 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Diversity-Enhanced and Constraints-Relaxed Augmentation for Low-Resource Classification
Sep 24, 2021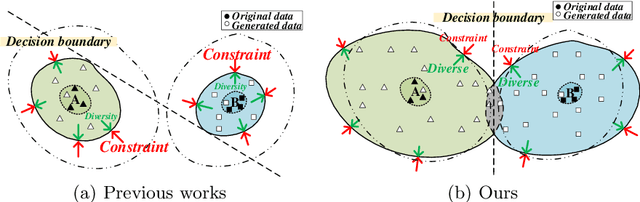
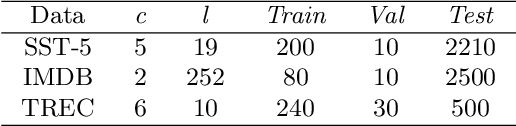
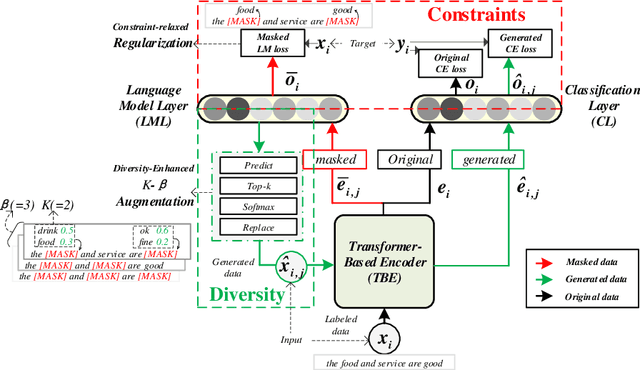
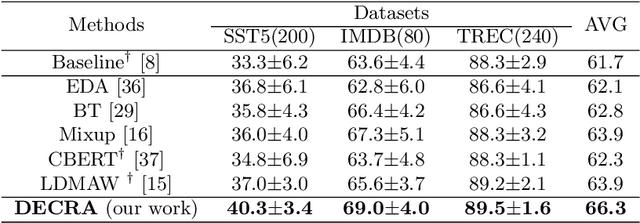
Data augmentation (DA) aims to generate constrained and diversified data to improve classifiers in Low-Resource Classification (LRC). Previous studies mostly use a fine-tuned Language Model (LM) to strengthen the constraints but ignore the fact that the potential of diversity could improve the effectiveness of generated data. In LRC, strong constraints but weak diversity in DA result in the poor generalization ability of classifiers. To address this dilemma, we propose a {D}iversity-{E}nhanced and {C}onstraints-\{R}elaxed {A}ugmentation (DECRA). Our DECRA has two essential components on top of a transformer-based backbone model. 1) A k-beta augmentation, an essential component of DECRA, is proposed to enhance the diversity in generating constrained data. It expands the changing scope and improves the degree of complexity of the generated data. 2) A masked language model loss, instead of fine-tuning, is used as a regularization. It relaxes constraints so that the classifier can be trained with more scattered generated data. The combination of these two components generates data that can reach or approach category boundaries and hence help the classifier generalize better. We evaluate our DECRA on three public benchmark datasets under low-resource settings. Extensive experiments demonstrate that our DECRA outperforms state-of-the-art approaches by 3.8% in the overall score.
