 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAB: Provable Robustness Against Backdoor Attacks
Mar 19, 2020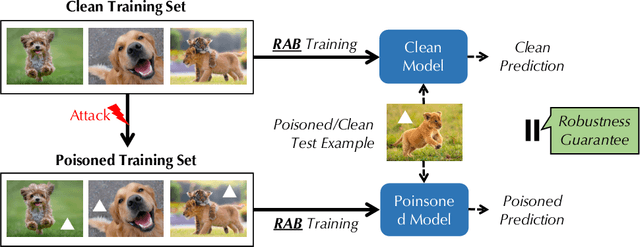
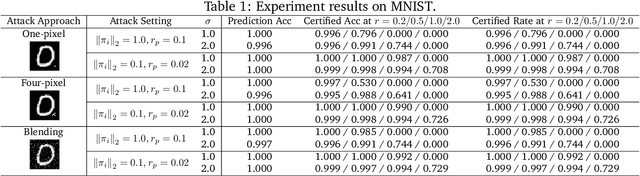
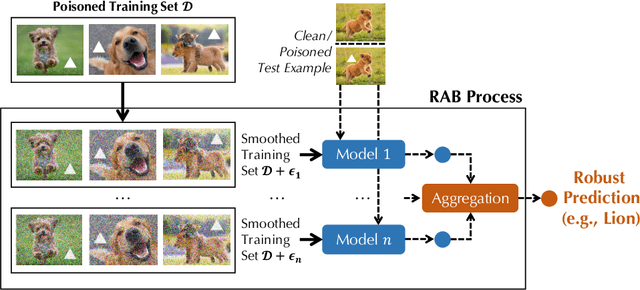

Recent studies have shown that deep neural networks (DNNs) are vulnerable to various attacks, including evasion attacks and poisoning attacks. On the defense side, there have been intensive interests in provable robustness against evasion attacks. In this paper, we focus on improving model robustness against more diverse threat models. Specifically, we provide the first unified framework using smoothing functional to certify the model robustness against general adversarial attacks. In particular, we propose the first robust training process RAB to certify against backdoor attacks. We theoretically prove the robustness bound for machine learning models based on the RAB training process, analyze the tightness of the robustness bound, as well as proposing different smoothing noise distributions such as Gaussian and Uniform distributions. Moreover, we evaluate the certified robustness of a family of "smoothed" DNNs which are trained in a differentially private fashion. In addition, we theoretically show that for simpler models such as K-nearest neighbor models, it is possible to train the robust smoothed models efficiently. For K=1, we propose an exact algorithm to smooth the training process, eliminating the need to sample from a noise distribution.Empirically, we conduct comprehensive experiments for different machine learning models such as DNNs, differentially private DNNs, and KNN models on MNIST, CIFAR-10 and ImageNet datasets to provide the first benchmark for certified robustness against backdoor attacks. In particular, we also evaluate KNN models on a spambase tabular dataset to demonstrate its advantages. Both the theoretic analysis for certified model robustness against arbitrary backdoors, and the comprehensive benchmark on diverse ML models and datasets would shed light on further robust learning strategies against training time or even general adversarial attacks on ML models.
