 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Automatic Audiobook Creation
Sep 07, 2023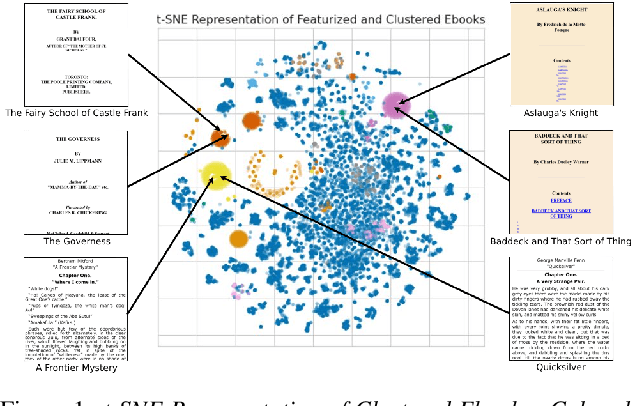
An audiobook can dramatically improve a work of literature's accessibility and improve reader engagement. However, audiobooks can take hundreds of hours of human effort to create, edit, and publish. In this work, we present a system that can automatically generate high-quality audiobooks from online e-books. In particular, we leverage recent advances in neural text-to-speech to create and release thousands of human-quality, open-license audiobooks from the Project Gutenberg e-book collection. Our method can identify the proper subset of e-book content to read for a wide collection of diversely structured books and can operate on hundreds of books in parallel. Our system allows users to customize an audiobook's speaking speed and style, emotional intonation, and can even match a desired voice using a small amount of sample audio. This work contributed over five thousand open-license audiobooks and an interactive demo that allows users to quickly create their own customized audiobooks. To listen to the audiobook collection visit \url{https://aka.ms/audiobook}.
A Tensor Compiler for Unified Machine Learning Prediction Serving
Oct 19, 2020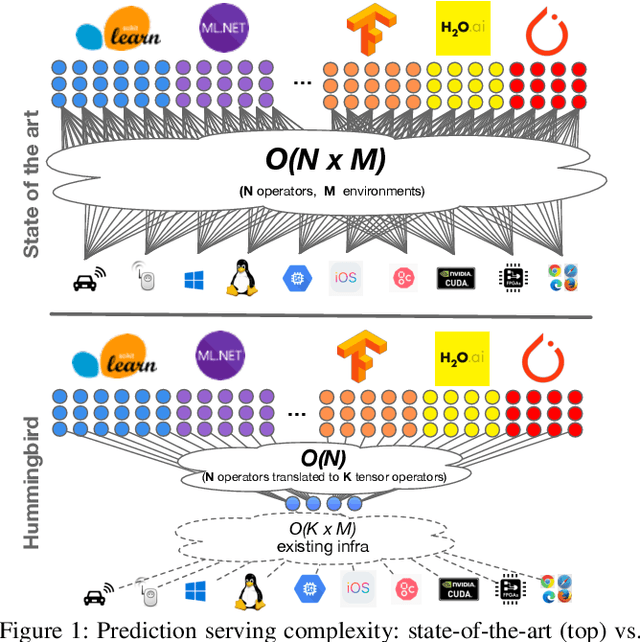

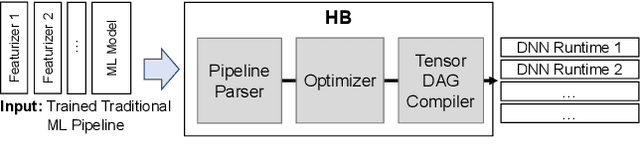

Machine Learning (ML) adoption in the enterprise requires simpler and more efficient software infrastructure---the bespoke solutions typical in large web companies are simply untenable. Model scoring, the process of obtaining predictions from a trained model over new data, is a primary contributor to infrastructure complexity and cost as models are trained once but used many times. In this paper we propose HUMMINGBIRD, a novel approach to model scoring, which compiles featurization operators and traditional ML models (e.g., decision trees) into a small set of tensor operations. This approach inherently reduces infrastructure complexity and directly leverages existing investments in Neural Network compilers and runtimes to generate efficient computations for both CPU and hardware accelerators. Our performance results are intriguing: despite replacing imperative computations (e.g., tree traversals) with tensor computation abstractions, HUMMINGBIRD is competitive and often outperforms hand-crafted kernels on micro-benchmarks on both CPU and GPU, while enabling seamless end-to-end acceleration of ML pipelines. We have released HUMMINGBIRD as open source.