RefBERT: Compressing BERT by Referencing to Pre-computed Representations
Jun 11, 2021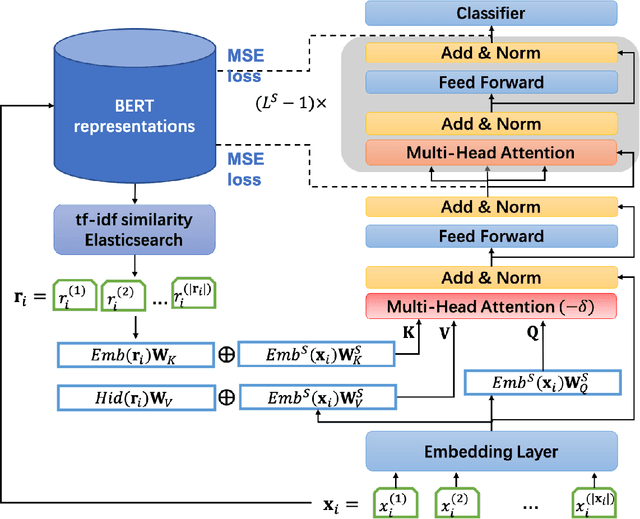
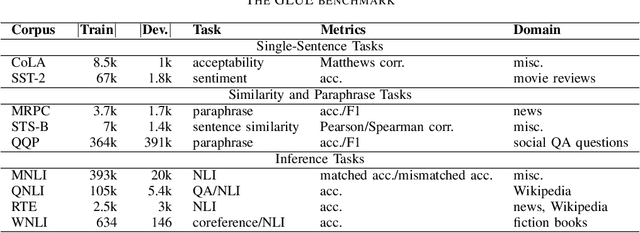

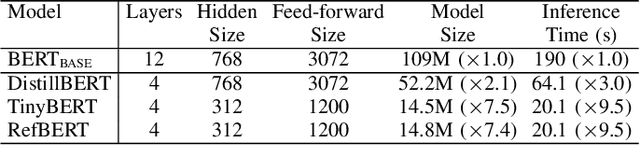
Recently developed large pre-trained language models, e.g., BERT, have achieved remarkable performance in many downstream natural language processing applications. These pre-trained language models often contain hundreds of millions of parameters and suffer from high computation and latency in real-world applications. It is desirable to reduce the computation overhead of the models for fast training and inference while keeping the model performance in downstream applications. Several lines of work utilize knowledge distillation to compress the teacher model to a smaller student model. However, they usually discard the teacher's knowledge when in inference. Differently, in this paper, we propose RefBERT to leverage the knowledge learned from the teacher, i.e., facilitating the pre-computed BERT representation on the reference sample and compressing BERT into a smaller student model. To guarantee our proposal, we provide theoretical justification on the loss function and the usage of reference samples. Significantly, the theoretical result shows that including the pre-computed teacher's representations on the reference samples indeed increases the mutual information in learning the student model. Finally, we conduct the empirical evaluation and show that our RefBERT can beat the vanilla TinyBERT over 8.1\% and achieves more than 94\% of the performance of $\BERTBASE$ on the GLUE benchmark. Meanwhile, RefBERT is 7.4x smaller and 9.5x faster on inference than BERT$_{\rm BASE}$.
Progressive Open-Domain Response Generation with Multiple Controllable Attributes
Jun 07, 2021
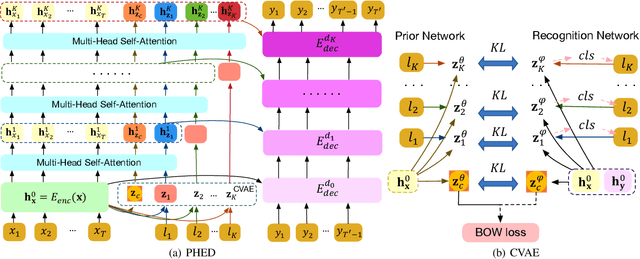
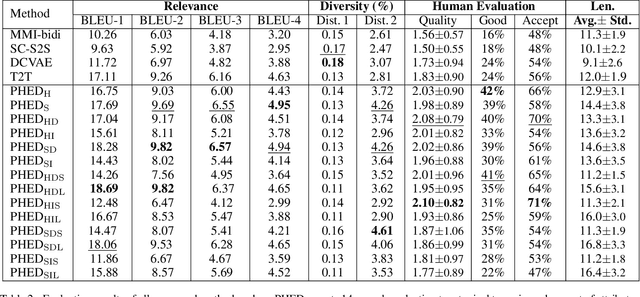
It is desirable to include more controllable attributes to enhance the diversity of generated responses in open-domain dialogue systems. However, existing methods can generate responses with only one controllable attribute or lack a flexible way to generate them with multiple controllable attributes. In this paper, we propose a Progressively trained Hierarchical Encoder-Decoder (PHED) to tackle this task. More specifically, PHED deploys Conditional Variational AutoEncoder (CVAE) on Transformer to include one aspect of attributes at one stage. A vital characteristic of the CVAE is to separate the latent variables at each stage into two types: a global variable capturing the common semantic features and a specific variable absorbing the attribute information at that stage. PHED then couples the CVAE latent variables with the Transformer encoder and is trained by minimizing a newly derived ELBO and controlled losses to produce the next stage's input and produce responses as required. Finally, we conduct extensive evaluations to show that PHED significantly outperforms the state-of-the-art neural generation models and produces more diverse responses as expected.
