 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
X-Driver: Explainable Autonomous Driving with Vision-Language Models
May 08, 2025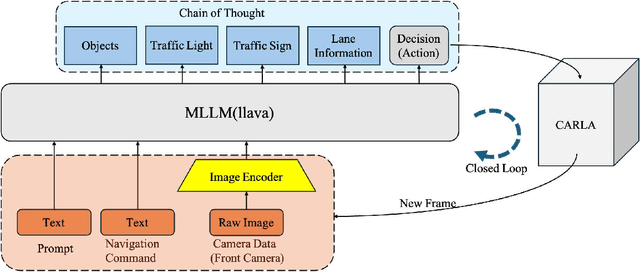
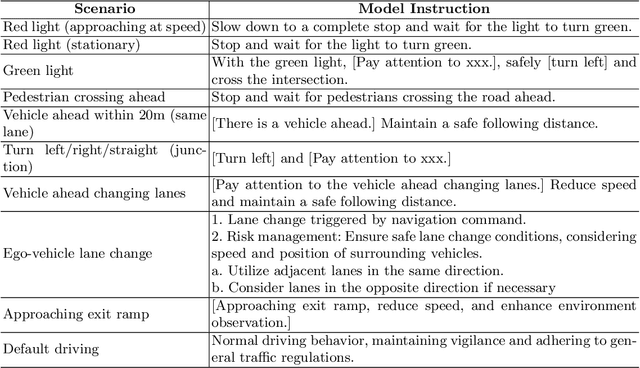
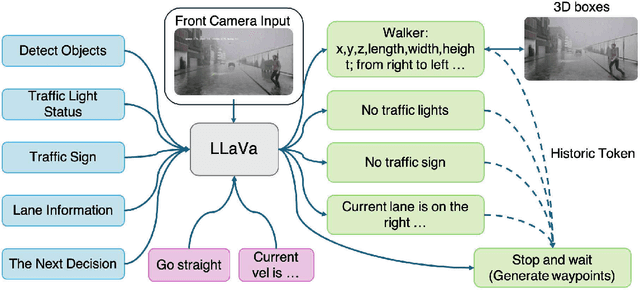

End-to-end autonomous driving has advanced significantly, offering benefits such as system simplicity and stronger driving performance in both open-loop and closed-loop settings than conventional pipelines. However, existing frameworks still suffer from low success rates in closed-loop evaluations, highlighting their limitations in real-world deployment. In this paper, we introduce X-Driver, a unified multi-modal large language models(MLLMs) framework designed for closed-loop autonomous driving, leveraging Chain-of-Thought(CoT) and autoregressive modeling to enhance perception and decision-making. We validate X-Driver across multiple autonomous driving tasks using public benchmarks in CARLA simulation environment, including Bench2Drive[6]. Our experimental results demonstrate superior closed-loop performance, surpassing the current state-of-the-art(SOTA) while improving the interpretability of driving decisions. These findings underscore the importance of structured reasoning in end-to-end driving and establish X-Driver as a strong baseline for future research in closed-loop autonomous driving.
Automatic Intent-Slot Induction for Dialogue Systems
Mar 16, 2021

