 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Alignment in Multimodal LLMs: A Comprehensive Study
Jul 02, 2024



Preference alignment has become a crucial component in enhancing the performance of Large Language Models (LLMs), yet its impact in Multimodal Large Language Models (MLLMs) remains comparatively underexplored. Similar to language models, MLLMs for image understanding tasks encounter challenges like hallucination. In MLLMs, hallucination can occur not only by stating incorrect facts but also by producing responses that are inconsistent with the image content. A primary objective of alignment for MLLMs is to encourage these models to align responses more closely with image information. Recently, multiple works have introduced preference datasets for MLLMs and examined different alignment methods, including Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO). However, due to variations in datasets, base model types, and alignment methods, it remains unclear which specific elements contribute most significantly to the reported improvements in these works. In this paper, we independently analyze each aspect of preference alignment in MLLMs. We start by categorizing the alignment algorithms into two groups, offline (such as DPO), and online (such as online-DPO), and show that combining offline and online methods can improve the performance of the model in certain scenarios. We review a variety of published multimodal preference datasets and discuss how the details of their construction impact model performance. Based on these insights, we introduce a novel way of creating multimodal preference data called Bias-Driven Hallucination Sampling (BDHS) that needs neither additional annotation nor external models, and show that it can achieve competitive performance to previously published alignment work for multimodal models across a range of benchmarks.
Simplified Temporal Consistency Reinforcement Learning
Jun 15, 2023Reinforcement learning is able to solve complex sequential decision-making tasks but is currently limited by sample efficiency and required computation. To improve sample efficiency, recent work focuses on model-based RL which interleaves model learning with planning. Recent methods further utilize policy learning, value estimation, and, self-supervised learning as auxiliary objectives. In this paper we show that, surprisingly, a simple representation learning approach relying only on a latent dynamics model trained by latent temporal consistency is sufficient for high-performance RL. This applies when using pure planning with a dynamics model conditioned on the representation, but, also when utilizing the representation as policy and value function features in model-free RL. In experiments, our approach learns an accurate dynamics model to solve challenging high-dimensional locomotion tasks with online planners while being 4.1 times faster to train compared to ensemble-based methods. With model-free RL without planning, especially on high-dimensional tasks, such as the DeepMind Control Suite Humanoid and Dog tasks, our approach outperforms model-free methods by a large margin and matches model-based methods' sample efficiency while training 2.4 times faster.
SACPlanner: Real-World Collision Avoidance with a Soft Actor Critic Local Planner and Polar State Representations
Mar 21, 2023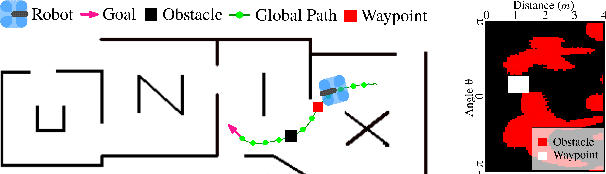



We study the training performance of ROS local planners based on Reinforcement Learning (RL), and the trajectories they produce on real-world robots. We show that recent enhancements to the Soft Actor Critic (SAC) algorithm such as RAD and DrQ achieve almost perfect training after only 10000 episodes. We also observe that on real-world robots the resulting SACPlanner is more reactive to obstacles than traditional ROS local planners such as DWA.
Adaptive Behavior Cloning Regularization for Stable Offline-to-Online Reinforcement Learning
Oct 25, 2022Offline reinforcement learning, by learning from a fixed dataset, makes it possible to learn agent behaviors without interacting with the environment. However, depending on the quality of the offline dataset, such pre-trained agents may have limited performance and would further need to be fine-tuned online by interacting with the environment. During online fine-tuning, the performance of the pre-trained agent may collapse quickly due to the sudden distribution shift from offline to online data. While constraints enforced by offline RL methods such as a behaviour cloning loss prevent this to an extent, these constraints also significantly slow down online fine-tuning by forcing the agent to stay close to the behavior policy. We propose to adaptively weigh the behavior cloning loss during online fine-tuning based on the agent's performance and training stability. Moreover, we use a randomized ensemble of Q functions to further increase the sample efficiency of online fine-tuning by performing a large number of learning updates. Experiments show that the proposed method yields state-of-the-art offline-to-online reinforcement learning performance on the popular D4RL benchmark. Code is available: \url{https://github.com/zhaoyi11/adaptive_bc}.
End-to-End Learning of Keypoint Representations for Continuous Control from Images
Jun 15, 2021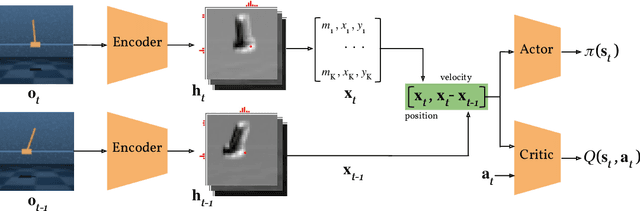



