 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Safety Reasoning and Grounding for Open-World Robots
Feb 24, 2026Robots are increasingly operating in open-world environments where safe behavior depends on context: the same hallway may require different navigation strategies when crowded versus empty, or during an emergency versus normal operations. Traditional safety approaches enforce fixed constraints in user-specified contexts, limiting their ability to handle the open-ended contextual variability of real-world deployment. We address this gap via CORE, a safety framework that enables online contextual reasoning, grounding, and enforcement without prior knowledge of the environment (e.g., maps or safety specifications). CORE uses a vision-language model (VLM) to continuously reason about context-dependent safety rules directly from visual observations, grounds these rules in the physical environment, and enforces the resulting spatially-defined safe sets via control barrier functions. We provide probabilistic safety guarantees for CORE that account for perceptual uncertainty, and we demonstrate through simulation and real-world experiments that CORE enforces contextually appropriate behavior in unseen environments, significantly outperforming prior semantic safety methods that lack online contextual reasoning. Ablation studies validate our theoretical guarantees and underscore the importance of both VLM-based reasoning and spatial grounding for enforcing contextual safety in novel settings. We provide additional resources at https://zacravichandran.github.io/CORE.
MIGHTY: Hermite Spline-based Efficient Trajectory Planning
Nov 13, 2025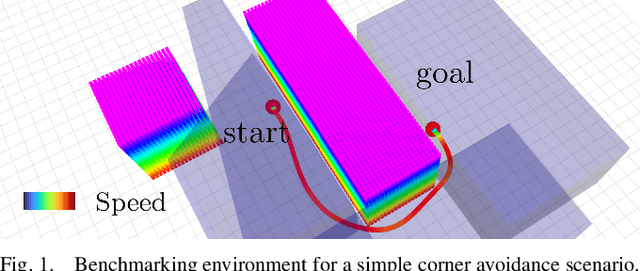

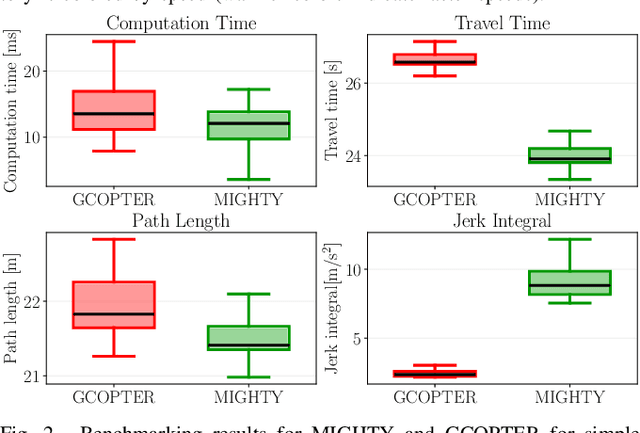
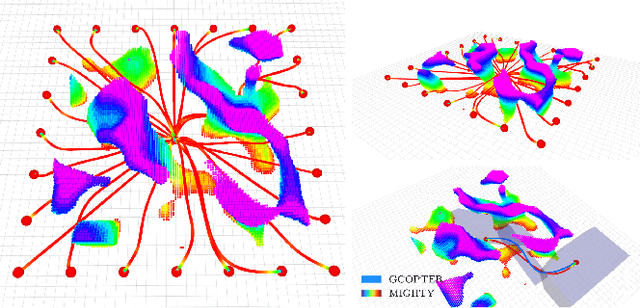
Hard-constraint trajectory planners often rely on commercial solvers and demand substantial computational resources. Existing soft-constraint methods achieve faster computation, but either (1) decouple spatial and temporal optimization or (2) restrict the search space. To overcome these limitations, we introduce MIGHTY, a Hermite spline-based planner that performs spatiotemporal optimization while fully leveraging the continuous search space of a spline. In simulation, MIGHTY achieves a 9.3% reduction in computation time and a 13.1% reduction in travel time over state-of-the-art baselines, with a 100% success rate. In hardware, MIGHTY completes multiple high-speed flights up to 6.7 m/s in a cluttered static environment and long-duration flights with dynamically added obstacles.