End-to-end Robustness for Sensing-Reasoning Machine Learning Pipelines
Mar 06, 2020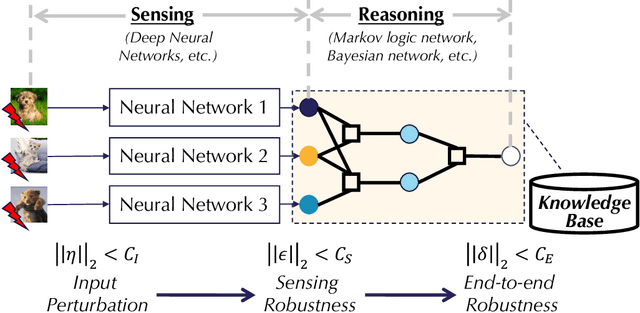
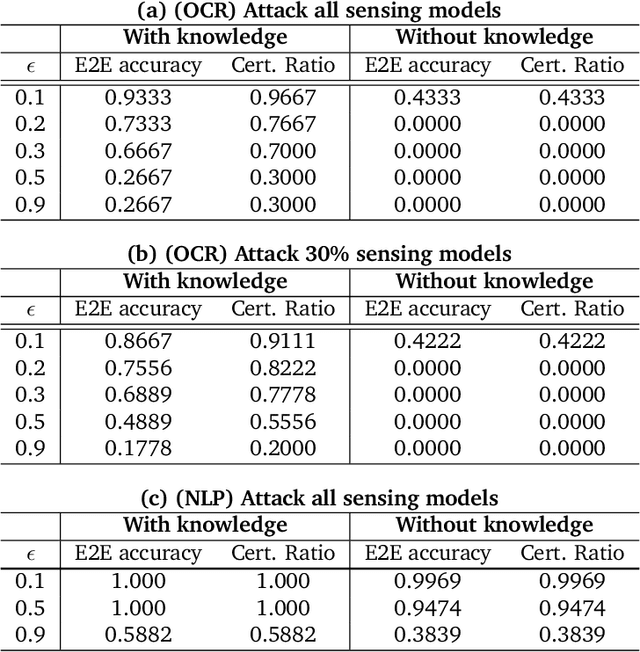
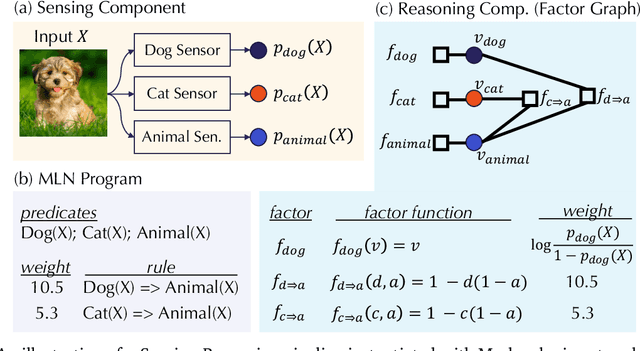
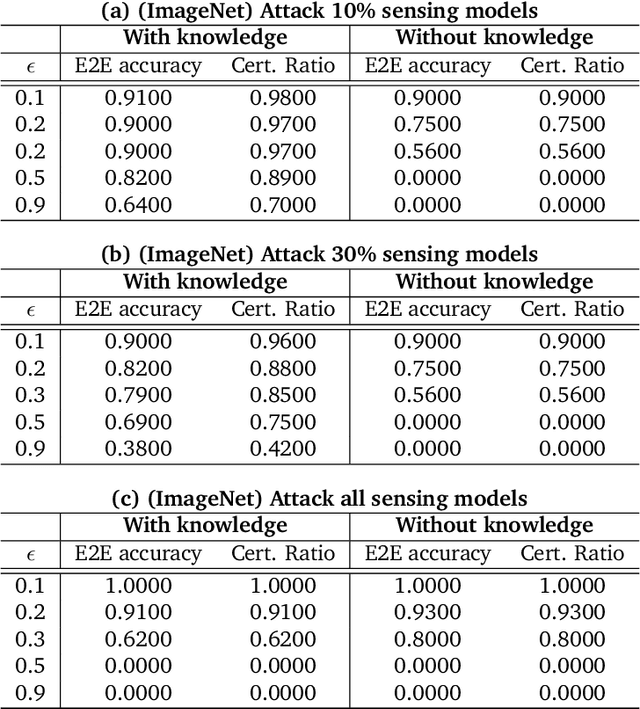
As machine learning (ML) being applied to many mission-critical scenarios, certifying ML model robustness becomes increasingly important. Many previous works focuses on the robustness of independent ML and ensemble models, and can only certify a very small magnitude of the adversarial perturbation. In this paper, we take a different viewpoint and improve learning robustness by going beyond independent ML and ensemble models. We aim at promoting the generic Sensing-Reasoning machine learning pipeline which contains both the sensing (e.g. deep neural networks) and reasoning (e.g. Markov logic networks (MLN)) components enriched with domain knowledge. Can domain knowledge help improve learning robustness? Can we formally certify the end-to-end robustness of such an ML pipeline? We first theoretically analyze the computational complexity of checking the provable robustness in the reasoning component. We then derive the provable robustness bound for several concrete reasoning components. We show that for reasoning components such as MLN and a specific family of Bayesian networks it is possible to certify the robustness of the whole pipeline even with a large magnitude of perturbation which cannot be certified by existing work. Finally, we conduct extensive real-world experiments on large scale datasets to evaluate the certified robustness for Sensing-Reasoning ML pipelines.
