 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2I-VeRW: Part-level Fine-grained Perception for Text-to-Image Vehicle Retrieval
May 07, 2026Vehicle Re-identification (Re-ID) aims to retrieve the most similar image to a given query from images captured by non-overlapping cameras. Extending vehicle Re-ID from image-only queries to text-based queries enables retrieval in real-world scenarios where only a witness description of the target vehicle is available. In this paper, we propose PFCVR, a Part-level Fine-grained Cross-modal Vehicle Retrieval model for text-to-image vehicle re-identification. PFCVR constructs locally paired images and texts at the part level and introduces learnable part-query tokens that aggregate both part-specific and full-sentence context before aligning with visual part features. On top of this explicit local alignment, a bi-directional mask recovery module lets each modality reconstruct its masked content under the guidance of the other, implicitly bridging local correspondences into global feature alignment. Furthermore, we construct a new large-scale dataset called T2I-VeRW, which contains 14,668 images covering 1,796 vehicle identities with fine-grained part-level annotations. Experimental results on the T2I-VeRI dataset show that PFCVR achieves 29.2\% Rank-1 accuracy, improving over the best competing method by +3.7\% percentage points. On the newly proposed T2I-VeRW benchmark, PFCVR achieves 55.2\% Rank-1 accuracy, outperforming a comprehensive set of recent state-of-the-art methods. Source code will be released on https://github.com/Event-AHU/Neuromorphic_ReID
Vehicle-centric Perception via Multimodal Structured Pre-training
Dec 22, 2025Vehicle-centric perception plays a crucial role in many intelligent systems, including large-scale surveillance systems, intelligent transportation, and autonomous driving. Existing approaches lack effective learning of vehicle-related knowledge during pre-training, resulting in poor capability for modeling general vehicle perception representations. To handle this problem, we propose VehicleMAE-V2, a novel vehicle-centric pre-trained large model. By exploring and exploiting vehicle-related multimodal structured priors to guide the masked token reconstruction process, our approach can significantly enhance the model's capability to learn generalizable representations for vehicle-centric perception. Specifically, we design the Symmetry-guided Mask Module (SMM), Contour-guided Representation Module (CRM) and Semantics-guided Representation Module (SRM) to incorporate three kinds of structured priors into token reconstruction including symmetry, contour and semantics of vehicles respectively. SMM utilizes the vehicle symmetry constraints to avoid retaining symmetric patches and can thus select high-quality masked image patches and reduce information redundancy. CRM minimizes the probability distribution divergence between contour features and reconstructed features and can thus preserve holistic vehicle structure information during pixel-level reconstruction. SRM aligns image-text features through contrastive learning and cross-modal distillation to address the feature confusion caused by insufficient semantic understanding during masked reconstruction. To support the pre-training of VehicleMAE-V2, we construct Autobot4M, a large-scale dataset comprising approximately 4 million vehicle images and 12,693 text descriptions. Extensive experiments on five downstream tasks demonstrate the superior performance of VehicleMAE-V2.
