 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOUT: Semantic scene COverage via Uncertainty-guided Traversal
Jun 04, 2026Robots that operate over extended periods should not merely visit space; they should progressively understand it. Yet most 3D scene graph pipelines treat perception as a post-processing stage over a fixed dataset, decoupling scene representation from the decisions that determine what is observed in the first place. We present SCOUT, an online semantic exploration framework that closes this loop by coupling active traversal with probabilistic scene graph construction. Given a prior 2D occupancy map and posed RGB-D observations, SCOUT incrementally builds an uncertainty-aware 3D scene graph whose nodes maintain fused geometry and posterior beliefs over open-vocabulary object labels, while edges encode structural relations such as on, inside, belong, and next to. These beliefs are fed back to an uncertainty-guided traversal planner, which selects viewpoints by balancing expected semantic certainty gain, geometric coverage gain, and travel cost. In this way, the robot revisits ambiguous objects when additional evidence matters and expands into unseen free space when the scene remains incomplete. The resulting system treats semantic scene completeness as an operational objective rather than a passive by-product of semantic mapping, moving toward autonomous agents that can patrol, update, and reason about evolving indoor environments with minimal human intervention.
Spatiotemporal Semantic V2X Framework for Cooperative Collision Prediction
Jan 23, 2026Intelligent Transportation Systems (ITS) demand real-time collision prediction to ensure road safety and reduce accident severity. Conventional approaches rely on transmitting raw video or high-dimensional sensory data from roadside units (RSUs) to vehicles, which is impractical under vehicular communication bandwidth and latency constraints. In this work, we propose a semantic V2X framework in which RSU-mounted cameras generate spatiotemporal semantic embeddings of future frames using the Video Joint Embedding Predictive Architecture (V-JEPA). To evaluate the system, we construct a digital twin of an urban traffic environment enabling the generation of d verse traffic scenarios with both safe and collision events. These embeddings of the future frame, extracted from V-JEPA, capture task-relevant traffic dynamics and are transmitted via V2X links to vehicles, where a lightweight attentive probe and classifier decode them to predict imminent collisions. By transmitting only semantic embeddings instead of raw frames, the proposed system significantly reduces communication overhead while maintaining predictive accuracy. Experimental results demonstrate that the framework with an appropriate processing method achieves a 10% F1-score improvement for collision prediction while reducing transmission requirements by four orders of magnitude compared to raw video. This validates the potential of semantic V2X communication to enable cooperative, real-time collision prediction in ITS.
Learning-Based Multiuser Scheduling in MIMO-OFDM Systems with Hybrid Beamforming
Jun 09, 2025We investigate the multiuser scheduling problem in multiple-input multiple-output (MIMO) systems using orthogonal frequency division multiplexing (OFDM) and hybrid beamforming in which a base station (BS) communicates with multiple users over millimeter wave (mmWave) channels in the downlink. Improved scheduling is critical for enhancing spectral efficiency and the long-term performance of the system from the perspective of proportional fairness (PF) metric in hybrid beamforming systems due to its limited multiplexing gain. Our objective is to maximize PF by properly designing the analog and digital precoders within the hybrid beamforming and selecting the users subject to the number of radio frequency (RF) chains. Leveraging the characteristics of mmWave channels, we apply a two-timescale protocol. On a long timescale, we assign an analog beam to each user. Scheduling the users and designing the digital precoder are done accordingly on a short timescale. To conduct scheduling, we propose combinatorial solutions, such as greedy and sorting algorithms, followed by a machine learning (ML) approach. Our numerical results highlight the trade-off between the performance and complexity of the proposed approaches. Consequently, we show that the choice of approach depends on the specific criteria within a given scenario.
Hybrid Classical/RL Local Planner for Ground Robot Navigation
Oct 04, 2024
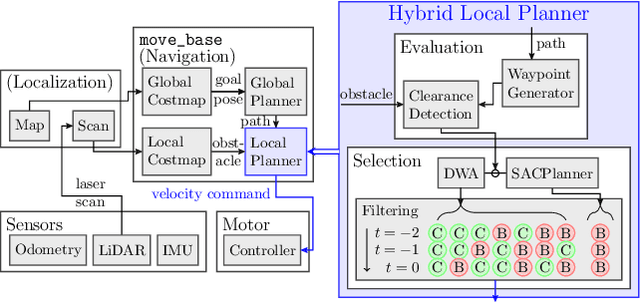