PALI at SemEval-2021 Task 2: Fine-Tune XLM-RoBERTa for Word in Context Disambiguation
Apr 21, 2021

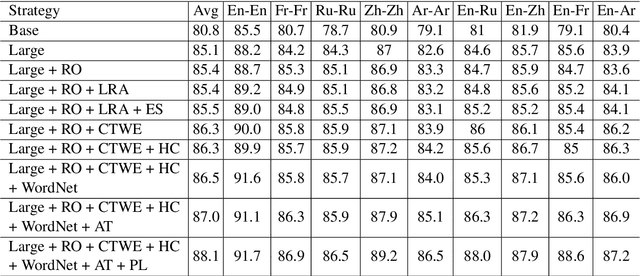
This paper presents the PALI team's winning system for SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation. We fine-tune XLM-RoBERTa model to solve the task of word in context disambiguation, i.e., to determine whether the target word in the two contexts contains the same meaning or not. In the implementation, we first specifically design an input tag to emphasize the target word in the contexts. Second, we construct a new vector on the fine-tuned embeddings from XLM-RoBERTa and feed it to a fully-connected network to output the probability of whether the target word in the context has the same meaning or not. The new vector is attained by concatenating the embedding of the [CLS] token and the embeddings of the target word in the contexts. In training, we explore several tricks, such as the Ranger optimizer, data augmentation, and adversarial training, to improve the model prediction. Consequently, we attain first place in all four cross-lingual tasks.
Emotion Dynamics Modeling via BERT
Apr 21, 2021


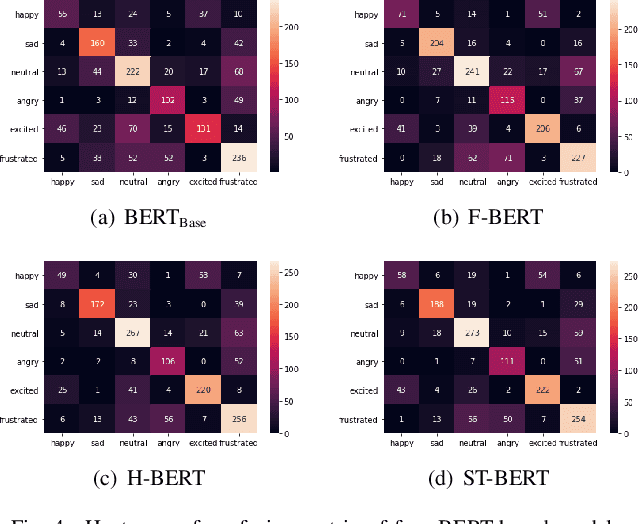
Emotion dynamics modeling is a significant task in emotion recognition in conversation. It aims to predict conversational emotions when building empathetic dialogue systems. Existing studies mainly develop models based on Recurrent Neural Networks (RNNs). They cannot benefit from the power of the recently-developed pre-training strategies for better token representation learning in conversations. More seriously, it is hard to distinguish the dependency of interlocutors and the emotional influence among interlocutors by simply assembling the features on top of RNNs. In this paper, we develop a series of BERT-based models to specifically capture the inter-interlocutor and intra-interlocutor dependencies of the conversational emotion dynamics. Concretely, we first substitute BERT for RNNs to enrich the token representations. Then, a Flat-structured BERT (F-BERT) is applied to link up utterances in a conversation directly, and a Hierarchically-structured BERT (H-BERT) is employed to distinguish the interlocutors when linking up utterances. More importantly, a Spatial-Temporal-structured BERT, namely ST-BERT, is proposed to further determine the emotional influence among interlocutors. Finally, we conduct extensive experiments on two popular emotion recognition in conversation benchmark datasets and demonstrate that our proposed models can attain around 5\% and 10\% improvement over the state-of-the-art baselines, respectively.