Data Science through the looking glass and what we found there
Dec 19, 2019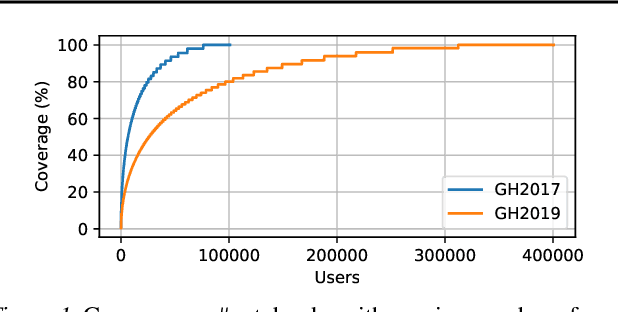
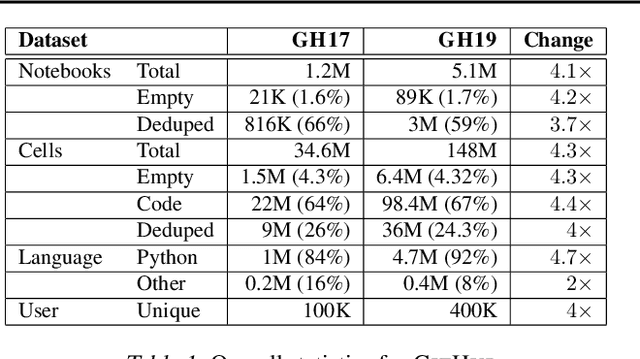
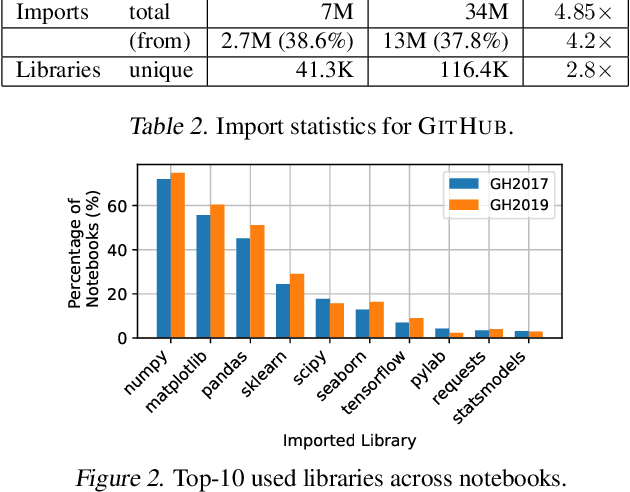
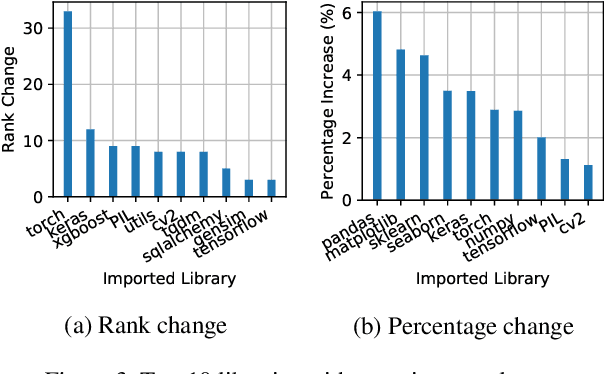
The recent success of machine learning (ML) has led to an explosive growth both in terms of new systems and algorithms built in industry and academia, and new applications built by an ever-growing community of data science (DS) practitioners. This quickly shifting panorama of technologies and applications is challenging for builders and practitioners alike to follow. In this paper, we set out to capture this panorama through a wide-angle lens, by performing the largest analysis of DS projects to date, focusing on questions that can help determine investments on either side. Specifically, we download and analyze: (a) over 6M Python notebooks publicly available on GITHUB, (b) over 2M enterprise DS pipelines developed within COMPANYX, and (c) the source code and metadata of over 900 releases from 12 important DS libraries. The analysis we perform ranges from coarse-grained statistical characterizations to analysis of library imports, pipelines, and comparative studies across datasets and time. We report a large number of measurements for our readers to interpret, and dare to draw a few (actionable, yet subjective) conclusions on (a) what systems builders should focus on to better serve practitioners, and (b) what technologies should practitioners bet on given current trends. We plan to automate this analysis and release associated tools and results periodically.