Heterogeneous Robot Collaboration in Unstructured Environments with Grounded Generative Intelligence
Oct 30, 2025Heterogeneous robot teams operating in realistic settings often must accomplish complex missions requiring collaboration and adaptation to information acquired online. Because robot teams frequently operate in unstructured environments -- uncertain, open-world settings without prior maps -- subtasks must be grounded in robot capabilities and the physical world. While heterogeneous teams have typically been designed for fixed specifications, generative intelligence opens the possibility of teams that can accomplish a wide range of missions described in natural language. However, current large language model (LLM)-enabled teaming methods typically assume well-structured and known environments, limiting deployment in unstructured environments. We present SPINE-HT, a framework that addresses these limitations by grounding the reasoning abilities of LLMs in the context of a heterogeneous robot team through a three-stage process. Given language specifications describing mission goals and team capabilities, an LLM generates grounded subtasks which are validated for feasibility. Subtasks are then assigned to robots based on capabilities such as traversability or perception and refined given feedback collected during online operation. In simulation experiments with closed-loop perception and control, our framework achieves nearly twice the success rate compared to prior LLM-enabled heterogeneous teaming approaches. In real-world experiments with a Clearpath Jackal, a Clearpath Husky, a Boston Dynamics Spot, and a high-altitude UAV, our method achieves an 87\% success rate in missions requiring reasoning about robot capabilities and refining subtasks with online feedback. More information is provided at https://zacravichandran.github.io/SPINE-HT.
PIP-LLM: Integrating PDDL-Integer Programming with LLMs for Coordinating Multi-Robot Teams Using Natural Language
Oct 26, 2025Enabling robot teams to execute natural language commands requires translating high-level instructions into feasible, efficient multi-robot plans. While Large Language Models (LLMs) combined with Planning Domain Description Language (PDDL) offer promise for single-robot scenarios, existing approaches struggle with multi-robot coordination due to brittle task decomposition, poor scalability, and low coordination efficiency. We introduce PIP-LLM, a language-based coordination framework that consists of PDDL-based team-level planning and Integer Programming (IP) based robot-level planning. PIP-LLMs first decomposes the command by translating the command into a team-level PDDL problem and solves it to obtain a team-level plan, abstracting away robot assignment. Each team-level action represents a subtask to be finished by the team. Next, this plan is translated into a dependency graph representing the subtasks' dependency structure. Such a dependency graph is then used to guide the robot-level planning, in which each subtask node will be formulated as an IP-based task allocation problem, explicitly optimizing travel costs and workload while respecting robot capabilities and user-defined constraints. This separation of planning from assignment allows PIP-LLM to avoid the pitfalls of syntax-based decomposition and scale to larger teams. Experiments across diverse tasks show that PIP-LLM improves plan success rate, reduces maximum and average travel costs, and achieves better load balancing compared to state-of-the-art baselines.
Symskill: Symbol and Skill Co-Invention for Data-Efficient and Real-Time Long-Horizon Manipulation
Oct 02, 2025Multi-step manipulation in dynamic environments remains challenging. Two major families of methods fail in distinct ways: (i) imitation learning (IL) is reactive but lacks compositional generalization, as monolithic policies do not decide which skill to reuse when scenes change; (ii) classical task-and-motion planning (TAMP) offers compositionality but has prohibitive planning latency, preventing real-time failure recovery. We introduce SymSkill, a unified learning framework that combines the benefits of IL and TAMP, allowing compositional generalization and failure recovery in real-time. Offline, SymSkill jointly learns predicates, operators, and skills directly from unlabeled and unsegmented demonstrations. At execution time, upon specifying a conjunction of one or more learned predicates, SymSkill uses a symbolic planner to compose and reorder learned skills to achieve the symbolic goals, while performing recovery at both the motion and symbolic levels in real time. Coupled with a compliant controller, SymSkill enables safe and uninterrupted execution under human and environmental disturbances. In RoboCasa simulation, SymSkill can execute 12 single-step tasks with 85% success rate. Without additional data, it composes these skills into multi-step plans requiring up to 6 skill recompositions, recovering robustly from execution failures. On a real Franka robot, we demonstrate SymSkill, learning from 5 minutes of unsegmented and unlabeled play data, is capable of performing multiple tasks simply by goal specifications. The source code and additional analysis can be found on https://sites.google.com/view/symskill.
Online Multi-Robot Coordination and Cooperation with Task Precedence Relationships
Sep 18, 2025



We propose a new formulation for the multi-robot task allocation problem that incorporates (a) complex precedence relationships between tasks, (b) efficient intra-task coordination, and (c) cooperation through the formation of robot coalitions. A task graph specifies the tasks and their relationships, and a set of reward functions models the effects of coalition size and preceding task performance. Maximizing task rewards is NP-hard; hence, we propose network flow-based algorithms to approximate solutions efficiently. A novel online algorithm performs iterative re-allocation, providing robustness to task failures and model inaccuracies to achieve higher performance than offline approaches. We comprehensively evaluate the algorithms in a testbed with random missions and reward functions and compare them to a mixed-integer solver and a greedy heuristic. Additionally, we validate the overall approach in an advanced simulator, modeling reward functions based on realistic physical phenomena and executing the tasks with realistic robot dynamics. Results establish efficacy in modeling complex missions and efficiency in generating high-fidelity task plans while leveraging task relationships.