Hierarchical Multi-Label Generation with Probabilistic Level-Constraint
Apr 30, 2025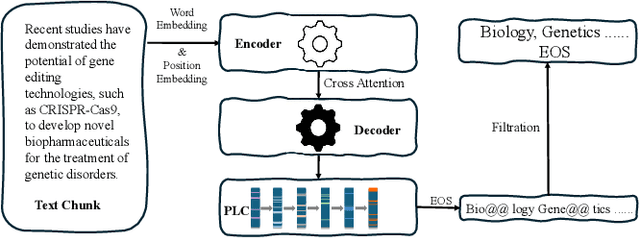
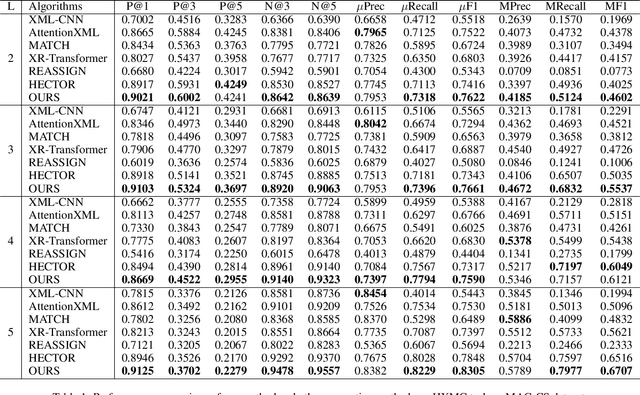
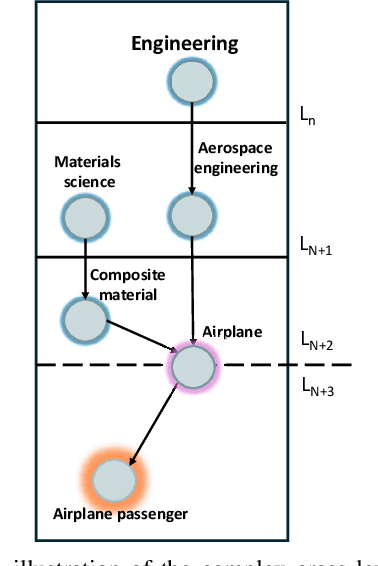
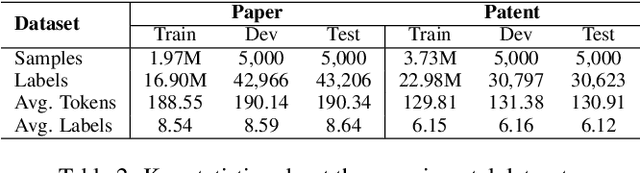
Hierarchical Extreme Multi-Label Classification poses greater difficulties compared to traditional multi-label classification because of the intricate hierarchical connections of labels within a domain-specific taxonomy and the substantial number of labels. Some of the prior research endeavors centered on classifying text through several ancillary stages such as the cluster algorithm and multiphase classification. Others made attempts to leverage the assistance of generative methods yet were unable to properly control the output of the generative model. We redefine the task from hierarchical multi-Label classification to Hierarchical Multi-Label Generation (HMG) and employ a generative framework with Probabilistic Level Constraints (PLC) to generate hierarchical labels within a specific taxonomy that have complex hierarchical relationships. The approach we proposed in this paper enables the framework to generate all relevant labels across levels for each document without relying on preliminary operations like clustering. Meanwhile, it can control the model output precisely in terms of count, length, and level aspects. Experiments demonstrate that our approach not only achieves a new SOTA performance in the HMG task, but also has a much better performance in constrained the output of model than previous research work.
CM3AE: A Unified RGB Frame and Event-Voxel/-Frame Pre-training Framework
Apr 17, 2025Event cameras have attracted increasing attention in recent years due to their advantages in high dynamic range, high temporal resolution, low power consumption, and low latency. Some researchers have begun exploring pre-training directly on event data. Nevertheless, these efforts often fail to establish strong connections with RGB frames, limiting their applicability in multi-modal fusion scenarios. To address these issues, we propose a novel CM3AE pre-training framework for the RGB-Event perception. This framework accepts multi-modalities/views of data as input, including RGB images, event images, and event voxels, providing robust support for both event-based and RGB-event fusion based downstream tasks. Specifically, we design a multi-modal fusion reconstruction module that reconstructs the original image from fused multi-modal features, explicitly enhancing the model's ability to aggregate cross-modal complementary information. Additionally, we employ a multi-modal contrastive learning strategy to align cross-modal feature representations in a shared latent space, which effectively enhances the model's capability for multi-modal understanding and capturing global dependencies. We construct a large-scale dataset containing 2,535,759 RGB-Event data pairs for the pre-training. Extensive experiments on five downstream tasks fully demonstrated the effectiveness of CM3AE. Source code and pre-trained models will be released on https://github.com/Event-AHU/CM3AE.
