 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Words to Code: Harnessing Data for Program Synthesis from Natural Language
May 03, 2023



Creating programs to correctly manipulate data is a difficult task, as the underlying programming languages and APIs can be challenging to learn for many users who are not skilled programmers. Large language models (LLMs) demonstrate remarkable potential for generating code from natural language, but in the data manipulation domain, apart from the natural language (NL) description of the intended task, we also have the dataset on which the task is to be performed, or the "data context". Existing approaches have utilized data context in a limited way by simply adding relevant information from the input data into the prompts sent to the LLM. In this work, we utilize the available input data to execute the candidate programs generated by the LLMs and gather their outputs. We introduce semantic reranking, a technique to rerank the programs generated by LLMs based on three signals coming the program outputs: (a) semantic filtering and well-formedness based score tuning: do programs even generate well-formed outputs, (b) semantic interleaving: how do the outputs from different candidates compare to each other, and (c) output-based score tuning: how do the outputs compare to outputs predicted for the same task. We provide theoretical justification for semantic interleaving. We also introduce temperature mixing, where we combine samples generated by LLMs using both high and low temperatures. We extensively evaluate our approach in three domains, namely databases (SQL), data science (Pandas) and business intelligence (Excel's Power Query M) on a variety of new and existing benchmarks. We observe substantial gains across domains, with improvements of up to 45% in top-1 accuracy and 34% in top-3 accuracy.
Vamsa: Tracking Provenance in Data Science Scripts
Jan 07, 2020