KoopMotion: Learning Almost Divergence Free Koopman Flow Fields for Motion Planning
Sep 11, 2025In this work, we propose a novel flow field-based motion planning method that drives a robot from any initial state to a desired reference trajectory such that it converges to the trajectory's end point. Despite demonstrated efficacy in using Koopman operator theory for modeling dynamical systems, Koopman does not inherently enforce convergence to desired trajectories nor to specified goals -- a requirement when learning from demonstrations (LfD). We present KoopMotion which represents motion flow fields as dynamical systems, parameterized by Koopman Operators to mimic desired trajectories, and leverages the divergence properties of the learnt flow fields to obtain smooth motion fields that converge to a desired reference trajectory when a robot is placed away from the desired trajectory, and tracks the trajectory until the end point. To demonstrate the effectiveness of our approach, we show evaluations of KoopMotion on the LASA human handwriting dataset and a 3D manipulator end-effector trajectory dataset, including spectral analysis. We also perform experiments on a physical robot, verifying KoopMotion on a miniature autonomous surface vehicle operating in a non-static fluid flow environment. Our approach is highly sample efficient in both space and time, requiring only 3\% of the LASA dataset to generate dense motion plans. Additionally, KoopMotion provides a significant improvement over baselines when comparing metrics that measure spatial and temporal dynamics modeling efficacy.
A Roadmap for Climate-Relevant Robotics Research
Jul 15, 2025



Climate change is one of the defining challenges of the 21st century, and many in the robotics community are looking for ways to contribute. This paper presents a roadmap for climate-relevant robotics research, identifying high-impact opportunities for collaboration between roboticists and experts across climate domains such as energy, the built environment, transportation, industry, land use, and Earth sciences. These applications include problems such as energy systems optimization, construction, precision agriculture, building envelope retrofits, autonomous trucking, and large-scale environmental monitoring. Critically, we include opportunities to apply not only physical robots but also the broader robotics toolkit - including planning, perception, control, and estimation algorithms - to climate-relevant problems. A central goal of this roadmap is to inspire new research directions and collaboration by highlighting specific, actionable problems at the intersection of robotics and climate. This work represents a collaboration between robotics researchers and domain experts in various climate disciplines, and it serves as an invitation to the robotics community to bring their expertise to bear on urgent climate priorities.
Robotic Monitoring of Colorimetric Leaf Sensors for Precision Agriculture
May 20, 2025Current remote sensing technologies that measure crop health e.g. RGB, multispectral, hyperspectral, and LiDAR, are indirect, and cannot capture plant stress indicators directly. Instead, low-cost leaf sensors that directly interface with the crop surface present an opportunity to advance real-time direct monitoring. To this end, we co-design a sensor-detector system, where the sensor is a novel colorimetric leaf sensor that directly measures crop health in a precision agriculture setting, and the detector autonomously obtains optical signals from these leaf sensors. This system integrates a ground robot platform with an on-board monocular RGB camera and object detector to localize the leaf sensor, and a hyperspectral camera with motorized mirror and an on-board halogen light to acquire a hyperspectral reflectance image of the leaf sensor, from which a spectral response characterizing crop health can be extracted. We show a successful demonstration of our co-designed system operating in outdoor environments, obtaining spectra that are interpretable when compared to controlled laboratory-grade spectrometer measurements. The system is demonstrated in row-crop environments both indoors and outdoors where it is able to autonomously navigate, locate and obtain a hyperspectral image of all leaf sensors present, and retrieve interpretable spectral resonance from leaf sensors.
Gaussian Splatting as a Unified Representation for Autonomy in Unstructured Environments
May 17, 2025In this work, we argue that Gaussian splatting is a suitable unified representation for autonomous robot navigation in large-scale unstructured outdoor environments. Such environments require representations that can capture complex structures while remaining computationally tractable for real-time navigation. We demonstrate that the dense geometric and photometric information provided by a Gaussian splatting representation is useful for navigation in unstructured environments. Additionally, semantic information can be embedded in the Gaussian map to enable large-scale task-driven navigation. From the lessons learned through our experiments, we highlight several challenges and opportunities arising from the use of such a representation for robot autonomy.