 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Robot Platform for Robotic Triage Combining Onboard Sensing and Foundation Models
Dec 09, 2025
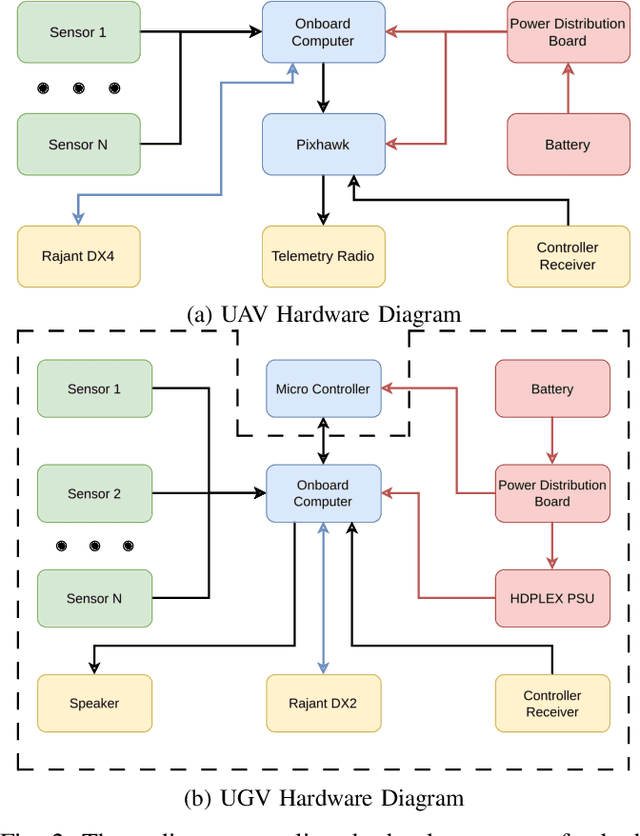
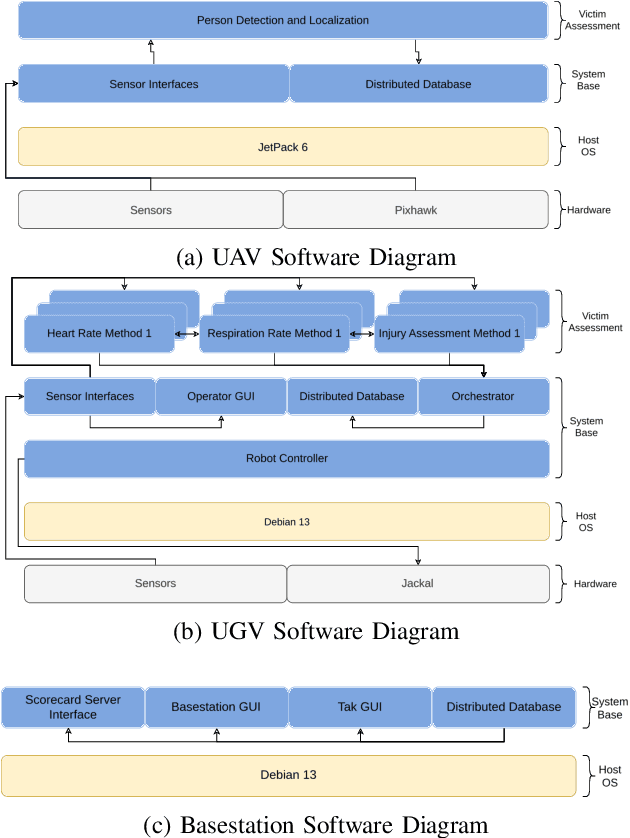
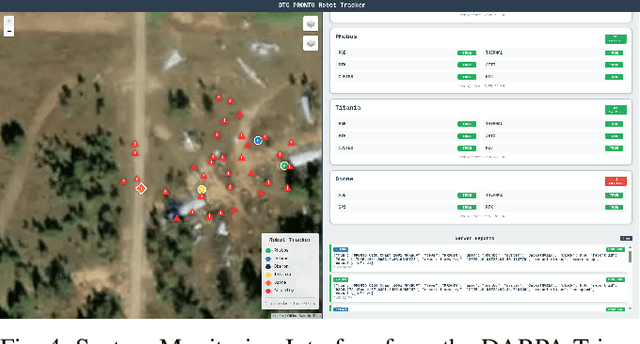
This report presents a heterogeneous robotic system designed for remote primary triage in mass-casualty incidents (MCIs). The system employs a coordinated air-ground team of unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs) to locate victims, assess their injuries, and prioritize medical assistance without risking the lives of first responders. The UAV identify and provide overhead views of casualties, while UGVs equipped with specialized sensors measure vital signs and detect and localize physical injuries. Unlike previous work that focused on exploration or limited medical evaluation, this system addresses the complete triage process: victim localization, vital sign measurement, injury severity classification, mental status assessment, and data consolidation for first responders. Developed as part of the DARPA Triage Challenge, this approach demonstrates how multi-robot systems can augment human capabilities in disaster response scenarios to maximize lives saved.
