 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Robot Geometric Task-and-Motion Planning for Collaborative Manipulation Tasks
Oct 13, 2023We address multi-robot geometric task-and-motion planning (MR-GTAMP) problems in synchronous, monotone setups. The goal of the MR-GTAMP problem is to move objects with multiple robots to goal regions in the presence of other movable objects. We focus on collaborative manipulation tasks where the robots have to adopt intelligent collaboration strategies to be successful and effective, i.e., decide which robot should move which objects to which positions, and perform collaborative actions, such as handovers. To endow robots with these collaboration capabilities, we propose to first collect occlusion and reachability information for each robot by calling motion-planning algorithms. We then propose a method that uses the collected information to build a graph structure which captures the precedence of the manipulations of different objects and supports the implementation of a mixed-integer program to guide the search for highly effective collaborative task-and-motion plans. The search process for collaborative task-and-motion plans is based on a Monte-Carlo Tree Search (MCTS) exploration strategy to achieve exploration-exploitation balance. We evaluate our framework in two challenging MR-GTAMP domains and show that it outperforms two state-of-the-art baselines with respect to the planning time, the resulting plan length and the number of objects moved. We also show that our framework can be applied to underground mining operations where a robotic arm needs to coordinate with an autonomous roof bolter. We demonstrate plan execution in two roof-bolting scenarios both in simulation and on robots.
Progressive Open-Domain Response Generation with Multiple Controllable Attributes
Jun 07, 2021
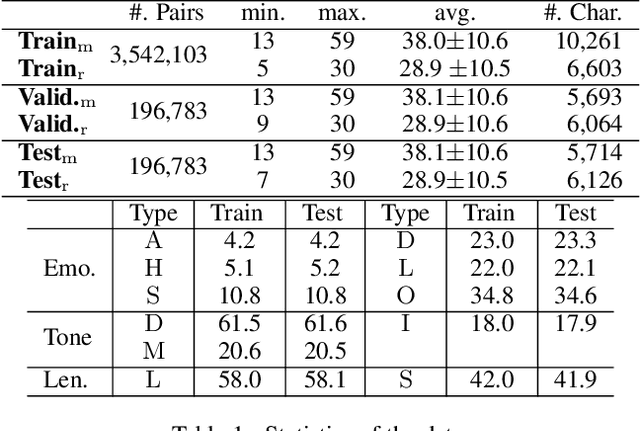
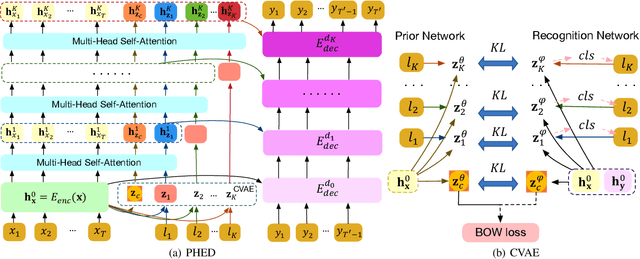
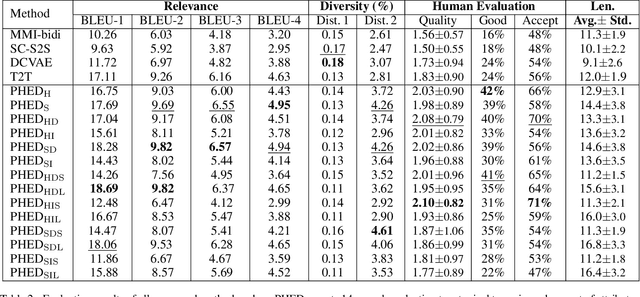
It is desirable to include more controllable attributes to enhance the diversity of generated responses in open-domain dialogue systems. However, existing methods can generate responses with only one controllable attribute or lack a flexible way to generate them with multiple controllable attributes. In this paper, we propose a Progressively trained Hierarchical Encoder-Decoder (PHED) to tackle this task. More specifically, PHED deploys Conditional Variational AutoEncoder (CVAE) on Transformer to include one aspect of attributes at one stage. A vital characteristic of the CVAE is to separate the latent variables at each stage into two types: a global variable capturing the common semantic features and a specific variable absorbing the attribute information at that stage. PHED then couples the CVAE latent variables with the Transformer encoder and is trained by minimizing a newly derived ELBO and controlled losses to produce the next stage's input and produce responses as required. Finally, we conduct extensive evaluations to show that PHED significantly outperforms the state-of-the-art neural generation models and produces more diverse responses as expected.
