 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simulation Platform for Flapping-Wing Vehicles
Jun 01, 2026Flapping-wing aerial vehicles (FWAVs) demonstrate remarkable agility but face substantial autonomy challenges due to their high sensitivity to aerodynamic disturbances and limited sensor payload capacity. Current simulation platforms typically rely on oversimplified laminar flow assumptions and idealized sensor models, failing to capture the complex turbulence patterns and perceptual limitations encountered in real-world operation. This simulation-to-reality discrepancy significantly impedes the development of robust autonomy systems for FWAVs. We introduce FWAV-Sim, a high-fidelity Unity-based simulation framework that integrates: (1) a composite aerodynamic model combining quasi-steady blade-element theory with bluff-body drag effects, (2) spatiotemporally correlated turbulence generation through fractal noise synthesis, and (3) realistic sensor simulation including noisy IMU measurements, LiDAR point clouds, and RGB camera feeds. Our platform enables scalable generation of synchronized datasets containing ground-truth vehicle states, aerodynamic forces, turbulent wind fields, and multi-modal sensor streams. Experimental validation demonstrates that autonomy pipelines (including both controllers and perception systems) developed in FWAV-Sim exhibit significantly improved simulation capability, thereby advancing the outstanding performance in simulation-based development for flapping-wing aerial systems.
SAFEVPR: Patch-Based Conformal Verification for Safe Cross-Condition Sequence Visual Place Recognition
May 27, 2026Sequence-based visual place recognition (VPR) for SLAM and robot relocalization must decide whether the retrieved top-1 candidate is safe to accept. Conformal prediction is a natural framework for this accept/reject decision, but its finite-sample guarantees rely on exchangeability between calibration and deployment (test) data, which is violated under cross-condition deployment. We introduce SAFEVPR, a non-trainable verification-and-calibration pipeline for safe cross-condition sequence VPR. SAFEVPR replaces the standard backbone cosine similarity with a mutual-nearest-neighbour (MNN) patch-matching score computed from frozen DINOv2 ViT features, and replaces flat Learn-Then-Test calibration with Mondrian conformal LTT, fitting separate Bonferroni-corrected thresholds across score bins. Under exchangeability, these thresholds would provide finite-sample false-discovery-rate (FDR) control; under condition shift, we evaluate empirical validity per deployment. Across 23 cross-condition setups from Oxford RobotCar, NCLT, and St Lucia datasets, using three frozen VPR backbones, SAFEVPR is empirically valid on 23/23 setups at target FDR alpha = 0.10, achieving mean accepted FDR 0.014 and mean true-positive rate (TPR) 0.75. The results show that raw discrimination alone is not sufficient for conformal validity: AnyLoc-VLAD and Super-Point+LightGlue reach comparable area under the receiver operating characteristic curve (AUROC) but fail more setups under the same calibration. On textureless repetitive scenery, SAFEVPR safely abstains rather than accepting unreliable matches. Code is available at https://github.com/Hasar12139/SafeVPR.
Riverine Land Cover Mapping through Semantic Segmentation of Multispectral Point Clouds
Mar 23, 2026Accurate land cover mapping in riverine environments is essential for effective river management, ecological understanding, and geomorphic change monitoring. This study explores the use of Point Transformer v2 (PTv2), an advanced deep neural network architecture designed for point cloud data, for land cover mapping through semantic segmentation of multispectral LiDAR data in real-world riverine environments. We utilize the geometric and spectral information from the 3-channel LiDAR point cloud to map land cover classes, including sand, gravel, low vegetation, high vegetation, forest floor, and water. The PTv2 model was trained and evaluated on point cloud data from the Oulanka river in northern Finland using both geometry and spectral features. To improve the model's generalization in new riverine environments, we additionally investigate multi-dataset training that adds sparsely annotated data from an additional river dataset. Results demonstrated that using the full-feature configuration resulted in performance with a mean Intersection over Union (mIoU) of 0.950, significantly outperforming the geometry baseline. Other ablation studies revealed that intensity and reflectance features were the key for accurate land cover mapping. The multi-dataset training experiment showed improved generalization performance, suggesting potential for developing more robust models despite limited high-quality annotated data. Our work demonstrates the potential of applying transformer-based architectures to multispectral point clouds in riverine environments. The approach offers new capabilities for monitoring sediment transport and other river management applications.