Benchmarking Biopharmaceuticals Retrieval-Augmented Generation Evaluation
Apr 15, 2025
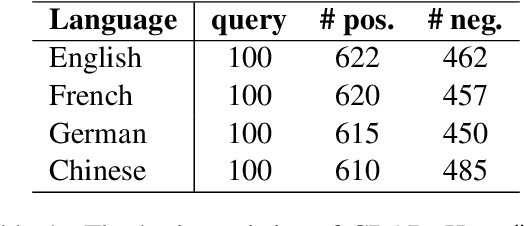
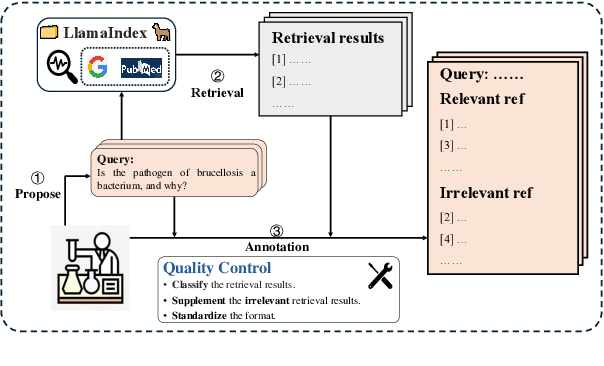
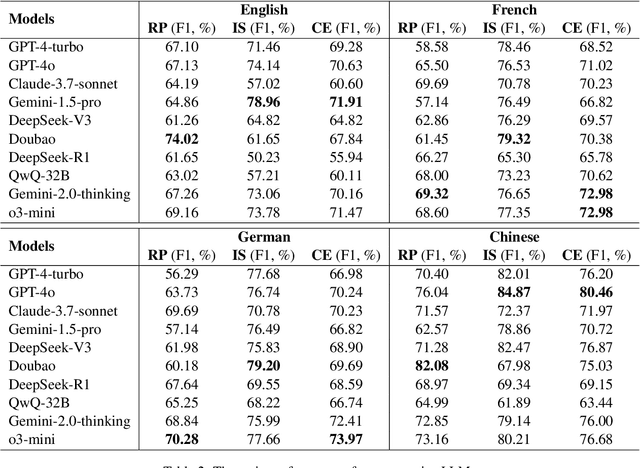
Recently, the application of the retrieval-augmented Large Language Models (LLMs) in specific domains has gained significant attention, especially in biopharmaceuticals. However, in this context, there is no benchmark specifically designed for biopharmaceuticals to evaluate LLMs. In this paper, we introduce the Biopharmaceuticals Retrieval-Augmented Generation Evaluation (BRAGE) , the first benchmark tailored for evaluating LLMs' Query and Reference Understanding Capability (QRUC) in the biopharmaceutical domain, available in English, French, German and Chinese. In addition, Traditional Question-Answering (QA) metrics like accuracy and exact match fall short in the open-ended retrieval-augmented QA scenarios. To address this, we propose a citation-based classification method to evaluate the QRUC of LLMs to understand the relationship between queries and references. We apply this method to evaluate the mainstream LLMs on BRAGE. Experimental results show that there is a significant gap in the biopharmaceutical QRUC of mainstream LLMs, and their QRUC needs to be improved.
Streamlining Biomedical Research with Specialized LLMs
Apr 15, 2025In this paper, we propose a novel system that integrates state-of-the-art, domain-specific large language models with advanced information retrieval techniques to deliver comprehensive and context-aware responses. Our approach facilitates seamless interaction among diverse components, enabling cross-validation of outputs to produce accurate, high-quality responses enriched with relevant data, images, tables, and other modalities. We demonstrate the system's capability to enhance response precision by leveraging a robust question-answering model, significantly improving the quality of dialogue generation. The system provides an accessible platform for real-time, high-fidelity interactions, allowing users to benefit from efficient human-computer interaction, precise retrieval, and simultaneous access to a wide range of literature and data. This dramatically improves the research efficiency of professionals in the biomedical and pharmaceutical domains and facilitates faster, more informed decision-making throughout the R\&D process. Furthermore, the system proposed in this paper is available at https://synapse-chat.patsnap.com.
