 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Tracking Improves World Action Models
May 22, 2026Robot policy learning benefits from world-action models that capture environment dynamics, but pixel-level prediction entangles dynamics with nuisance factors such as lighting and texture, making learned representations vulnerable to task-irrelevant visual variation. We propose JOPAT, a JOint Pixel-And-Track World-Action Model that predicts latent visual observations, 2D point tracks with visibility, and actions in a single denoising diffusion transformer. The key insight is that tracks provide an explicit representation of motion that captures long-horizon dynamics and remains robust under occlusion or partial out-of-frame motion, offering greater utility than modeling pixel appearance alone. On LIBERO and real-world LeRobot tasks, JOPAT improves over pixel-based baselines, with the largest gains on long-horizon tasks involving occlusion, object interaction, and off-screen motion.
Rethinking Temporal Consistency in Video Object-Centric Learning: From Prediction to Correspondence
May 05, 2026The de facto approach in video object-centric learning maintains temporal consistency through learned dynamics modules that predict future object representations, called slots. We demonstrate that these predictors function as expensive approximations of discrete correspondence problems. Modern self-supervised vision backbones already encode instance-discriminative features that distinguish objects reliably. Exploiting these features eliminates the need for learned temporal prediction. We introduce Grounded Correspondence, a framework that replaces learned transition functions with deterministic bipartite matching. Slots initialize from salient regions in frozen backbone features. Frame-to-frame identity is maintained through Hungarian matching on slot representations. The approach requires zero learnable parameters for temporal modeling yet achieves competitive performance on MOVi-D, MOVi-E, and YouTube-VIS. Project page: https://magenta-sherbet-85b101.netlify.app/
Bridging the Embodiment Gap: Disentangled Cross-Embodiment Video Editing
May 05, 2026Learning robotic manipulation from human videos is a promising solution to the data bottleneck in robotics, but the distribution shift between humans and robots remains a critical challenge. Existing approaches often produce entangled representations, where task-relevant information is coupled with human-specific kinematics, limiting their adaptability. We propose a generative framework for cross-embodiment video editing that directly addresses this by learning explicitly disentangled task and embodiment representations. Our method factorizes a demonstration video into two orthogonal latent spaces by enforcing a dual contrastive objective: it minimizes mutual information between the spaces to ensure independence while maximizing intra-space consistency to create stable representations. A parameter-efficient adapter injects these latent codes into a frozen video diffusion model, enabling the synthesis of a coherent robot execution video from a single human demonstration, without requiring paired cross-embodiment data. Experiments show our approach generates temporally consistent and morphologically accurate robot demonstrations, offering a scalable solution to leverage internet-scale human video for robot learning.
PAWS: Perception of Articulation in the Wild at Scale from Egocentric Videos
Mar 26, 2026Articulation perception aims to recover the motion and structure of articulated objects (e.g., drawers and cupboards), and is fundamental to 3D scene understanding in robotics, simulation, and animation. Existing learning-based methods rely heavily on supervised training with high-quality 3D data and manual annotations, limiting scalability and diversity. To address this limitation, we propose PAWS, a method that directly extracts object articulations from hand-object interactions in large-scale in-the-wild egocentric videos. We evaluate our method on the public data sets, including HD-EPIC and Arti4D data sets, achieving significant improvements over baselines. We further demonstrate that the extracted articulations benefit downstream tasks, including fine-tuning 3D articulation prediction models and enabling robot manipulation. See the project website at https://aaltoml.github.io/PAWS/.
Sparsely Supervised Diffusion
Feb 02, 2026Diffusion models have shown remarkable success across a wide range of generative tasks. However, they often suffer from spatially inconsistent generation, arguably due to the inherent locality of their denoising mechanisms. This can yield samples that are locally plausible but globally inconsistent. To mitigate this issue, we propose sparsely supervised learning for diffusion models, a simple yet effective masking strategy that can be implemented with only a few lines of code. Interestingly, the experiments show that it is safe to mask up to 98\% of pixels during diffusion model training. Our method delivers competitive FID scores across experiments and, most importantly, avoids training instability on small datasets. Moreover, the masking strategy reduces memorization and promotes the use of essential contextual information during generation.