Decentralized Intent-Based Multi-Robot Task Planner with LLM Oracles on Hyperledger Fabric
Feb 09, 2026Large language models (LLMs) have opened new opportunities for transforming natural language user intents into executable actions. This capability enables embodied AI agents to perform complex tasks, without involvement of an expert, making human-robot interaction (HRI) more convenient. However these developments raise significant security and privacy challenges such as self-preferencing, where a single LLM service provider dominates the market and uses this power to promote their own preferences. LLM oracles have been recently proposed as a mechanism to decentralize LLMs by executing multiple LLMs from different vendors and aggregating their outputs to obtain a more reliable and trustworthy final result. However, the accuracy of these approaches highly depends on the aggregation method. The current aggregation methods mostly use semantic similarity between various LLM outputs, not suitable for robotic task planning, where the temporal order of tasks is important. To fill the gap, we propose an LLM oracle with a new aggregation method for robotic task planning. In addition, we propose a decentralized multi-robot infrastructure based on Hyperledger Fabric that can host the proposed oracle. The proposed infrastructure enables users to express their natural language intent to the system, which then can be decomposed into subtasks. These subtasks require coordinating different robots from different vendors, while enforcing fine-grained access control management on the data. To evaluate our methodology, we created the SkillChain-RTD benchmark made it publicly available. Our experimental results demonstrate the feasibility of the proposed architecture, and the proposed aggregation method outperforms other aggregation methods currently in use.
INDOOR-LiDAR: Bridging Simulation and Reality for Robot-Centric 360 degree Indoor LiDAR Perception -- A Robot-Centric Hybrid Dataset
Dec 13, 2025We present INDOOR-LIDAR, a comprehensive hybrid dataset of indoor 3D LiDAR point clouds designed to advance research in robot perception. Existing indoor LiDAR datasets often suffer from limited scale, inconsistent annotation formats, and human-induced variability during data collection. INDOOR-LIDAR addresses these limitations by integrating simulated environments with real-world scans acquired using autonomous ground robots, providing consistent coverage and realistic sensor behavior under controlled variations. Each sample consists of dense point cloud data enriched with intensity measurements and KITTI-style annotations. The annotation schema encompasses common indoor object categories within various scenes. The simulated subset enables flexible configuration of layouts, point densities, and occlusions, while the real-world subset captures authentic sensor noise, clutter, and domain-specific artifacts characteristic of real indoor settings. INDOOR-LIDAR supports a wide range of applications including 3D object detection, bird's-eye-view (BEV) perception, SLAM, semantic scene understanding, and domain adaptation between simulated and real indoor domains. By bridging the gap between synthetic and real-world data, INDOOR-LIDAR establishes a scalable, realistic, and reproducible benchmark for advancing robotic perception in complex indoor environments.
Seamless Outdoor-Indoor Pedestrian Positioning System with GNSS/UWB/IMU Fusion: A Comparison of EKF, FGO, and PF
Dec 11, 2025Accurate and continuous pedestrian positioning across outdoor-indoor environments remains challenging because GNSS, UWB, and inertial PDR are complementary yet individually fragile under signal blockage, multipath, and drift. This paper presents a unified GNSS/UWB/IMU fusion framework for seamless pedestrian localization and provides a controlled comparison of three probabilistic back-ends: an error-state extended Kalman filter, sliding-window factor graph optimization, and a particle filter. The system uses chest-mounted IMU-based PDR as the motion backbone and integrates absolute updates from GNSS outdoors and UWB indoors. To enhance transition robustness and mitigate urban GNSS degradation, we introduce a lightweight map-based feasibility constraint derived from OpenStreetMap building footprints, treating most building interiors as non-navigable while allowing motion inside a designated UWB-instrumented building. The framework is implemented in ROS 2 and runs in real time on a wearable platform, with visualization in Foxglove. We evaluate three scenarios: indoor (UWB+PDR), outdoor (GNSS+PDR), and seamless outdoor-indoor (GNSS+UWB+PDR). Results show that the ESKF provides the most consistent overall performance in our implementation.
