 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Classical/RL Local Planner for Ground Robot Navigation
Oct 04, 2024
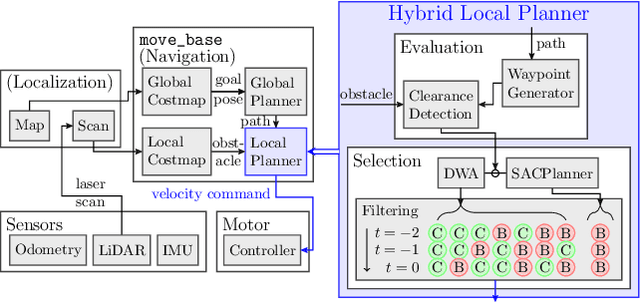
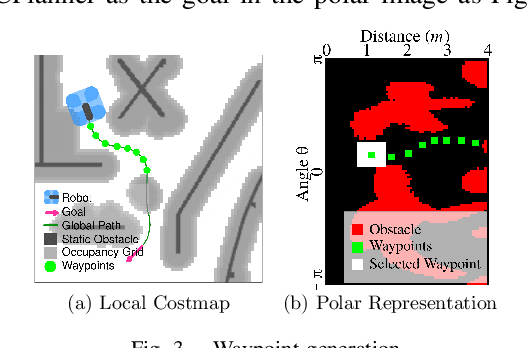

Local planning is an optimization process within a mobile robot navigation stack that searches for the best velocity vector, given the robot and environment state. Depending on how the optimization criteria and constraints are defined, some planners may be better than others in specific situations. We consider two conceptually different planners. The first planner explores the velocity space in real-time and has superior path-tracking and motion smoothness performance. The second planner was trained using reinforcement learning methods to produce the best velocity based on its training $"$experience$"$. It is better at avoiding dynamic obstacles but at the expense of motion smoothness. We propose a simple yet effective meta-reasoning approach that takes advantage of both approaches by switching between planners based on the surroundings. We demonstrate the superiority of our hybrid planner, both qualitatively and quantitatively, over the individual planners on a live robot in different scenarios, achieving an improvement of 26% in the navigation time.
LAVA: Long-horizon Visual Action based Food Acquisition
Mar 19, 2024



Robotic Assisted Feeding (RAF) addresses the fundamental need for individuals with mobility impairments to regain autonomy in feeding themselves. The goal of RAF is to use a robot arm to acquire and transfer food to individuals from the table. Existing RAF methods primarily focus on solid foods, leaving a gap in manipulation strategies for semi-solid and deformable foods. This study introduces Long-horizon Visual Action (LAVA) based food acquisition of liquid, semisolid, and deformable foods. Long-horizon refers to the goal of "clearing the bowl" by sequentially acquiring the food from the bowl. LAVA employs a hierarchical policy for long-horizon food acquisition tasks. The framework uses high-level policy to determine primitives by leveraging ScoopNet. At the mid-level, LAVA finds parameters for primitives using vision. To carry out sequential plans in the real world, LAVA delegates action execution which is driven by Low-level policy that uses parameters received from mid-level policy and behavior cloning ensuring precise trajectory execution. We validate our approach on complex real-world acquisition trials involving granular, liquid, semisolid, and deformable food types along with fruit chunks and soup acquisition. Across 46 bowls, LAVA acquires much more efficiently than baselines with a success rate of 89 +/- 4% and generalizes across realistic plate variations such as different positions, varieties, and amount of food in the bowl. Code, datasets, videos, and supplementary materials can be found on our website.
MAP-NBV: Multi-agent Prediction-guided Next-Best-View Planning for Active 3D Object Reconstruction
Jul 08, 2023



We propose MAP-NBV, a prediction-guided active algorithm for 3D reconstruction with multi-agent systems. Prediction-based approaches have shown great improvement in active perception tasks by learning the cues about structures in the environment from data. But these methods primarily focus on single-agent systems. We design a next-best-view approach that utilizes geometric measures over the predictions and jointly optimizes the information gain and control effort for efficient collaborative 3D reconstruction of the object. Our method achieves 22.75% improvement over the prediction-based single-agent approach and 15.63% improvement over the non-predictive multi-agent approach. We make our code publicly available through our project website: http://raaslab.org/projects/MAPNBV/
Pred-NBV: Prediction-guided Next-Best-View for 3D Object Reconstruction
Apr 22, 2023



Prediction-based active perception has shown the potential to improve the navigation efficiency and safety of the robot by anticipating the uncertainty in the unknown environment. The existing works for 3D shape prediction make an implicit assumption about the partial observations and therefore cannot be used for real-world planning and do not consider the control effort for next-best-view planning. We present Pred-NBV, a realistic object shape reconstruction method consisting of PoinTr-C, an enhanced 3D prediction model trained on the ShapeNet dataset, and an information and control effort-based next-best-view method to address these issues. Pred-NBV shows an improvement of 25.46% in object coverage over the traditional method in the AirSim simulator, and performs better shape completion than PoinTr, the state-of-the-art shape completion model, even on real data obtained from a Velodyne 3D LiDAR mounted on DJI M600 Pro.
Graph Neural Networks for Decentralized Multi-Robot Submodular Action Selection
May 18, 2021



In this paper, we develop a learning-based approach for decentralized submodular maximization. We focus on applications where robots are required to jointly select actions, e.g., motion primitives, to maximize team submodular objectives with local communications only. Such applications are essential for large-scale multi-robot coordination such as multi-robot motion planning for area coverage, environment exploration, and target tracking. But the current decentralized submodular maximization algorithms either require assumptions on the inter-robot communication or lose some suboptimal guarantees. In this work, we propose a general-purpose learning architecture towards submodular maximization at scale, with decentralized communications. Particularly, our learning architecture leverages a graph neural network (GNN) to capture local interactions of the robots and learns decentralized decision-making for the robots. We train the learning model by imitating an expert solution and implement the resulting model for decentralized action selection involving local observations and communications only. We demonstrate the performance of our GNN-based learning approach in a scenario of active target coverage with large networks of robots. The simulation results show our approach nearly matches the coverage performance of the expert algorithm, and yet runs several orders faster with more than 30 robots. The results also exhibit our approach's generalization capability in previously unseen scenarios, e.g., larger environments and larger networks of robots.
Risk-Aware Planning and Assignment for Ground Vehicles using Uncertain Perception from Aerial Vehicles
Mar 25, 2020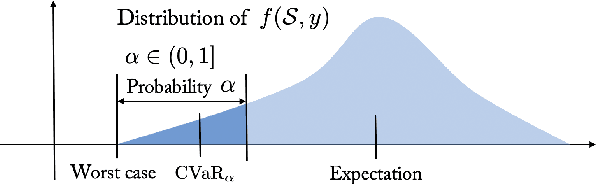



We propose a risk-aware framework for multi-robot, multi-demand assignment and planning in unknown environments. Our motivation is disaster response and search-and-rescue scenarios where ground vehicles must reach demand locations as soon as possible. We consider a setting where the terrain information is available only in the form of an aerial, georeferenced image. Deep learning techniques can be used for semantic segmentation of the aerial image to create a cost map for safe ground robot navigation. Such segmentation may still be noisy. Hence, we present a joint planning and perception framework that accounts for the risk introduced due to noisy perception. Our contributions are two-fold: (i) we show how to use Bayesian deep learning techniques to extract risk at the perception level; and (ii) use a risk-theoretical measure, CVaR, for risk-aware planning and assignment. The pipeline is theoretically established, then empirically analyzed through two datasets. We find that accounting for risk at both levels produces quantifiably safer paths and assignments.