In many control problems that include vision, optimal controls can be inferred from the location of the objects in the scene. This information can be represented using keypoints, which is a list of spatial locations in the input image. Previous works show that keypoint representations learned during unsupervised pre-training using encoder-decoder architectures can provide good features for control tasks. In this paper, we show that it is possible to learn efficient keypoint representations end-to-end, without the need for unsupervised pre-training, decoders, or additional losses. Our proposed architecture consists of a differentiable keypoint extractor that feeds the coordinates of the estimated keypoints directly to a soft actor-critic agent. The proposed algorithm yields performance competitive to the state-of-the art on DeepMind Control Suite tasks.
Learning to Play Imperfect-Information Games by Imitating an Oracle Planner
Dec 22, 2020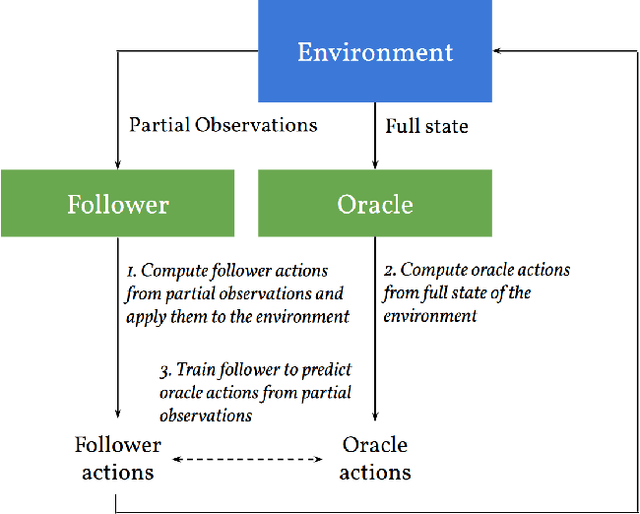
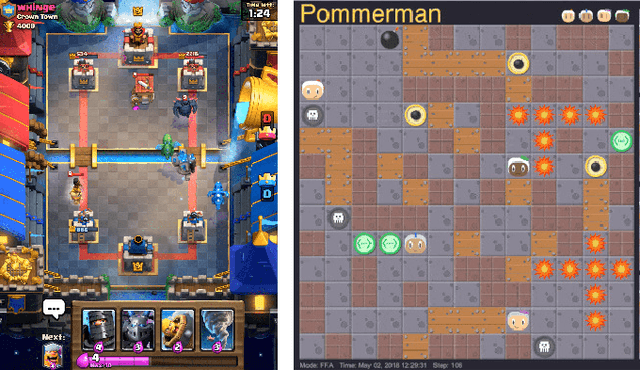
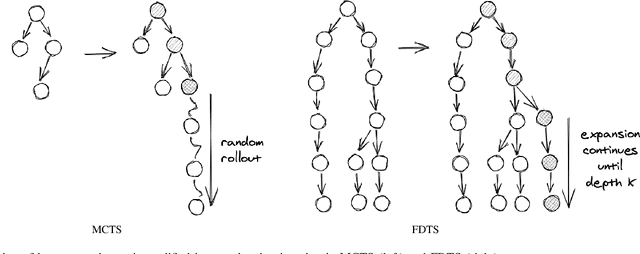
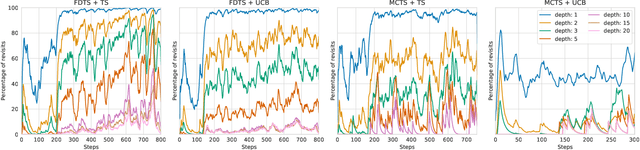
We consider learning to play multiplayer imperfect-information games with simultaneous moves and large state-action spaces. Previous attempts to tackle such challenging games have largely focused on model-free learning methods, often requiring hundreds of years of experience to produce competitive agents. Our approach is based on model-based planning. We tackle the problem of partial observability by first building an (oracle) planner that has access to the full state of the environment and then distilling the knowledge of the oracle to a (follower) agent which is trained to play the imperfect-information game by imitating the oracle's choices. We experimentally show that planning with naive Monte Carlo tree search does not perform very well in large combinatorial action spaces. We therefore propose planning with a fixed-depth tree search and decoupled Thompson sampling for action selection. We show that the planner is able to discover efficient playing strategies in the games of Clash Royale and Pommerman and the follower policy successfully learns to implement them by training on a few hundred battles.
RealAnt: An Open-Source Low-Cost Quadruped for Research in Real-World Reinforcement Learning
Nov 05, 2020