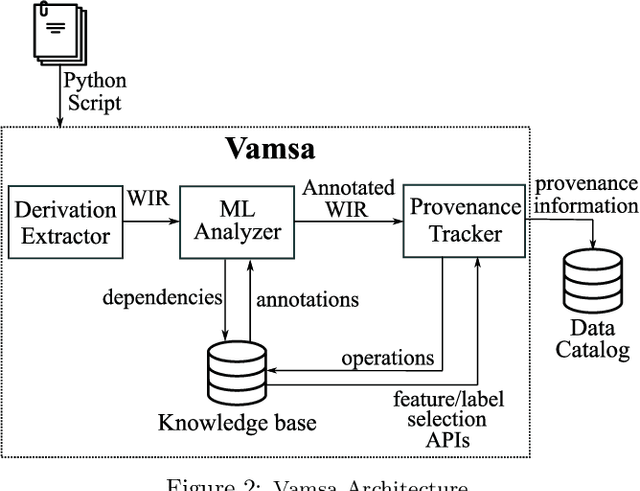

Machine learning (ML) which was initially adopted for search ranking and recommendation systems has firmly moved into the realm of core enterprise operations like sales optimization and preventative healthcare. For such ML applications, often deployed in regulated environments, the standards for user privacy, security, and data governance are substantially higher. This imposes the need for tracking provenance end-to-end, from the data sources used for training ML models to the predictions of the deployed models. In this work, we take a first step towards this direction by introducing the ML provenance tracking problem in the context of data science scripts. The fundamental idea is to automatically identify the relationships between data and ML models and in particular, to track which columns in a dataset have been used to derive the features of a ML model. We discuss the challenges in capturing such provenance information in the context of Python, the most common language used by data scientists. We then, present Vamsa, a modular system that extracts provenance from Python scripts without requiring any changes to the user's code. Using up to 450K real-world data science scripts from Kaggle and publicly available Python notebooks, we verify the effectiveness of Vamsa in terms of coverage, and performance. We also evaluate Vamsa's accuracy on a smaller subset of manually labeled data. Our analysis shows that Vamsa's precision and recall range from 87.5% to 98.3% and its latency is typically in the order of milliseconds for scripts of average size.
Data Science through the looking glass and what we found there
Dec 19, 2019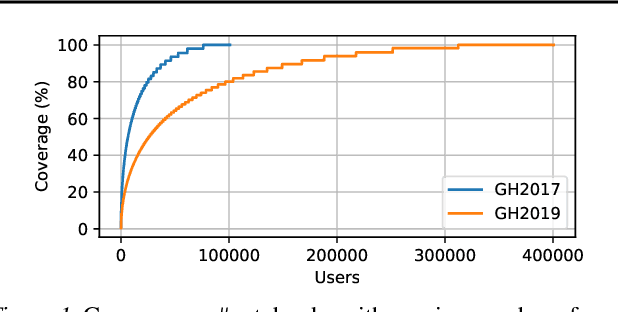
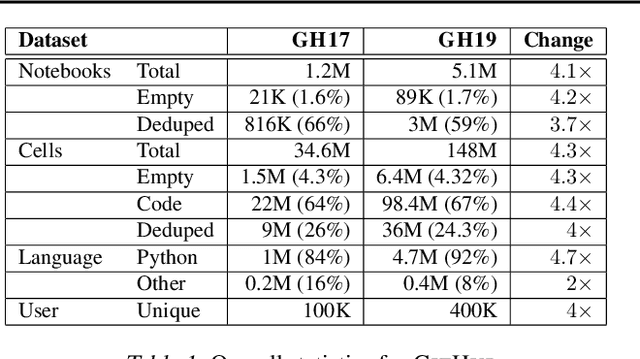
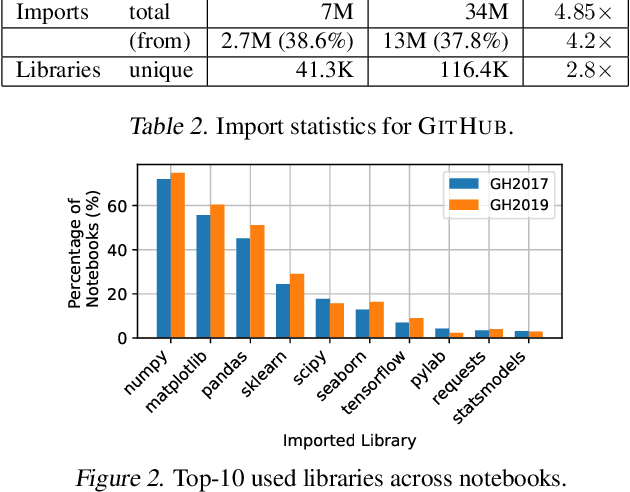
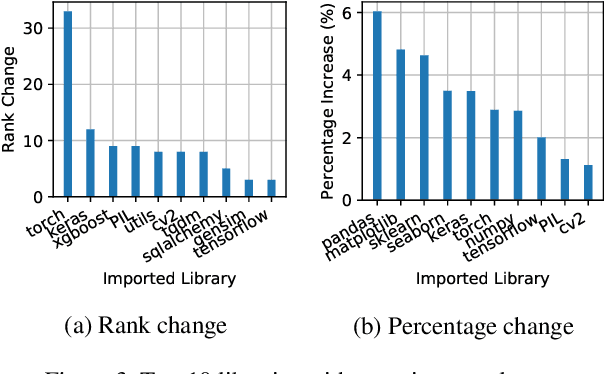
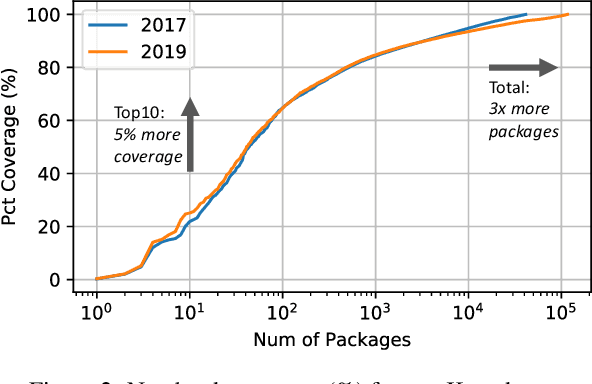
The recent success of machine learning (ML) has led to an explosive growth both in terms of new systems and algorithms built in industry and academia, and new applications built by an ever-growing community of data science (DS) practitioners. This quickly shifting panorama of technologies and applications is challenging for builders and practitioners alike to follow. In this paper, we set out to capture this panorama through a wide-angle lens, by performing the largest analysis of DS projects to date, focusing on questions that can help determine investments on either side. Specifically, we download and analyze: (a) over 6M Python notebooks publicly available on GITHUB, (b) over 2M enterprise DS pipelines developed within COMPANYX, and (c) the source code and metadata of over 900 releases from 12 important DS libraries. The analysis we perform ranges from coarse-grained statistical characterizations to analysis of library imports, pipelines, and comparative studies across datasets and time. We report a large number of measurements for our readers to interpret, and dare to draw a few (actionable, yet subjective) conclusions on (a) what systems builders should focus on to better serve practitioners, and (b) what technologies should practitioners bet on given current trends. We plan to automate this analysis and release associated tools and results periodically.
Cloudy with high chance of DBMS: A 10-year prediction for Enterprise-Grade ML
Aug 30, 2019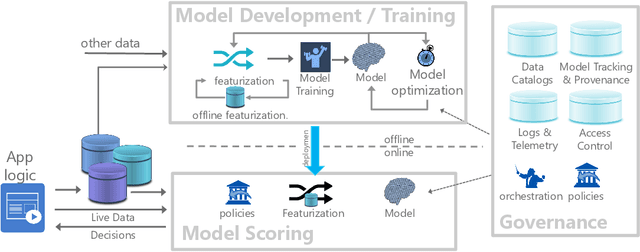
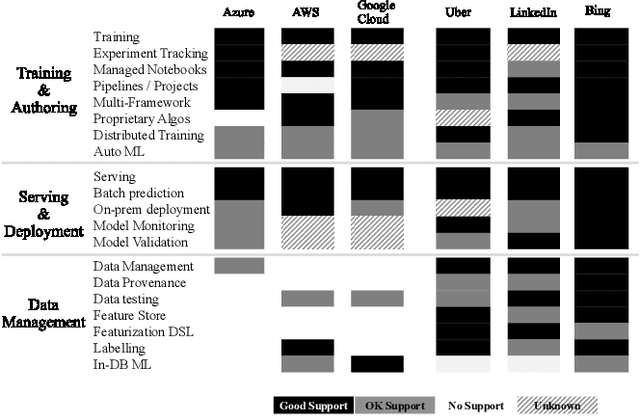
Machine learning (ML) has proven itself in high-value web applications such as search ranking and is emerging as a powerful tool in a much broader range of enterprise scenarios including voice recognition and conversational understanding for customer support, autotuning for videoconferencing, inteligent feedback loops in largescale sysops, manufacturing and autonomous vehicle management, complex financial predictions, just to name a few. Meanwhile, as the value of data is increasingly recognized and monetized, concerns about securing valuable data and risks to individual privacy have been growing. Consequently, rigorous data management has emerged as a key requirement in enterprise settings. How will these trends (ML growing popularity, and stricter data governance) intersect? What are the unmet requirements for applying ML in enterprise settings? What are the technical challenges for the DB community to solve? In this paper, we present our vision of how ML and database systems are likely to come together, and early steps we take towards making this vision a reality.