MLOS: An Infrastructure for Automated Software Performance Engineering
Jun 04, 2020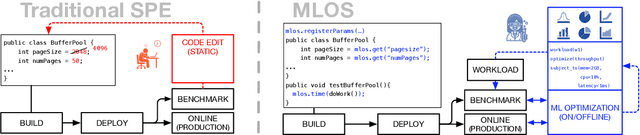
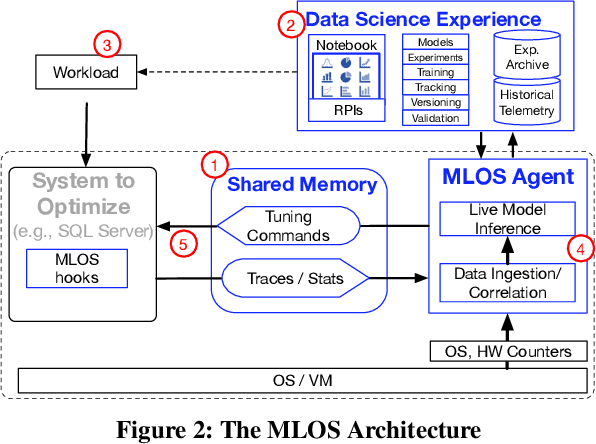
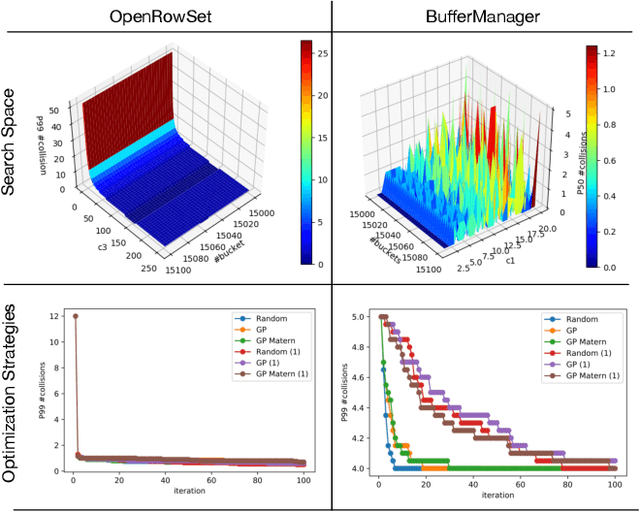
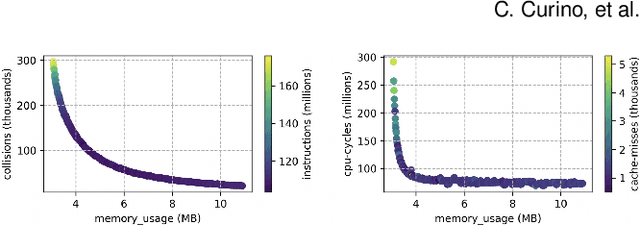
Developing modern systems software is a complex task that combines business logic programming and Software Performance Engineering (SPE). The later is an experimental and labor-intensive activity focused on optimizing the system for a given hardware, software, and workload (hw/sw/wl) context. Today's SPE is performed during build/release phases by specialized teams, and cursed by: 1) lack of standardized and automated tools, 2) significant repeated work as hw/sw/wl context changes, 3) fragility induced by a "one-size-fit-all" tuning (where improvements on one workload or component may impact others). The net result: despite costly investments, system software is often outside its optimal operating point - anecdotally leaving 30% to 40% of performance on the table. The recent developments in Data Science (DS) hints at an opportunity: combining DS tooling and methodologies with a new developer experience to transform the practice of SPE. In this paper we present: MLOS, an ML-powered infrastructure and methodology to democratize and automate Software Performance Engineering. MLOS enables continuous, instance-level, robust, and trackable systems optimization. MLOS is being developed and employed within Microsoft to optimize SQL Server performance. Early results indicated that component-level optimizations can lead to 20%-90% improvements when custom-tuning for a specific hw/sw/wl, hinting at a significant opportunity. However, several research challenges remain that will require community involvement. To this end, we are in the process of open-sourcing the MLOS core infrastructure, and we are engaging with academic institutions to create an educational program around Software 2.0 and MLOS ideas.