Current robot platforms available for research are either very expensive or unable to handle the abuse of exploratory controls in reinforcement learning. We develop RealAnt, a minimal low-cost physical version of the popular 'Ant' benchmark used in reinforcement learning. RealAnt costs only $410 in materials and can be assembled in less than an hour. We validate the platform with reinforcement learning experiments and provide baseline results on a set of benchmark tasks. We demonstrate that the TD3 algorithm can learn to walk the RealAnt from less than 45 minutes of experience. We also provide simulator versions of the robot (with the same dimensions, state-action spaces, and delayed noisy observations) in the MuJoCo and PyBullet simulators. We open-source hardware designs, supporting software, and baseline results for ease of reproducibility.
Learning to Drive Small Scale Cars from Scratch
Aug 03, 2020

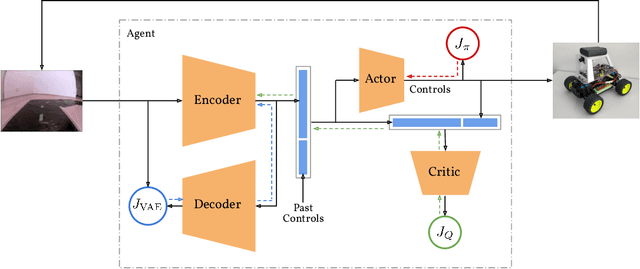

We consider the problem of learning to drive low-cost small scale cars using reinforcement learning. It is challenging to handle the long-tailed distributions of events in the real-world with handcrafted logical rules and reinforcement learning could be a potentially more scalable solution to deal with them. We adopt an existing platform called Donkey car for low-cost repeatable and reproducible research in autonomous driving. We consider the task of learning to drive around a track, given only monocular image observations from an on-board camera. We demonstrate that the soft actor-critic algorithm combined with state representation learning using a variational autoencoder can learn to drive around randomly generated tracks on the Donkey car simulator and a real-world track using the Donkey car platform. Our agent can learn from scratch using sparse and noisy rewards within just 10 minutes of driving experience.
Regularizing Model-Based Planning with Energy-Based Models
Oct 12, 2019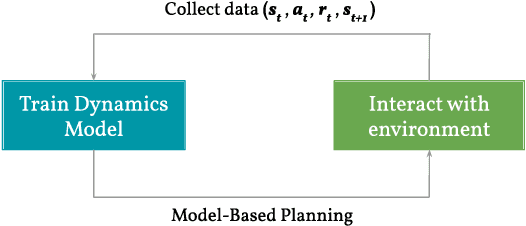
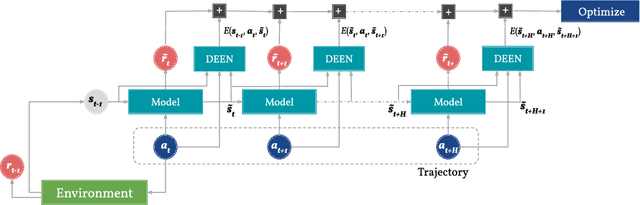
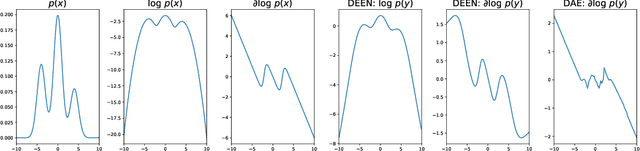
Model-based reinforcement learning could enable sample-efficient learning by quickly acquiring rich knowledge about the world and using it to improve behaviour without additional data. Learned dynamics models can be directly used for planning actions but this has been challenging because of inaccuracies in the learned models. In this paper, we focus on planning with learned dynamics models and propose to regularize it using energy estimates of state transitions in the environment. We visually demonstrate the effectiveness of the proposed method and show that off-policy training of an energy estimator can be effectively used to regularize planning with pre-trained dynamics models. Further, we demonstrate that the proposed method enables sample-efficient learning to achieve competitive performance in challenging continuous control tasks such as Half-cheetah and Ant in just a few minutes of experience.
Regularizing Trajectory Optimization with Denoising Autoencoders
Mar 28, 2019

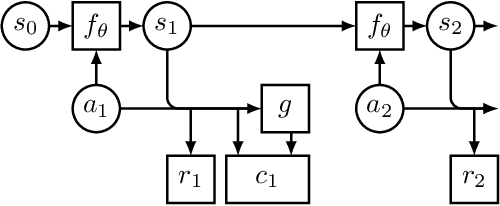

Trajectory optimization with learned dynamics models can often suffer from erroneous predictions of out-of-distribution trajectories. We propose to regularize trajectory optimization by means of a denoising autoencoder that is trained on the same trajectories as the dynamics model. We visually demonstrate the effectiveness of the regularization in gradient-based trajectory optimization for open-loop control of an industrial process. We compare with recent model-based reinforcement learning algorithms on a set of popular motor control tasks to demonstrate that the denoising regularization enables state-of-the-art sample-efficiency. We demonstrate the efficacy of the proposed method in regularizing both gradient-based and gradient-free trajectory optimization.