A Sensor-Aware Phenomenological Framework for Lidar Degradation Simulation and SLAM Robustness Evaluation
Dec 09, 2025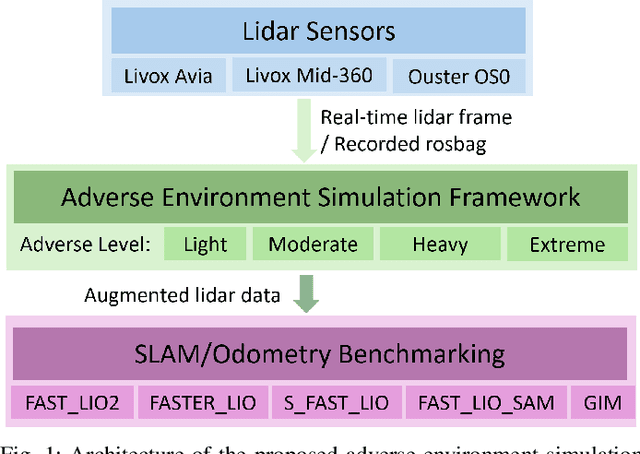
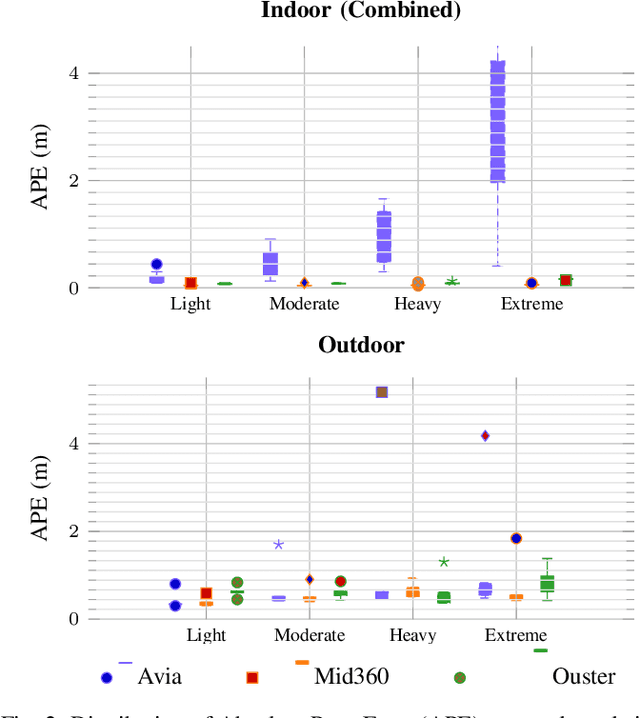
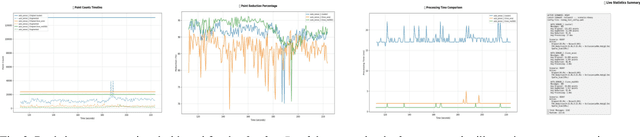
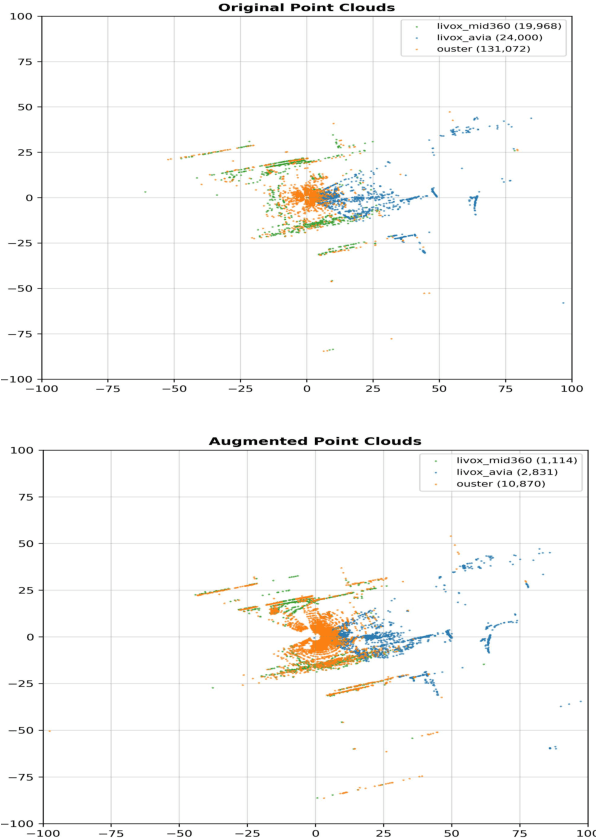
Lidar-based SLAM systems are highly sensitive to adverse conditions such as occlusion, noise, and field-of-view (FoV) degradation, yet existing robustness evaluation methods either lack physical grounding or do not capture sensor-specific behavior. This paper presents a sensor-aware, phenomenological framework for simulating interpretable lidar degradations directly on real point clouds, enabling controlled and reproducible SLAM stress testing. Unlike image-derived corruption benchmarks (e.g., SemanticKITTI-C) or simulation-only approaches (e.g., lidarsim), the proposed system preserves per-point geometry, intensity, and temporal structure while applying structured dropout, FoV reduction, Gaussian noise, occlusion masking, sparsification, and motion distortion. The framework features autonomous topic and sensor detection, modular configuration with four severity tiers (light--extreme), and real-time performance (less than 20 ms per frame) compatible with ROS workflows. Experimental validation across three lidar architectures and five state-of-the-art SLAM systems reveals distinct robustness patterns shaped by sensor design and environmental context. The open-source implementation provides a practical foundation for benchmarking lidar-based SLAM under physically meaningful degradation scenarios.