Local planning is an optimization process within a mobile robot navigation stack that searches for the best velocity vector, given the robot and environment state. Depending on how the optimization criteria and constraints are defined, some planners may be better than others in specific situations. We consider two conceptually different planners. The first planner explores the velocity space in real-time and has superior path-tracking and motion smoothness performance. The second planner was trained using reinforcement learning methods to produce the best velocity based on its training $"$experience$"$. It is better at avoiding dynamic obstacles but at the expense of motion smoothness. We propose a simple yet effective meta-reasoning approach that takes advantage of both approaches by switching between planners based on the surroundings. We demonstrate the superiority of our hybrid planner, both qualitatively and quantitatively, over the individual planners on a live robot in different scenarios, achieving an improvement of 26% in the navigation time.
SACPlanner: Real-World Collision Avoidance with a Soft Actor Critic Local Planner and Polar State Representations
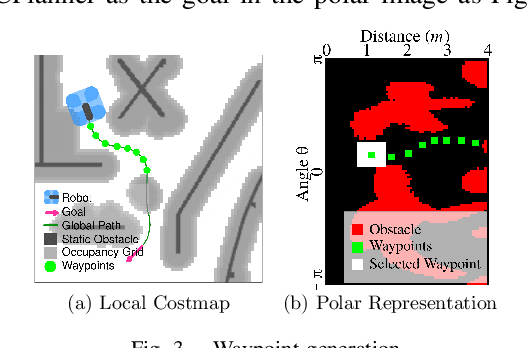
Mar 21, 2023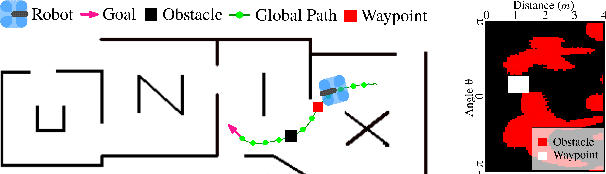



We study the training performance of ROS local planners based on Reinforcement Learning (RL), and the trajectories they produce on real-world robots. We show that recent enhancements to the Soft Actor Critic (SAC) algorithm such as RAD and DrQ achieve almost perfect training after only 10000 episodes. We also observe that on real-world robots the resulting SACPlanner is more reactive to obstacles than traditional ROS local planners such as DWA.
Learning-Based Adaptive User Selection in Millimeter Wave Hybrid Beamforming Systems
Feb 16, 2023We consider a multi-user hybrid beamforming system, where the multiplexing gain is limited by the small number of RF chains employed at the base station (BS). To allow greater freedom for maximizing the multiplexing gain, it is better if the BS selects and serves some of the users at each scheduling instant, rather than serving all the users all the time. We adopt a two-timescale protocol that takes into account the mmWave characteristics, where at the long timescale an analog beam is chosen for each user, and at the short timescale users are selected for transmission based on the chosen analog beams. The goal of the user selection is to maximize the traditional Proportional Fair (PF) metric. However, this maximization is non-trivial due to interference between the analog beams for selected users. We first define a greedy algorithm and a "top-k" algorithm, and then propose a machine learning (ML)-based user selection algorithm to provide an efficient trade-off between the PF performance and the computation time. Throughout simulations, we analyze the performance of the ML-based algorithms under various metrics, and show that it gives an efficient trade-off in performance as compared to counterparts.
Learning Algorithms for Regenerative Stopping Problems with Applications to Shipping Consolidation in Logistics
May 05, 2021

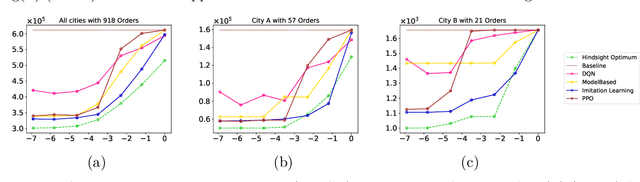
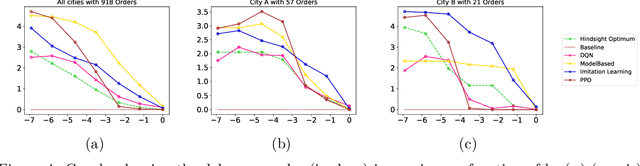
We study regenerative stopping problems in which the system starts anew whenever the controller decides to stop and the long-term average cost is to be minimized. Traditional model-based solutions involve estimating the underlying process from data and computing strategies for the estimated model. In this paper, we compare such solutions to deep reinforcement learning and imitation learning which involve learning a neural network policy from simulations. We evaluate the different approaches on a real-world problem of shipping consolidation in logistics and demonstrate that deep learning can be effectively used to solve such problems.
Evolution of Q Values for Deep Q Learning in Stable Baselines
Apr 24, 2020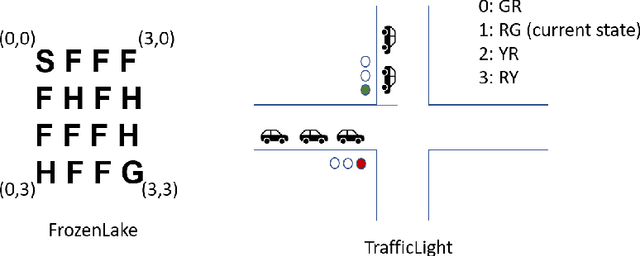



We investigate the evolution of the Q values for the implementation of Deep Q Learning (DQL) in the Stable Baselines library. Stable Baselines incorporates the latest Reinforcement Learning techniques and achieves superhuman performance in many game environments. However, for some simple non-game environments, the DQL in Stable Baselines can struggle to find the correct actions. In this paper we aim to understand the types of environment where this suboptimal behavior can happen, and also investigate the corresponding evolution of the Q values for individual states. We compare a smart TrafficLight environment (where performance is poor) with the AI Gym FrozenLake environment (where performance is perfect). We observe that DQL struggles with TrafficLight because actions are reversible and hence the Q values in a given state are closer than in FrozenLake. We then investigate the evolution of the Q values using a recent decomposition technique of Achiam et al.. We observe that for TrafficLight, the function approximation error and the complex relationships between the states lead to a situation where some Q values meander far from optimal.