KGSynNet: A Novel Entity Synonyms Discovery Framework with Knowledge Graph
Apr 01, 2021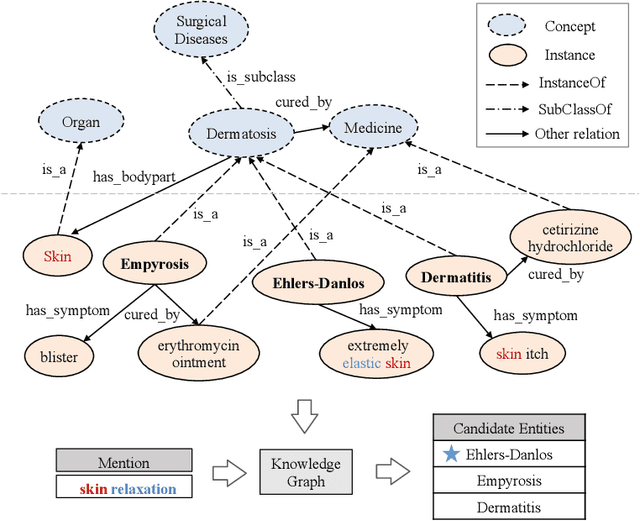
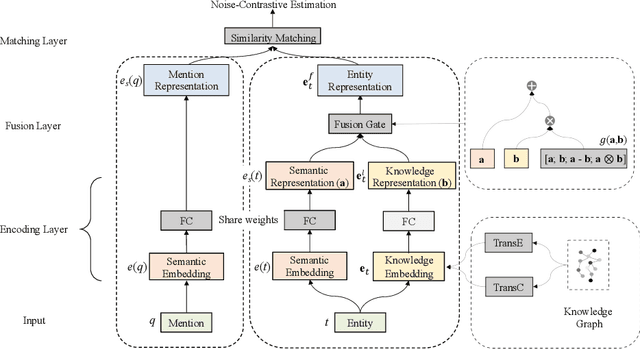
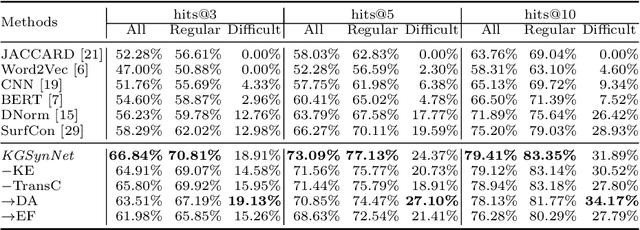
Entity synonyms discovery is crucial for entity-leveraging applications. However, existing studies suffer from several critical issues: (1) the input mentions may be out-of-vocabulary (OOV) and may come from a different semantic space of the entities; (2) the connection between mentions and entities may be hidden and cannot be established by surface matching; and (3) some entities rarely appear due to the long-tail effect. To tackle these challenges, we facilitate knowledge graphs and propose a novel entity synonyms discovery framework, named \emph{KGSynNet}. Specifically, we pre-train subword embeddings for mentions and entities using a large-scale domain-specific corpus while learning the knowledge embeddings of entities via a joint TransC-TransE model. More importantly, to obtain a comprehensive representation of entities, we employ a specifically designed \emph{fusion gate} to adaptively absorb the entities' knowledge information into their semantic features. We conduct extensive experiments to demonstrate the effectiveness of our \emph{KGSynNet} in leveraging the knowledge graph. The experimental results show that the \emph{KGSynNet} improves the state-of-the-art methods by 14.7\% in terms of hits@3 in the offline evaluation and outperforms the BERT model by 8.3\% in the positive feedback rate of an online A/B test on the entity linking module of a question answering system.
Automatic Intent-Slot Induction for Dialogue Systems
Mar 16, 2021

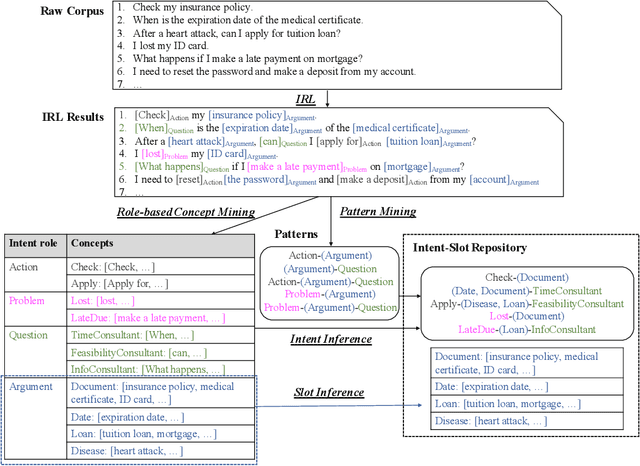

Automatically and accurately identifying user intents and filling the associated slots from their spoken language are critical to the success of dialogue systems. Traditional methods require manually defining the DOMAIN-INTENT-SLOT schema and asking many domain experts to annotate the corresponding utterances, upon which neural models are trained. This procedure brings the challenges of information sharing hindering, out-of-schema, or data sparsity in open-domain dialogue systems. To tackle these challenges, we explore a new task of {\em automatic intent-slot induction} and propose a novel domain-independent tool. That is, we design a coarse-to-fine three-step procedure including Role-labeling, Concept-mining, And Pattern-mining (RCAP): (1) role-labeling: extracting keyphrases from users' utterances and classifying them into a quadruple of coarsely-defined intent-roles via sequence labeling; (2) concept-mining: clustering the extracted intent-role mentions and naming them into abstract fine-grained concepts; (3) pattern-mining: applying the Apriori algorithm to mine intent-role patterns and automatically inferring the intent-slot using these coarse-grained intent-role labels and fine-grained concepts. Empirical evaluations on both real-world in-domain and out-of-domain datasets show that: (1) our RCAP can generate satisfactory SLU schema and outperforms the state-of-the-art supervised learning method; (2) our RCAP can be directly applied to out-of-domain datasets and gain at least 76\% improvement of F1-score on intent detection and 41\% improvement of F1-score on slot filling; (3) our RCAP exhibits its power in generic intent-slot extractions with less manual effort, which opens pathways for schema induction on new domains and unseen intent-slot discovery for generalizable dialogue systems.