Data Science through the looking glass and what we found there
Dec 19, 2019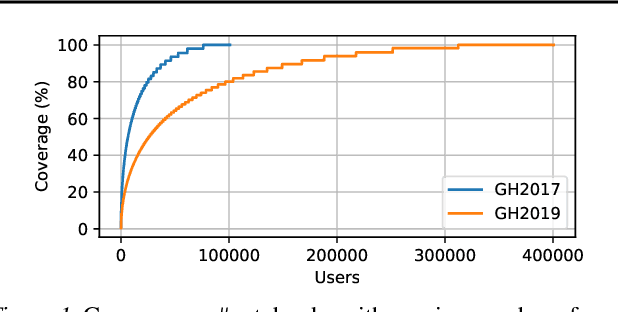
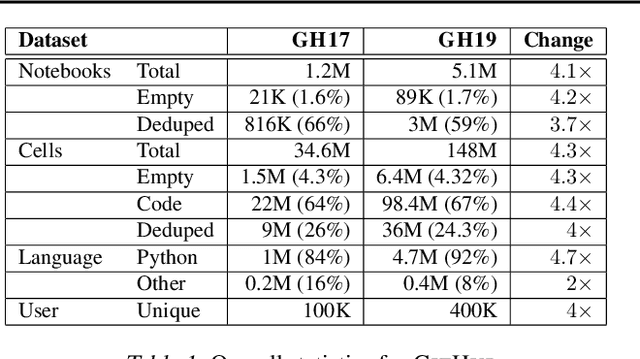
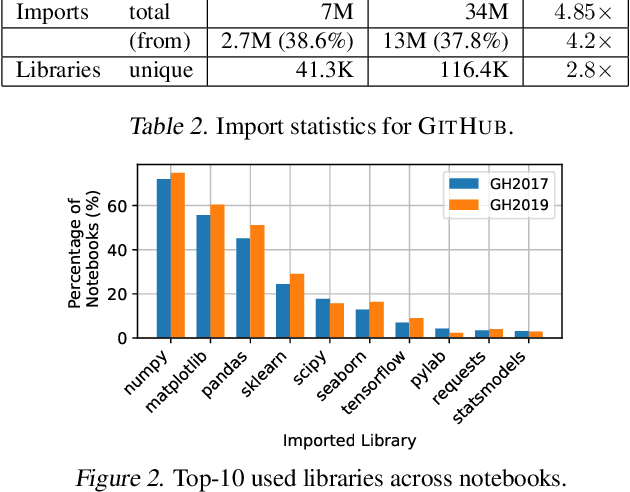
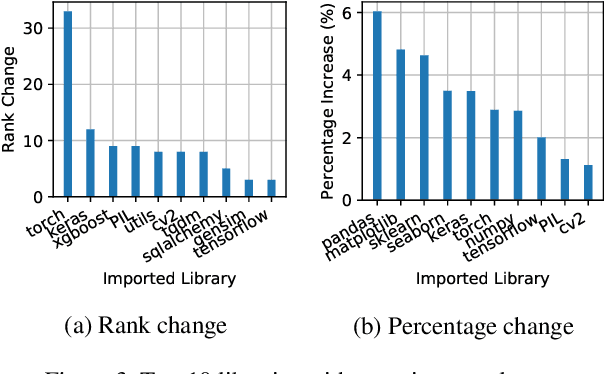
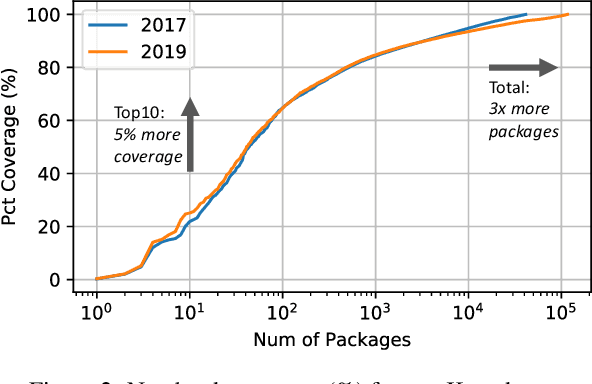
The recent success of machine learning (ML) has led to an explosive growth both in terms of new systems and algorithms built in industry and academia, and new applications built by an ever-growing community of data science (DS) practitioners. This quickly shifting panorama of technologies and applications is challenging for builders and practitioners alike to follow. In this paper, we set out to capture this panorama through a wide-angle lens, by performing the largest analysis of DS projects to date, focusing on questions that can help determine investments on either side. Specifically, we download and analyze: (a) over 6M Python notebooks publicly available on GITHUB, (b) over 2M enterprise DS pipelines developed within COMPANYX, and (c) the source code and metadata of over 900 releases from 12 important DS libraries. The analysis we perform ranges from coarse-grained statistical characterizations to analysis of library imports, pipelines, and comparative studies across datasets and time. We report a large number of measurements for our readers to interpret, and dare to draw a few (actionable, yet subjective) conclusions on (a) what systems builders should focus on to better serve practitioners, and (b) what technologies should practitioners bet on given current trends. We plan to automate this analysis and release associated tools and results periodically.