FDDet: Frequency-Decoupling for Boundary Refinement in Temporal Action Detection
Apr 01, 2025
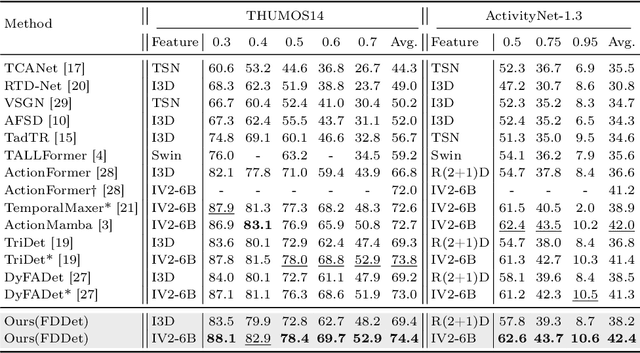
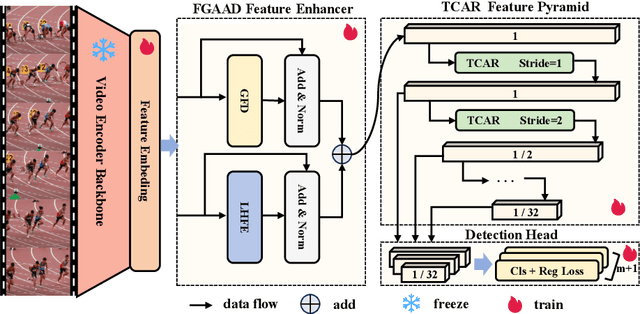

Temporal action detection aims to locate and classify actions in untrimmed videos. While recent works focus on designing powerful feature processors for pre-trained representations, they often overlook the inherent noise and redundancy within these features. Large-scale pre-trained video encoders tend to introduce background clutter and irrelevant semantics, leading to context confusion and imprecise boundaries. To address this, we propose a frequency-aware decoupling network that improves action discriminability by filtering out noisy semantics captured by pre-trained models. Specifically, we introduce an adaptive temporal decoupling scheme that suppresses irrelevant information while preserving fine-grained atomic action details, yielding more task-specific representations. In addition, we enhance inter-frame modeling by capturing temporal variations to better distinguish actions from background redundancy. Furthermore, we present a long-short-term category-aware relation network that jointly models local transitions and long-range dependencies, improving localization precision. The refined atomic features and frequency-guided dynamics are fed into a standard detection head to produce accurate action predictions. Extensive experiments on THUMOS14, HACS, and ActivityNet-1.3 show that our method, powered by InternVideo2-6B features, achieves state-of-the-art performance on temporal action detection benchmarks.
Large Language Model Guided Progressive Feature Alignment for Multimodal UAV Object Detection
Mar 10, 2025



Existing multimodal UAV object detection methods often overlook the impact of semantic gaps between modalities, which makes it difficult to achieve accurate semantic and spatial alignments, limiting detection performance. To address this problem, we propose a Large Language Model (LLM) guided Progressive feature Alignment Network called LPANet, which leverages the semantic features extracted from a large language model to guide the progressive semantic and spatial alignment between modalities for multimodal UAV object detection. To employ the powerful semantic representation of LLM, we generate the fine-grained text descriptions of each object category by ChatGPT and then extract the semantic features using the large language model MPNet. Based on the semantic features, we guide the semantic and spatial alignments in a progressive manner as follows. First, we design the Semantic Alignment Module (SAM) to pull the semantic features and multimodal visual features of each object closer, alleviating the semantic differences of objects between modalities. Second, we design the Explicit Spatial alignment Module (ESM) by integrating the semantic relations into the estimation of feature-level offsets, alleviating the coarse spatial misalignment between modalities. Finally, we design the Implicit Spatial alignment Module (ISM), which leverages the cross-modal correlations to aggregate key features from neighboring regions to achieve implicit spatial alignment. Comprehensive experiments on two public multimodal UAV object detection datasets demonstrate that our approach outperforms state-of-the-art multimodal UAV object detectors.
XiHeFusion: Harnessing Large Language Models for Science Communication in Nuclear Fusion
Feb 08, 2025



Nuclear fusion is one of the most promising ways for humans to obtain infinite energy. Currently, with the rapid development of artificial intelligence, the mission of nuclear fusion has also entered a critical period of its development. How to let more people to understand nuclear fusion and join in its research is one of the effective means to accelerate the implementation of fusion. This paper proposes the first large model in the field of nuclear fusion, XiHeFusion, which is obtained through supervised fine-tuning based on the open-source large model Qwen2.5-14B. We have collected multi-source knowledge about nuclear fusion tasks to support the training of this model, including the common crawl, eBooks, arXiv, dissertation, etc. After the model has mastered the knowledge of the nuclear fusion field, we further used the chain of thought to enhance its logical reasoning ability, making XiHeFusion able to provide more accurate and logical answers. In addition, we propose a test questionnaire containing 180+ questions to assess the conversational ability of this science popularization large model. Extensive experimental results show that our nuclear fusion dialogue model, XiHeFusion, can perform well in answering science popularization knowledge. The pre-trained XiHeFusion model is released on https://github.com/Event-AHU/XiHeFusion.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.