Mention Extraction and Linking for SQL Query Generation
Dec 18, 2020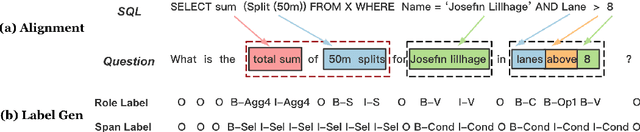

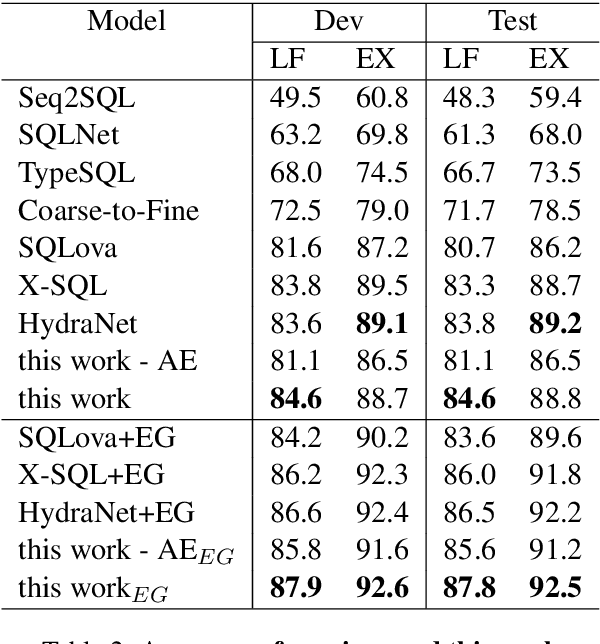

On the WikiSQL benchmark, state-of-the-art text-to-SQL systems typically take a slot-filling approach by building several dedicated models for each type of slots. Such modularized systems are not only complex butalso of limited capacity for capturing inter-dependencies among SQL clauses. To solve these problems, this paper proposes a novel extraction-linking approach, where a unified extractor recognizes all types of slot mentions appearing in the question sentence before a linker maps the recognized columns to the table schema to generate executable SQL queries. Trained with automatically generated annotations, the proposed method achieves the first place on the WikiSQL benchmark.