AutoML from Service Provider's Perspective: Multi-device, Multi-tenant Model Selection with GP-EI
Oct 28, 2018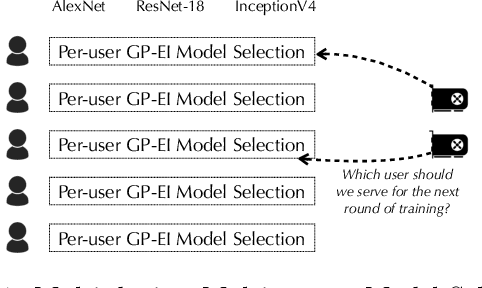
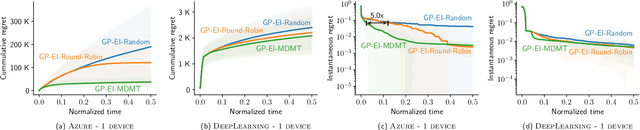
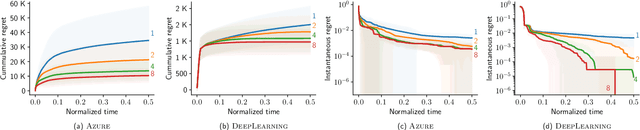
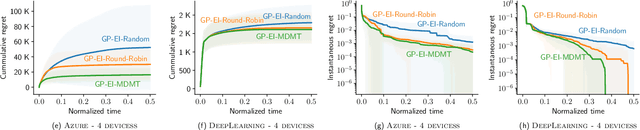
AutoML has become a popular service that is provided by most leading cloud service providers today. In this paper, we focus on the AutoML problem from the \emph{service provider's perspective}, motivated by the following practical consideration: When an AutoML service needs to serve {\em multiple users} with {\em multiple devices} at the same time, how can we allocate these devices to users in an efficient way? We focus on GP-EI, one of the most popular algorithms for automatic model selection and hyperparameter tuning, used by systems such as Google Vizer. The technical contribution of this paper is the first multi-device, multi-tenant algorithm for GP-EI that is aware of \emph{multiple} computation devices and multiple users sharing the same set of computation devices. Theoretically, given $N$ users and $M$ devices, we obtain a regret bound of $O((\text{\bf {MIU}}(T,K) + M)\frac{N^2}{M})$, where $\text{\bf {MIU}}(T,K)$ refers to the maximal incremental uncertainty up to time $T$ for the covariance matrix $K$. Empirically, we evaluate our algorithm on two applications of automatic model selection, and show that our algorithm significantly outperforms the strategy of serving users independently. Moreover, when multiple computation devices are available, we achieve near-linear speedup when the number of users is much larger than the number of devices.