A Stochastic Time Series Model for Predicting Financial Trends using NLP
Feb 02, 2021

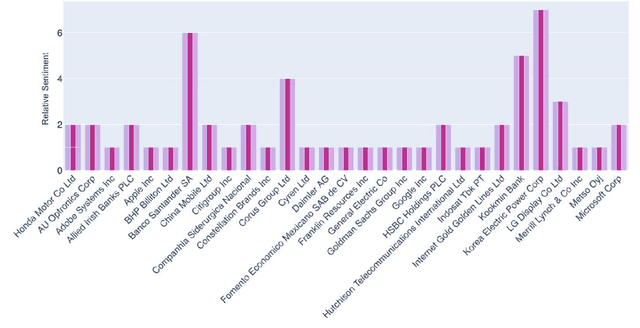
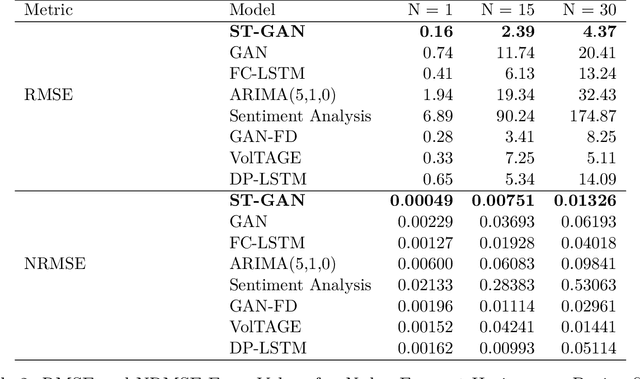
Stock price forecasting is a highly complex and vitally important field of research. Recent advancements in deep neural network technology allow researchers to develop highly accurate models to predict financial trends. We propose a novel deep learning model called ST-GAN, or Stochastic Time-series Generative Adversarial Network, that analyzes both financial news texts and financial numerical data to predict stock trends. We utilize cutting-edge technology like the Generative Adversarial Network (GAN) to learn the correlations among textual and numerical data over time. We develop a new method of training a time-series GAN directly using the learned representations of Naive Bayes' sentiment analysis on financial text data alongside technical indicators from numerical data. Our experimental results show significant improvement over various existing models and prior research on deep neural networks for stock price forecasting.
