instead of full automation being the ultimate goal of Auto-ML, designers of these tools should focus on supporting a partnership between the user and the Auto-ML tool. This means that a range of Auto-ML tools will need to be developed to support varying user goals such as simplicity, reproducibility, and reliability.
What If I Don't Like Any Of The Choices? The Limits of Preference Elicitation for Participatory Algorithm Design
Jul 13, 2020Emerging methods for participatory algorithm design have proposed collecting and aggregating individual stakeholder preferences to create algorithmic systems that account for those stakeholders' values. Using algorithmic student assignment as a case study, we argue that optimizing for individual preference satisfaction in the distribution of limited resources may actually inhibit progress towards social and distributive justice. Individual preferences can be a useful signal but should be expanded to support more expressive and inclusive forms of democratic participation.