Bi-Level Motion Imitation for Humanoid Robots
Oct 02, 2024



Imitation learning from human motion capture (MoCap) data provides a promising way to train humanoid robots. However, due to differences in morphology, such as varying degrees of joint freedom and force limits, exact replication of human behaviors may not be feasible for humanoid robots. Consequently, incorporating physically infeasible MoCap data in training datasets can adversely affect the performance of the robot policy. To address this issue, we propose a bi-level optimization-based imitation learning framework that alternates between optimizing both the robot policy and the target MoCap data. Specifically, we first develop a generative latent dynamics model using a novel self-consistent auto-encoder, which learns sparse and structured motion representations while capturing desired motion patterns in the dataset. The dynamics model is then utilized to generate reference motions while the latent representation regularizes the bi-level motion imitation process. Simulations conducted with a realistic model of a humanoid robot demonstrate that our method enhances the robot policy by modifying reference motions to be physically consistent.
AgentMixer: Multi-Agent Correlated Policy Factorization
Jan 16, 2024



Centralized training with decentralized execution (CTDE) is widely employed to stabilize partially observable multi-agent reinforcement learning (MARL) by utilizing a centralized value function during training. However, existing methods typically assume that agents make decisions based on their local observations independently, which may not lead to a correlated joint policy with sufficient coordination. Inspired by the concept of correlated equilibrium, we propose to introduce a \textit{strategy modification} to provide a mechanism for agents to correlate their policies. Specifically, we present a novel framework, AgentMixer, which constructs the joint fully observable policy as a non-linear combination of individual partially observable policies. To enable decentralized execution, one can derive individual policies by imitating the joint policy. Unfortunately, such imitation learning can lead to \textit{asymmetric learning failure} caused by the mismatch between joint policy and individual policy information. To mitigate this issue, we jointly train the joint policy and individual policies and introduce \textit{Individual-Global-Consistency} to guarantee mode consistency between the centralized and decentralized policies. We then theoretically prove that AgentMixer converges to an $\epsilon$-approximate Correlated Equilibrium. The strong experimental performance on three MARL benchmarks demonstrates the effectiveness of our method.
Optimistic Multi-Agent Policy Gradient for Cooperative Tasks
Nov 03, 2023

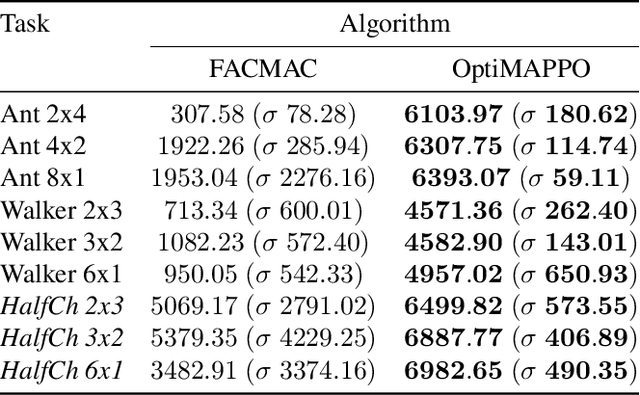
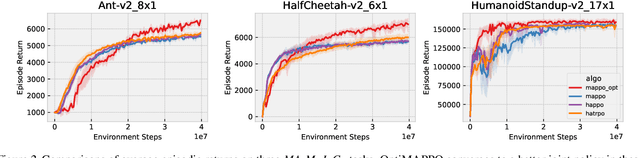
\textit{Relative overgeneralization} (RO) occurs in cooperative multi-agent learning tasks when agents converge towards a suboptimal joint policy due to overfitting to suboptimal behavior of other agents. In early work, optimism has been shown to mitigate the \textit{RO} problem when using tabular Q-learning. However, with function approximation optimism can amplify overestimation and thus fail on complex tasks. On the other hand, recent deep multi-agent policy gradient (MAPG) methods have succeeded in many complex tasks but may fail with severe \textit{RO}. We propose a general, yet simple, framework to enable optimistic updates in MAPG methods and alleviate the RO problem. Specifically, we employ a \textit{Leaky ReLU} function where a single hyperparameter selects the degree of optimism to reshape the advantages when updating the policy. Intuitively, our method remains optimistic toward individual actions with lower returns which are potentially caused by other agents' sub-optimal behavior during learning. The optimism prevents the individual agents from quickly converging to a local optimum. We also provide a formal analysis from an operator view to understand the proposed advantage transformation. In extensive evaluations on diverse sets of tasks, including illustrative matrix games, complex \textit{Multi-agent MuJoCo} and \textit{Overcooked} benchmarks, the proposed method\footnote{Code can be found at \url{https://github.com/wenshuaizhao/optimappo}.} outperforms strong baselines on 13 out of 19 tested tasks and matches the performance on the rest.
