 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Learning of Keypoint Representations for Continuous Control from Images
Paper and Code
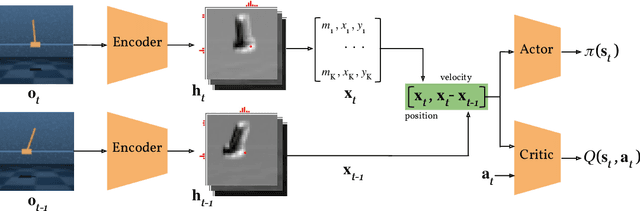



In many control problems that include vision, optimal controls can be inferred from the location of the objects in the scene. This information can be represented using keypoints, which is a list of spatial locations in the input image. Previous works show that keypoint representations learned during unsupervised pre-training using encoder-decoder architectures can provide good features for control tasks. In this paper, we show that it is possible to learn efficient keypoint representations end-to-end, without the need for unsupervised pre-training, decoders, or additional losses. Our proposed architecture consists of a differentiable keypoint extractor that feeds the coordinates of the estimated keypoints directly to a soft actor-critic agent. The proposed algorithm yields performance competitive to the state-of-the art on DeepMind Control Suite tasks.