Extending Relational Query Processing with ML Inference
Nov 01, 2019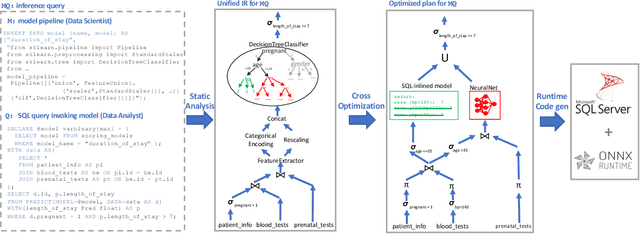

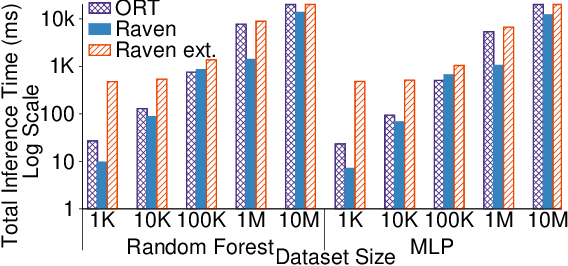
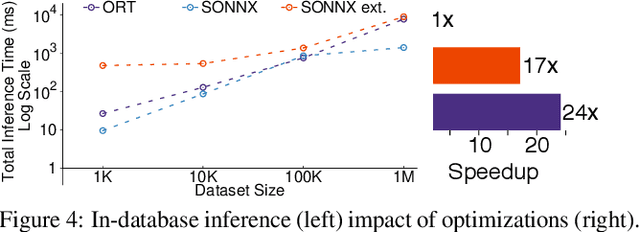
The broadening adoption of machine learning in the enterprise is increasing the pressure for strict governance and cost-effective performance, in particular for the common and consequential steps of model storage and inference. The RDBMS provides a natural starting point, given its mature infrastructure for fast data access and processing, along with support for enterprise features (e.g., encryption, auditing, high-availability). To take advantage of all of the above, we need to address a key concern: Can in-RDBMS scoring of ML models match (outperform?) the performance of dedicated frameworks? We answer the above positively by building Raven, a system that leverages native integration of ML runtimes (i.e., ONNX Runtime) deep within SQL Server, and a unified intermediate representation (IR) to enable advanced cross-optimizations between ML and DB operators. In this optimization space, we discover the most exciting research opportunities that combine DB/Compiler/ML thinking. Our initial evaluation on real data demonstrates performance gains of up to 5.5x from the native integration of ML in SQL Server, and up to 24x from cross-optimizations--we will demonstrate Raven live during the conference talk.