P-MCGS: Parallel Monte Carlo Acyclic Graph Search
Oct 28, 2018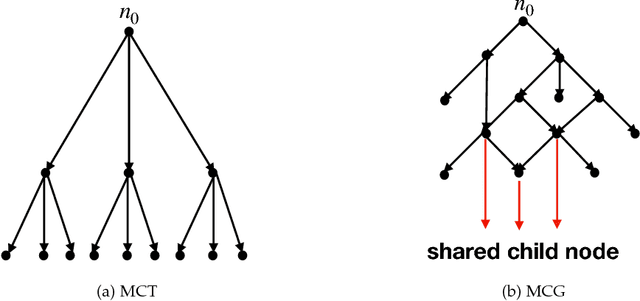
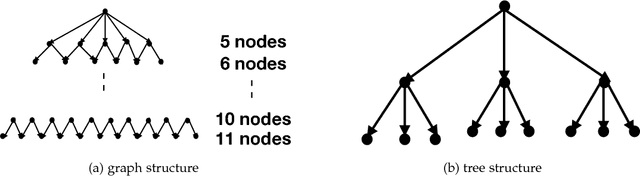
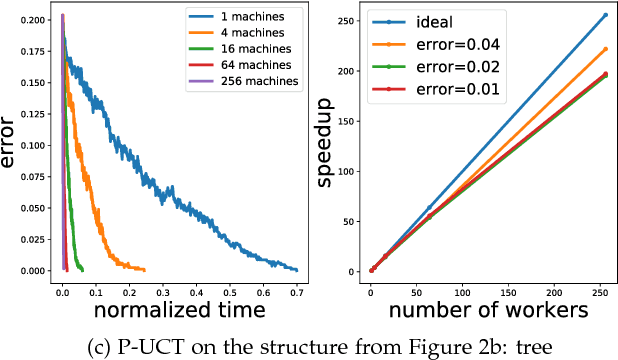
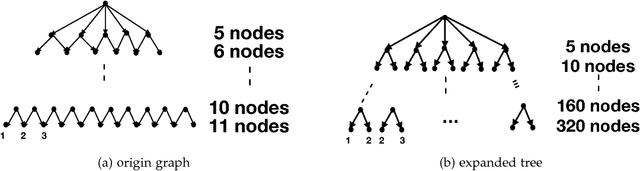
Recently, there have been great interests in Monte Carlo Tree Search (MCTS) in AI research. Although the sequential version of MCTS has been studied widely, its parallel counterpart still lacks systematic study. This leads us to the following questions: \emph{how to design efficient parallel MCTS (or more general cases) algorithms with rigorous theoretical guarantee? Is it possible to achieve linear speedup?} In this paper, we consider the search problem on a more general acyclic one-root graph (namely, Monte Carlo Graph Search (MCGS)), which generalizes MCTS. We develop a parallel algorithm (P-MCGS) to assign multiple workers to investigate appropriate leaf nodes simultaneously. Our analysis shows that P-MCGS algorithm achieves linear speedup and that the sample complexity is comparable to its sequential counterpart.
AutoML from Service Provider's Perspective: Multi-device, Multi-tenant Model Selection with GP-EI
Oct 28, 2018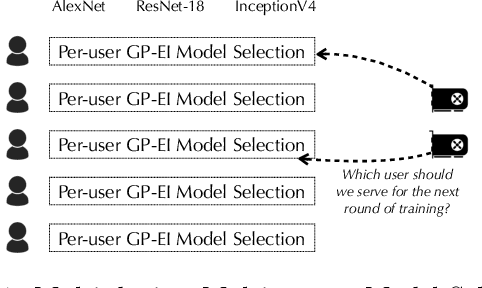
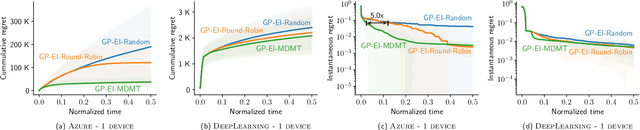
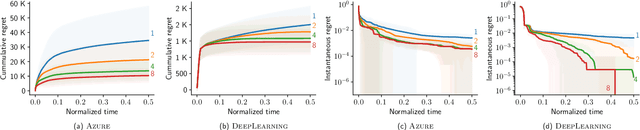
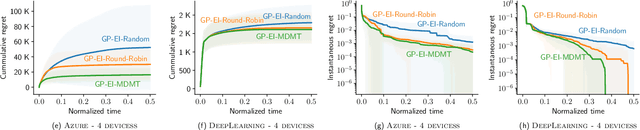
AutoML has become a popular service that is provided by most leading cloud service providers today. In this paper, we focus on the AutoML problem from the \emph{service provider's perspective}, motivated by the following practical consideration: When an AutoML service needs to serve {\em multiple users} with {\em multiple devices} at the same time, how can we allocate these devices to users in an efficient way? We focus on GP-EI, one of the most popular algorithms for automatic model selection and hyperparameter tuning, used by systems such as Google Vizer. The technical contribution of this paper is the first multi-device, multi-tenant algorithm for GP-EI that is aware of \emph{multiple} computation devices and multiple users sharing the same set of computation devices. Theoretically, given $N$ users and $M$ devices, we obtain a regret bound of $O((\text{\bf {MIU}}(T,K) + M)\frac{N^2}{M})$, where $\text{\bf {MIU}}(T,K)$ refers to the maximal incremental uncertainty up to time $T$ for the covariance matrix $K$. Empirically, we evaluate our algorithm on two applications of automatic model selection, and show that our algorithm significantly outperforms the strategy of serving users independently. Moreover, when multiple computation devices are available, we achieve near-linear speedup when the number of users is much larger than the number of devices.
