 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeER-REASON: A Benchmark Dataset for LLM-Based Clinical Reasoning in the Emergency Room
May 28, 2025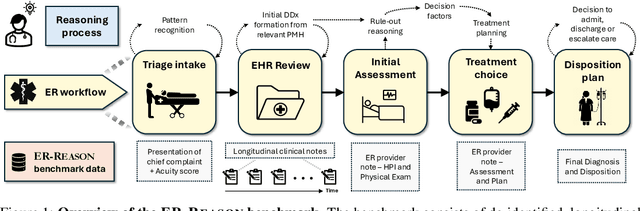



Large language models (LLMs) have been extensively evaluated on medical question answering tasks based on licensing exams. However, real-world evaluations often depend on costly human annotators, and existing benchmarks tend to focus on isolated tasks that rarely capture the clinical reasoning or full workflow underlying medical decisions. In this paper, we introduce ER-Reason, a benchmark designed to evaluate LLM-based clinical reasoning and decision-making in the emergency room (ER)--a high-stakes setting where clinicians make rapid, consequential decisions across diverse patient presentations and medical specialties under time pressure. ER-Reason includes data from 3,984 patients, encompassing 25,174 de-identified longitudinal clinical notes spanning discharge summaries, progress notes, history and physical exams, consults, echocardiography reports, imaging notes, and ER provider documentation. The benchmark includes evaluation tasks that span key stages of the ER workflow: triage intake, initial assessment, treatment selection, disposition planning, and final diagnosis--each structured to reflect core clinical reasoning processes such as differential diagnosis via rule-out reasoning. We also collected 72 full physician-authored rationales explaining reasoning processes that mimic the teaching process used in residency training, and are typically absent from ER documentation. Evaluations of state-of-the-art LLMs on ER-Reason reveal a gap between LLM-generated and clinician-authored clinical reasoning for ER decisions, highlighting the need for future research to bridge this divide.
BioAgents: Democratizing Bioinformatics Analysis with Multi-Agent Systems
Jan 10, 2025Creating end-to-end bioinformatics workflows requires diverse domain expertise, which poses challenges for both junior and senior researchers as it demands a deep understanding of both genomics concepts and computational techniques. While large language models (LLMs) provide some assistance, they often fall short in providing the nuanced guidance needed to execute complex bioinformatics tasks, and require expensive computing resources to achieve high performance. We thus propose a multi-agent system built on small language models, fine-tuned on bioinformatics data, and enhanced with retrieval augmented generation (RAG). Our system, BioAgents, enables local operation and personalization using proprietary data. We observe performance comparable to human experts on conceptual genomics tasks, and suggest next steps to enhance code generation capabilities.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
Physician Detection of Clinical Harm in Machine Translation: Quality Estimation Aids in Reliance and Backtranslation Identifies Critical Errors
Oct 25, 2023A major challenge in the practical use of Machine Translation (MT) is that users lack guidance to make informed decisions about when to rely on outputs. Progress in quality estimation research provides techniques to automatically assess MT quality, but these techniques have primarily been evaluated in vitro by comparison against human judgments outside of a specific context of use. This paper evaluates quality estimation feedback in vivo with a human study simulating decision-making in high-stakes medical settings. Using Emergency Department discharge instructions, we study how interventions based on quality estimation versus backtranslation assist physicians in deciding whether to show MT outputs to a patient. We find that quality estimation improves appropriate reliance on MT, but backtranslation helps physicians detect more clinically harmful errors that QE alone often misses.
Beyond General Purpose Machine Translation: The Need for Context-specific Empirical Research to Design for Appropriate User Trust
May 13, 2022Machine Translation (MT) has the potential to help people overcome language barriers and is widely used in high-stakes scenarios, such as in hospitals. However, in order to use MT reliably and safely, users need to understand when to trust MT outputs and how to assess the quality of often imperfect translation results. In this paper, we discuss research directions to support users to calibrate trust in MT systems. We share findings from an empirical study in which we conducted semi-structured interviews with 20 clinicians to understand how they communicate with patients across language barriers, and if and how they use MT systems. Based on our findings, we advocate for empirical research on how MT systems are used in practice as an important first step to addressing the challenges in building appropriate trust between users and MT tools.