 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSACPlanner: Real-World Collision Avoidance with a Soft Actor Critic Local Planner and Polar State Representations
Mar 21, 2023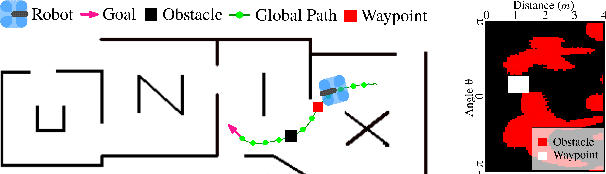



We study the training performance of ROS local planners based on Reinforcement Learning (RL), and the trajectories they produce on real-world robots. We show that recent enhancements to the Soft Actor Critic (SAC) algorithm such as RAD and DrQ achieve almost perfect training after only 10000 episodes. We also observe that on real-world robots the resulting SACPlanner is more reactive to obstacles than traditional ROS local planners such as DWA.
Evolution of Q Values for Deep Q Learning in Stable Baselines
Apr 24, 2020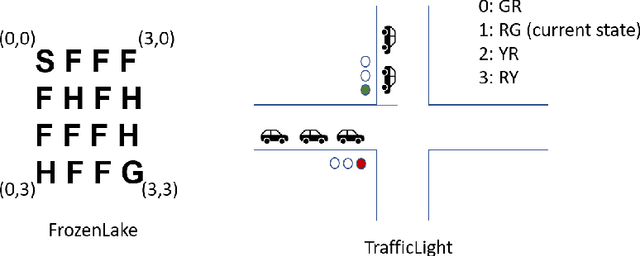



We investigate the evolution of the Q values for the implementation of Deep Q Learning (DQL) in the Stable Baselines library. Stable Baselines incorporates the latest Reinforcement Learning techniques and achieves superhuman performance in many game environments. However, for some simple non-game environments, the DQL in Stable Baselines can struggle to find the correct actions. In this paper we aim to understand the types of environment where this suboptimal behavior can happen, and also investigate the corresponding evolution of the Q values for individual states. We compare a smart TrafficLight environment (where performance is poor) with the AI Gym FrozenLake environment (where performance is perfect). We observe that DQL struggles with TrafficLight because actions are reversible and hence the Q values in a given state are closer than in FrozenLake. We then investigate the evolution of the Q values using a recent decomposition technique of Achiam et al.. We observe that for TrafficLight, the function approximation error and the complex relationships between the states lead to a situation where some Q values meander far from optimal.