 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Science through the looking glass and what we found there
Paper and Code
Dec 19, 2019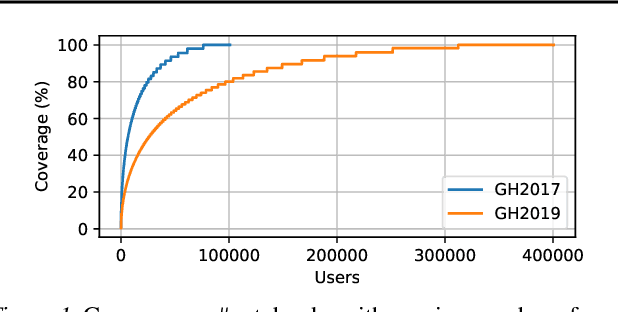
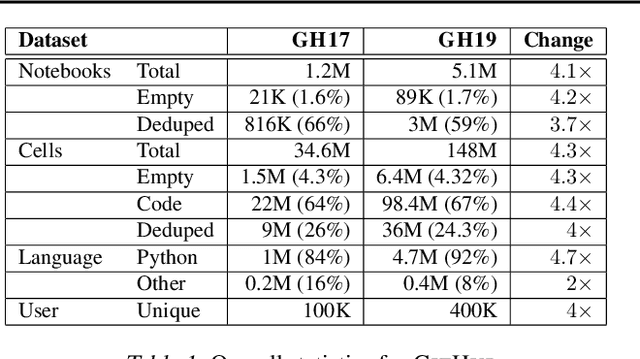
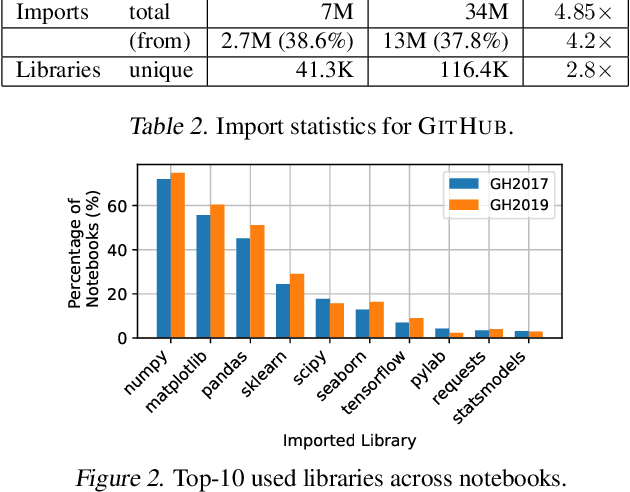
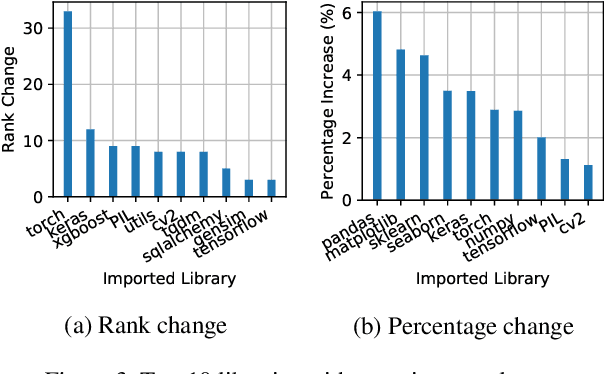
The recent success of machine learning (ML) has led to an explosive growth both in terms of new systems and algorithms built in industry and academia, and new applications built by an ever-growing community of data science (DS) practitioners. This quickly shifting panorama of technologies and applications is challenging for builders and practitioners alike to follow. In this paper, we set out to capture this panorama through a wide-angle lens, by performing the largest analysis of DS projects to date, focusing on questions that can help determine investments on either side. Specifically, we download and analyze: (a) over 6M Python notebooks publicly available on GITHUB, (b) over 2M enterprise DS pipelines developed within COMPANYX, and (c) the source code and metadata of over 900 releases from 12 important DS libraries. The analysis we perform ranges from coarse-grained statistical characterizations to analysis of library imports, pipelines, and comparative studies across datasets and time. We report a large number of measurements for our readers to interpret, and dare to draw a few (actionable, yet subjective) conclusions on (a) what systems builders should focus on to better serve practitioners, and (b) what technologies should practitioners bet on given current trends. We plan to automate this analysis and release associated tools and results periodically.