Follow-Me in Micro-Mobility with End-to-End Imitation Learning
Nov 07, 2025Autonomous micro-mobility platforms face challenges from the perspective of the typical deployment environment: large indoor spaces or urban areas that are potentially crowded and highly dynamic. While social navigation algorithms have progressed significantly, optimizing user comfort and overall user experience over other typical metrics in robotics (e.g., time or distance traveled) is understudied. Specifically, these metrics are critical in commercial applications. In this paper, we show how imitation learning delivers smoother and overall better controllers, versus previously used manually-tuned controllers. We demonstrate how DAAV's autonomous wheelchair achieves state-of-the-art comfort in follow-me mode, in which it follows a human operator assisting persons with reduced mobility (PRM). This paper analyzes different neural network architectures for end-to-end control and demonstrates their usability in real-world production-level deployments.
Degradation-Aware Cooperative Multi-Modal GNSS-Denied Localization Leveraging LiDAR-Based Robot Detections
Oct 23, 2025Accurate long-term localization using onboard sensors is crucial for robots operating in Global Navigation Satellite System (GNSS)-denied environments. While complementary sensors mitigate individual degradations, carrying all the available sensor types on a single robot significantly increases the size, weight, and power demands. Distributing sensors across multiple robots enhances the deployability but introduces challenges in fusing asynchronous, multi-modal data from independently moving platforms. We propose a novel adaptive multi-modal multi-robot cooperative localization approach using a factor-graph formulation to fuse asynchronous Visual-Inertial Odometry (VIO), LiDAR-Inertial Odometry (LIO), and 3D inter-robot detections from distinct robots in a loosely-coupled fashion. The approach adapts to changing conditions, leveraging reliable data to assist robots affected by sensory degradations. A novel interpolation-based factor enables fusion of the unsynchronized measurements. LIO degradations are evaluated based on the approximate scan-matching Hessian. A novel approach of weighting odometry data proportionally to the Wasserstein distance between the consecutive VIO outputs is proposed. A theoretical analysis is provided, investigating the cooperative localization problem under various conditions, mainly in the presence of sensory degradations. The proposed method has been extensively evaluated on real-world data gathered with heterogeneous teams of an Unmanned Ground Vehicle (UGV) and Unmanned Aerial Vehicles (UAVs), showing that the approach provides significant improvements in localization accuracy in the presence of various sensory degradations.
IndoorBEV: Joint Detection and Footprint Completion of Objects via Mask-based Prediction in Indoor Scenarios for Bird's-Eye View Perception
Jul 23, 2025Detecting diverse objects within complex indoor 3D point clouds presents significant challenges for robotic perception, particularly with varied object shapes, clutter, and the co-existence of static and dynamic elements where traditional bounding box methods falter. To address these limitations, we propose IndoorBEV, a novel mask-based Bird's-Eye View (BEV) method for indoor mobile robots. In a BEV method, a 3D scene is projected into a 2D BEV grid which handles naturally occlusions and provides a consistent top-down view aiding to distinguish static obstacles from dynamic agents. The obtained 2D BEV results is directly usable to downstream robotic tasks like navigation, motion prediction, and planning. Our architecture utilizes an axis compact encoder and a window-based backbone to extract rich spatial features from this BEV map. A query-based decoder head then employs learned object queries to concurrently predict object classes and instance masks in the BEV space. This mask-centric formulation effectively captures the footprint of both static and dynamic objects regardless of their shape, offering a robust alternative to bounding box regression. We demonstrate the effectiveness of IndoorBEV on a custom indoor dataset featuring diverse object classes including static objects and dynamic elements like robots and miscellaneous items, showcasing its potential for robust indoor scene understanding.