DialogueTRM: Exploring the Intra- and Inter-Modal Emotional Behaviors in the Conversation
Oct 15, 2020

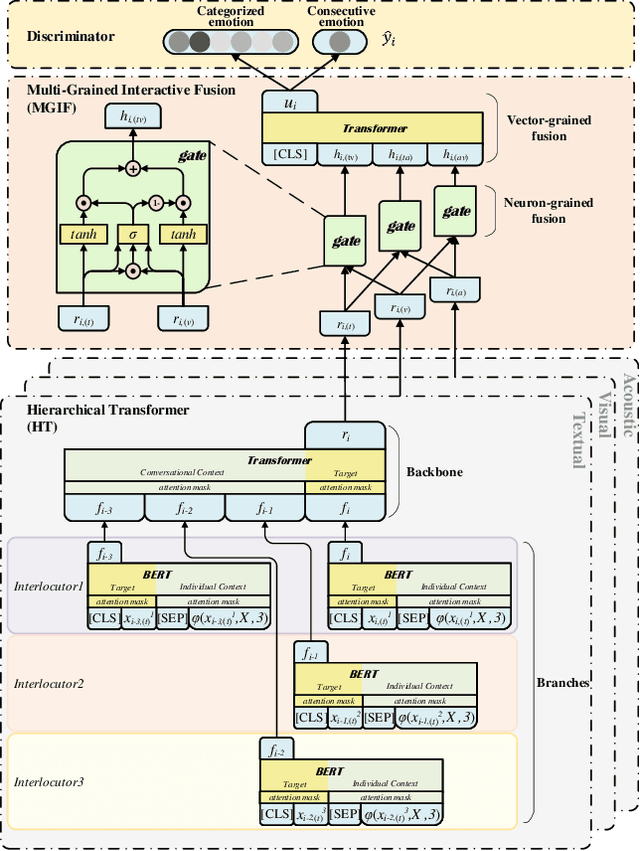
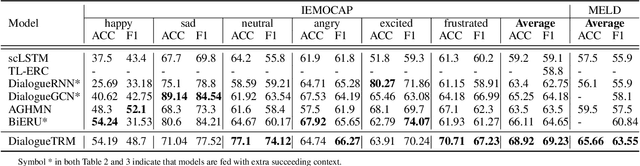
Emotion Recognition in Conversations (ERC) is essential for building empathetic human-machine systems. Existing studies on ERC primarily focus on summarizing the context information in a conversation, however, ignoring the differentiated emotional behaviors within and across different modalities. Designing appropriate strategies that fit the differentiated multi-modal emotional behaviors can produce more accurate emotional predictions. Thus, we propose the DialogueTransformer to explore the differentiated emotional behaviors from the intra- and inter-modal perspectives. For intra-modal, we construct a novel Hierarchical Transformer that can easily switch between sequential and feed-forward structures according to the differentiated context preference within each modality. For inter-modal, we constitute a novel Multi-Grained Interactive Fusion that applies both neuron- and vector-grained feature interactions to learn the differentiated contributions across all modalities. Experimental results show that DialogueTRM outperforms the state-of-the-art by a significant margin on three benchmark datasets.
Hierarchical Context Enhanced Multi-Domain Dialogue System for Multi-domain Task Completion
Mar 03, 2020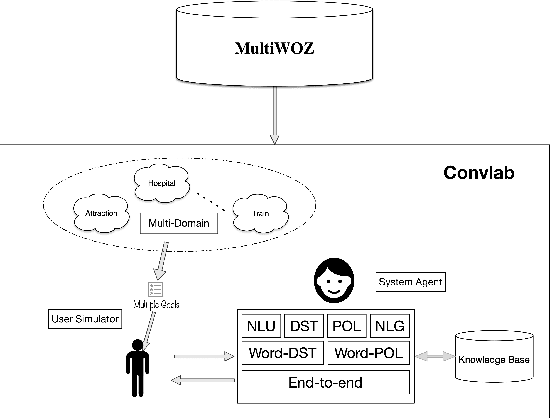
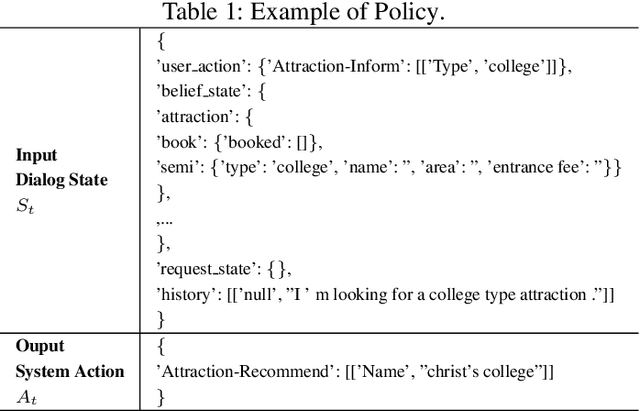
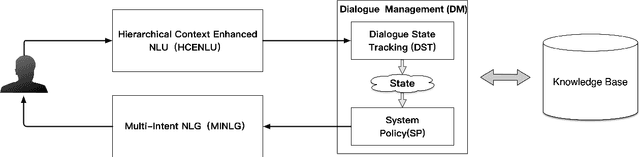

Task 1 of the DSTC8-track1 challenge aims to develop an end-to-end multi-domain dialogue system to accomplish complex users' goals under tourist information desk settings. This paper describes our submitted solution, Hierarchical Context Enhanced Dialogue System (HCEDS), for this task. The main motivation of our system is to comprehensively explore the potential of hierarchical context for sufficiently understanding complex dialogues. More specifically, we apply BERT to capture token-level information and employ the attention mechanism to capture sentence-level information. The results listed in the leaderboard show that our system achieves first place in automatic evaluation and the second place in human evaluation.