Less Is More: Robust Robot Learning via Partially Observable Multi-Agent Reinforcement Learning
Sep 26, 2023
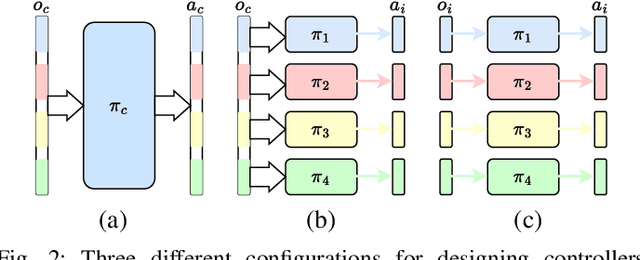
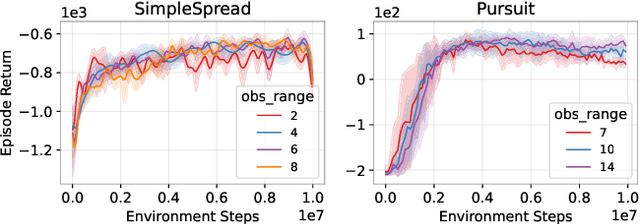
In many multi-agent and high-dimensional robotic tasks, the controller can be designed in either a centralized or decentralized way. Correspondingly, it is possible to use either single-agent reinforcement learning (SARL) or multi-agent reinforcement learning (MARL) methods to learn such controllers. However, the relationship between these two paradigms remains under-studied in the literature. This work explores research questions in terms of robustness and performance of SARL and MARL approaches to the same task, in order to gain insight into the most suitable methods. We start by analytically showing the equivalence between these two paradigms under the full-state observation assumption. Then, we identify a broad subclass of \textit{Dec-POMDP} tasks where the agents are weakly or partially interacting. In these tasks, we show that partial observations of each agent are sufficient for near-optimal decision-making. Furthermore, we propose to exploit such partially observable MARL to improve the robustness of robots when joint or agent failures occur. Our experiments on both simulated multi-agent tasks and a real robot task with a mobile manipulator validate the presented insights and the effectiveness of the proposed robust robot learning method via partially observable MARL.
Simplified Temporal Consistency Reinforcement Learning
Jun 15, 2023Reinforcement learning is able to solve complex sequential decision-making tasks but is currently limited by sample efficiency and required computation. To improve sample efficiency, recent work focuses on model-based RL which interleaves model learning with planning. Recent methods further utilize policy learning, value estimation, and, self-supervised learning as auxiliary objectives. In this paper we show that, surprisingly, a simple representation learning approach relying only on a latent dynamics model trained by latent temporal consistency is sufficient for high-performance RL. This applies when using pure planning with a dynamics model conditioned on the representation, but, also when utilizing the representation as policy and value function features in model-free RL. In experiments, our approach learns an accurate dynamics model to solve challenging high-dimensional locomotion tasks with online planners while being 4.1 times faster to train compared to ensemble-based methods. With model-free RL without planning, especially on high-dimensional tasks, such as the DeepMind Control Suite Humanoid and Dog tasks, our approach outperforms model-free methods by a large margin and matches model-based methods' sample efficiency while training 2.4 times faster.