Cloudy with high chance of DBMS: A 10-year prediction for Enterprise-Grade ML
Aug 30, 2019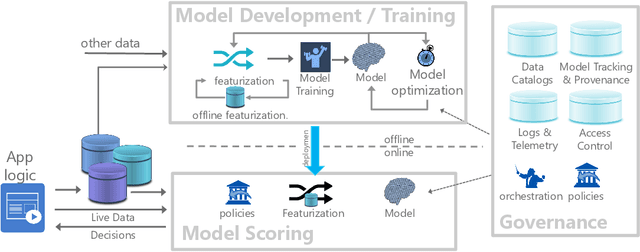
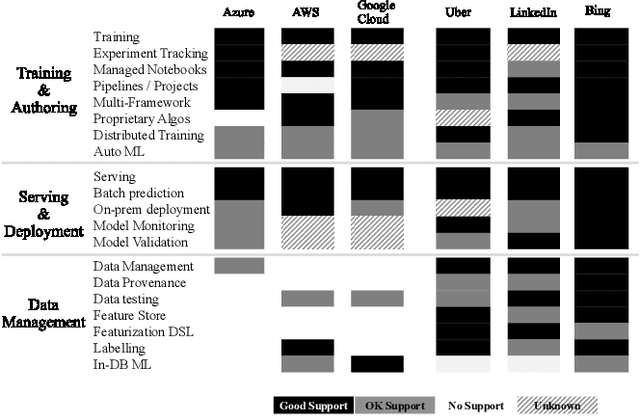
Machine learning (ML) has proven itself in high-value web applications such as search ranking and is emerging as a powerful tool in a much broader range of enterprise scenarios including voice recognition and conversational understanding for customer support, autotuning for videoconferencing, inteligent feedback loops in largescale sysops, manufacturing and autonomous vehicle management, complex financial predictions, just to name a few. Meanwhile, as the value of data is increasingly recognized and monetized, concerns about securing valuable data and risks to individual privacy have been growing. Consequently, rigorous data management has emerged as a key requirement in enterprise settings. How will these trends (ML growing popularity, and stricter data governance) intersect? What are the unmet requirements for applying ML in enterprise settings? What are the technical challenges for the DB community to solve? In this paper, we present our vision of how ML and database systems are likely to come together, and early steps we take towards making this vision a reality.
Making Classical Machine Learning Pipelines Differentiable: A Neural Translation Approach
Jun 10, 2019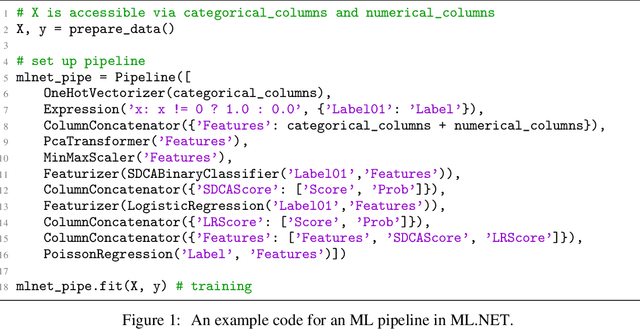

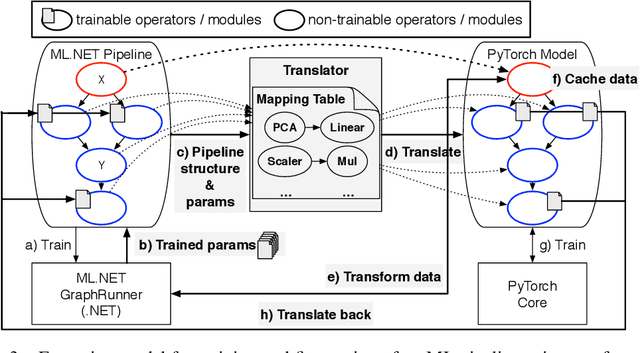
Classical Machine Learning (ML) pipelines often comprise of multiple ML models where models, within a pipeline, are trained in isolation. Conversely, when training neural network models, layers composing the neural models are simultaneously trained using backpropagation. We argue that the isolated training scheme of ML pipelines is sub-optimal, since it cannot jointly optimize multiple components. To this end, we propose a framework that translates a pre-trained ML pipeline into a neural network and fine-tunes the ML models within the pipeline jointly using backpropagation. Our experiments show that fine-tuning of the translated pipelines is a promising technique able to increase the final accuracy.