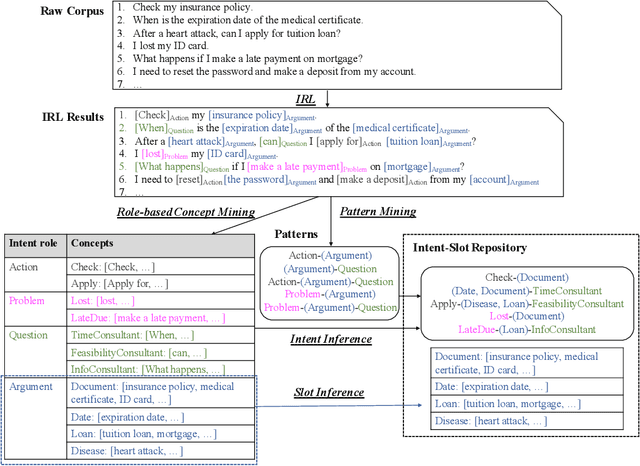

Automatically and accurately identifying user intents and filling the associated slots from their spoken language are critical to the success of dialogue systems. Traditional methods require manually defining the DOMAIN-INTENT-SLOT schema and asking many domain experts to annotate the corresponding utterances, upon which neural models are trained. This procedure brings the challenges of information sharing hindering, out-of-schema, or data sparsity in open-domain dialogue systems. To tackle these challenges, we explore a new task of {\em automatic intent-slot induction} and propose a novel domain-independent tool. That is, we design a coarse-to-fine three-step procedure including Role-labeling, Concept-mining, And Pattern-mining (RCAP): (1) role-labeling: extracting keyphrases from users' utterances and classifying them into a quadruple of coarsely-defined intent-roles via sequence labeling; (2) concept-mining: clustering the extracted intent-role mentions and naming them into abstract fine-grained concepts; (3) pattern-mining: applying the Apriori algorithm to mine intent-role patterns and automatically inferring the intent-slot using these coarse-grained intent-role labels and fine-grained concepts. Empirical evaluations on both real-world in-domain and out-of-domain datasets show that: (1) our RCAP can generate satisfactory SLU schema and outperforms the state-of-the-art supervised learning method; (2) our RCAP can be directly applied to out-of-domain datasets and gain at least 76\% improvement of F1-score on intent detection and 41\% improvement of F1-score on slot filling; (3) our RCAP exhibits its power in generic intent-slot extractions with less manual effort, which opens pathways for schema induction on new domains and unseen intent-slot discovery for generalizable dialogue systems.
An End-to-End Dialogue State Tracking System with Machine Reading Comprehension and Wide & Deep Classification
Feb 02, 2020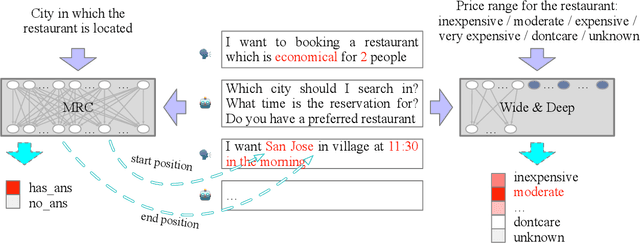

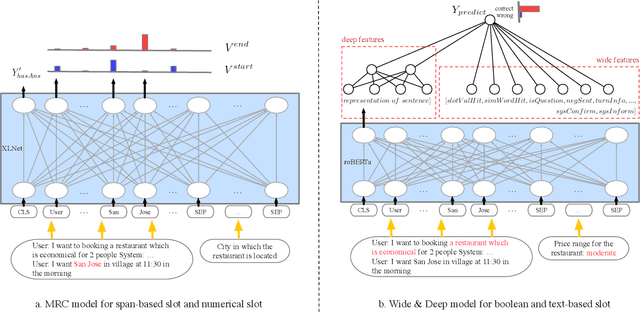
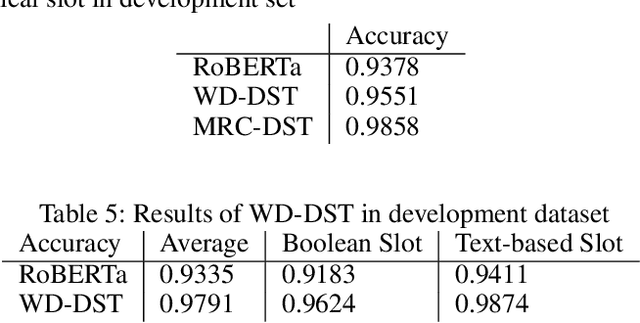
This paper describes our approach in DSTC 8 Track 4: Schema-Guided Dialogue State Tracking. The goal of this task is to predict the intents and slots in each user turn to complete the dialogue state tracking (DST) based on the information provided by the task's schema. Different from traditional stage-wise DST, we propose an end-to-end DST system to avoid error accumulation between the dialogue turns. The DST system consists of a machine reading comprehension (MRC) model for non-categorical slots and a Wide & Deep model for categorical slots. As far as we know, this is the first time that MRC and Wide & Deep model are applied to DST problem in a fully end-to-end way. Experimental results show that our framework achieves an excellent performance on the test dataset including 50% zero-shot services with a joint goal accuracy of 0.8652 and a slot tagging F1-Score of 0.9835.
Multi Scale Supervised 3D U-Net for Kidney and Tumor Segmentation
Aug 13, 2019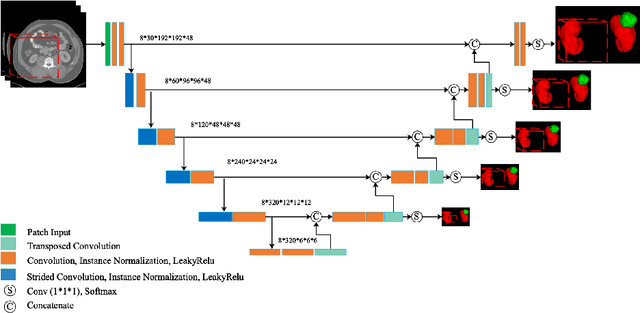



U-Net has achieved huge success in various medical image segmentation challenges. Kinds of new architectures with bells and whistles might succeed in certain dataset when employed with optimal hyper-parameter, but their generalization always can't be guaranteed. Here, we focused on the basic U-Net architecture and proposed a multi scale supervised 3D U-Net for the segmentation task in KiTS19 challenge. To enhance the performance, our work can be summarized as three folds: first, we used multi scale supervision in the decoder pathway, which could encourage the network to predict right results from the deep layers; second, with the aim to alleviate the bad effect from the sample imbalance of kidney and tumor, we adopted exponential logarithmic loss; third, a connected-component based post processing method was designed to remove the obviously wrong voxels. In the published KiTS19 training dataset (totally 210 patients), we divided 42 patients to be test dataset and finally obtained DICE scores of 0.969 and 0.805 for the kidney and tumor respectively. In the challenge, we finally achieved the 7th place among 106 teams with the Composite Dice of 0.8961, namely 0.9741 for kidney and 0.8181 for tumor.