Ease.ml: Towards Multi-tenant Resource Sharing for Machine Learning Workloads
Aug 24, 2017
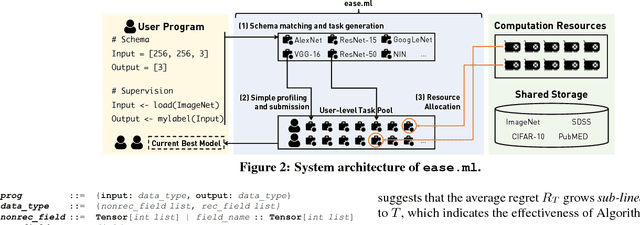
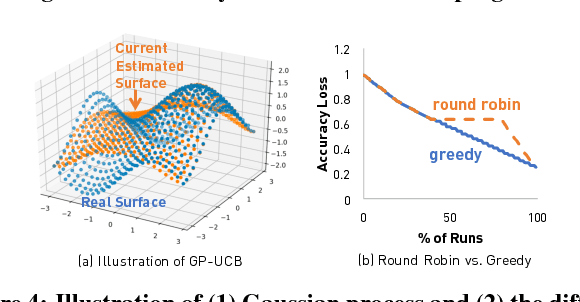
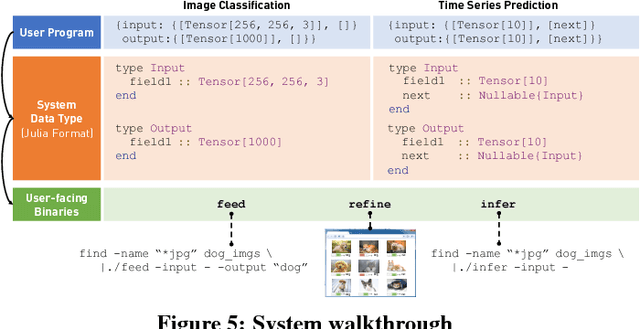
We present ease.ml, a declarative machine learning service platform we built to support more than ten research groups outside the computer science departments at ETH Zurich for their machine learning needs. With ease.ml, a user defines the high-level schema of a machine learning application and submits the task via a Web interface. The system automatically deals with the rest, such as model selection and data movement. In this paper, we describe the ease.ml architecture and focus on a novel technical problem introduced by ease.ml regarding resource allocation. We ask, as a "service provider" that manages a shared cluster of machines among all our users running machine learning workloads, what is the resource allocation strategy that maximizes the global satisfaction of all our users? Resource allocation is a critical yet subtle issue in this multi-tenant scenario, as we have to balance between efficiency and fairness. We first formalize the problem that we call multi-tenant model selection, aiming for minimizing the total regret of all users running automatic model selection tasks. We then develop a novel algorithm that combines multi-armed bandits with Bayesian optimization and prove a regret bound under the multi-tenant setting. Finally, we report our evaluation of ease.ml on synthetic data and on one service we are providing to our users, namely, image classification with deep neural networks. Our experimental evaluation results show that our proposed solution can be up to 9.8x faster in achieving the same global quality for all users as the two popular heuristics used by our users before ease.ml.