Machine Learning at Microsoft with ML .NET
May 15, 2019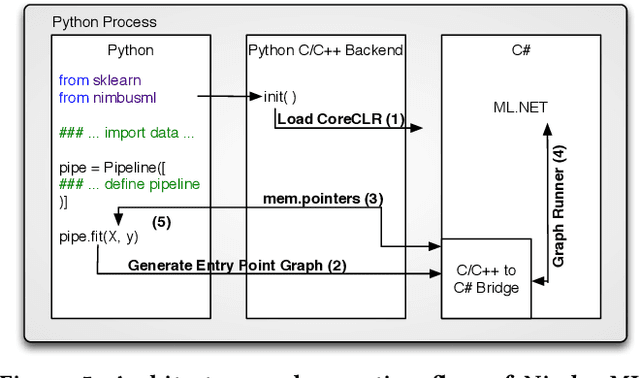
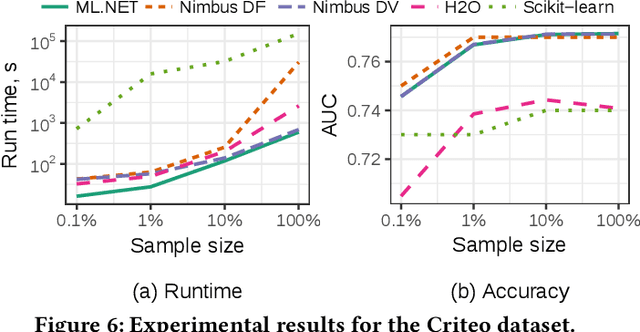
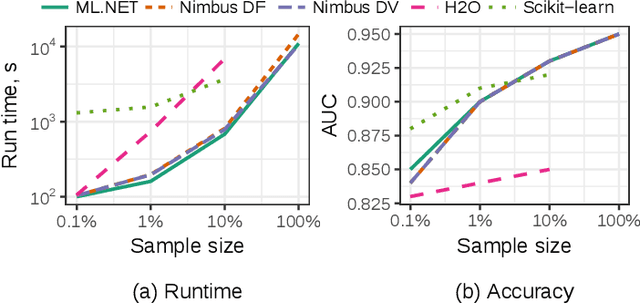
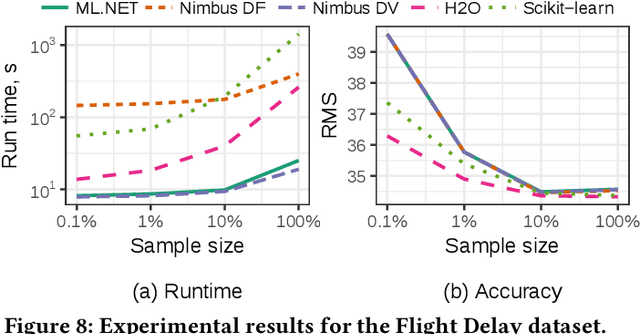
Machine Learning is transitioning from an art and science into a technology available to every developer. In the near future, every application on every platform will incorporate trained models to encode data-based decisions that would be impossible for developers to author. This presents a significant engineering challenge, since currently data science and modeling are largely decoupled from standard software development processes. This separation makes incorporating machine learning capabilities inside applications unnecessarily costly and difficult, and furthermore discourage developers from embracing ML in first place. In this paper we present ML .NET, a framework developed at Microsoft over the last decade in response to the challenge of making it easy to ship machine learning models in large software applications. We present its architecture, and illuminate the application demands that shaped it. Specifically, we introduce DataView, the core data abstraction of ML .NET which allows it to capture full predictive pipelines efficiently and consistently across training and inference lifecycles. We close the paper with a surprisingly favorable performance study of ML .NET compared to more recent entrants, and a discussion of some lessons learned.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
PDP: A General Neural Framework for Learning Constraint Satisfaction Solvers
Mar 05, 2019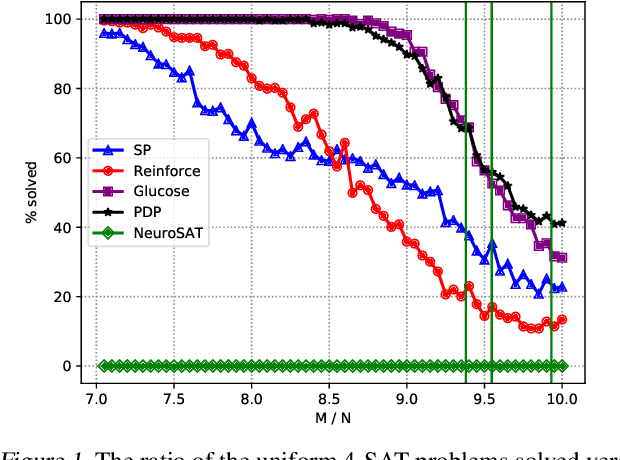
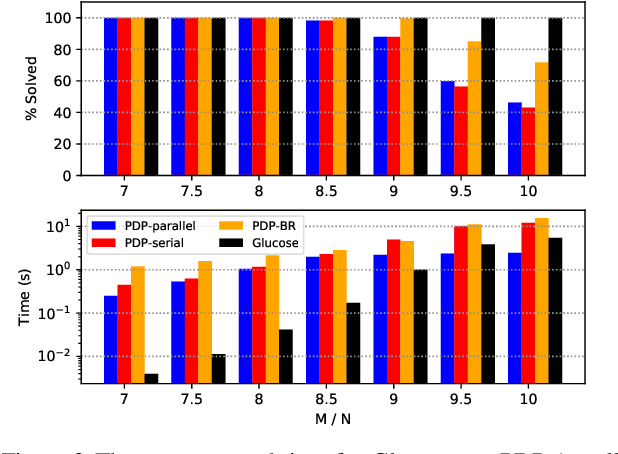
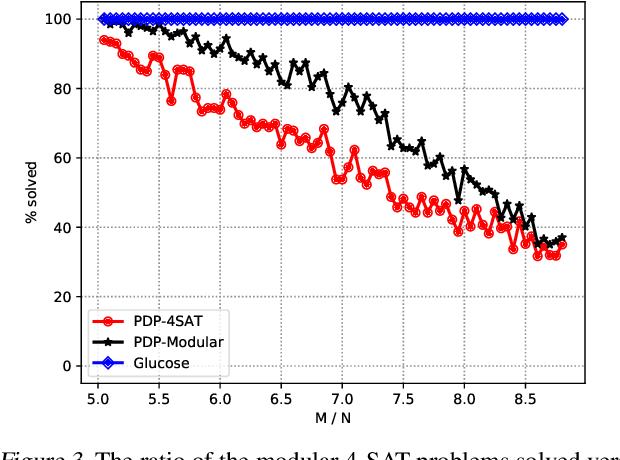
There have been recent efforts for incorporating Graph Neural Network models for learning full-stack solvers for constraint satisfaction problems (CSP) and particularly Boolean satisfiability (SAT). Despite the unique representational power of these neural embedding models, it is not clear how the search strategy in the learned models actually works. On the other hand, by fixing the search strategy (e.g. greedy search), we would effectively deprive the neural models of learning better strategies than those given. In this paper, we propose a generic neural framework for learning CSP solvers that can be described in terms of probabilistic inference and yet learn search strategies beyond greedy search. Our framework is based on the idea of propagation, decimation and prediction (and hence the name PDP) in graphical models, and can be trained directly toward solving CSP in a fully unsupervised manner via energy minimization, as shown in the paper. Our experimental results demonstrate the effectiveness of our framework for SAT solving compared to both neural and the state-of-the-art baselines.