Heterogeneous Robot Collaboration in Unstructured Environments with Grounded Generative Intelligence
Oct 30, 2025Heterogeneous robot teams operating in realistic settings often must accomplish complex missions requiring collaboration and adaptation to information acquired online. Because robot teams frequently operate in unstructured environments -- uncertain, open-world settings without prior maps -- subtasks must be grounded in robot capabilities and the physical world. While heterogeneous teams have typically been designed for fixed specifications, generative intelligence opens the possibility of teams that can accomplish a wide range of missions described in natural language. However, current large language model (LLM)-enabled teaming methods typically assume well-structured and known environments, limiting deployment in unstructured environments. We present SPINE-HT, a framework that addresses these limitations by grounding the reasoning abilities of LLMs in the context of a heterogeneous robot team through a three-stage process. Given language specifications describing mission goals and team capabilities, an LLM generates grounded subtasks which are validated for feasibility. Subtasks are then assigned to robots based on capabilities such as traversability or perception and refined given feedback collected during online operation. In simulation experiments with closed-loop perception and control, our framework achieves nearly twice the success rate compared to prior LLM-enabled heterogeneous teaming approaches. In real-world experiments with a Clearpath Jackal, a Clearpath Husky, a Boston Dynamics Spot, and a high-altitude UAV, our method achieves an 87\% success rate in missions requiring reasoning about robot capabilities and refining subtasks with online feedback. More information is provided at https://zacravichandran.github.io/SPINE-HT.
Adaptive Per-Tree Canopy Volume Estimation Using Mobile LiDAR in Structured and Unstructured Orchards
Jun 09, 2025We present a real-time system for per-tree canopy volume estimation using mobile LiDAR data collected during routine robotic navigation. Unlike prior approaches that rely on static scans or assume uniform orchard structures, our method adapts to varying field geometries via an integrated pipeline of LiDAR-inertial odometry, adaptive segmentation, and geometric reconstruction. We evaluate the system across two commercial orchards, one pistachio orchard with regular spacing and one almond orchard with dense, overlapping crowns. A hybrid clustering strategy combining DBSCAN and spectral clustering enables robust per-tree segmentation, achieving 93% success in pistachio and 80% in almond, with strong agreement to drone derived canopy volume estimates. This work advances scalable, non-intrusive tree monitoring for structurally diverse orchard environments.
Deploying Foundation Model-Enabled Air and Ground Robots in the Field: Challenges and Opportunities
May 14, 2025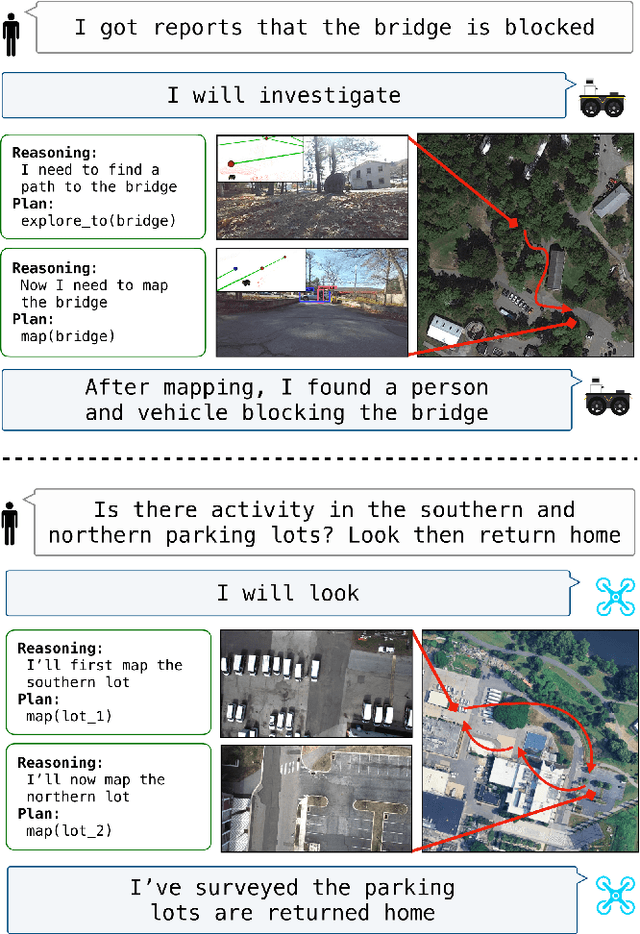
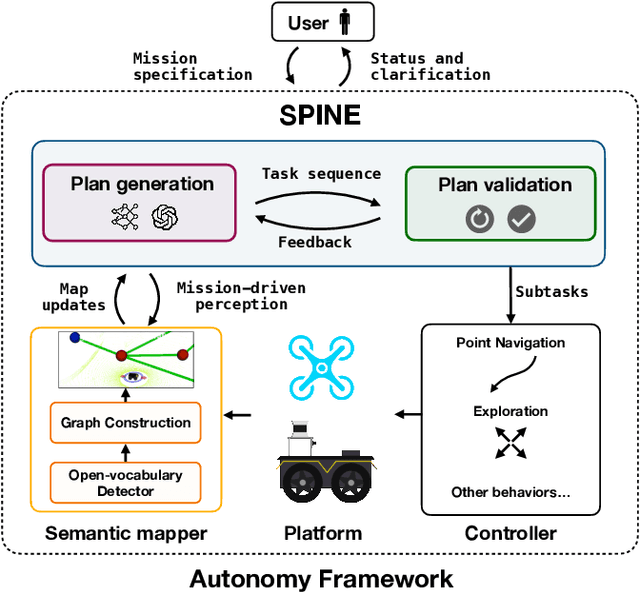

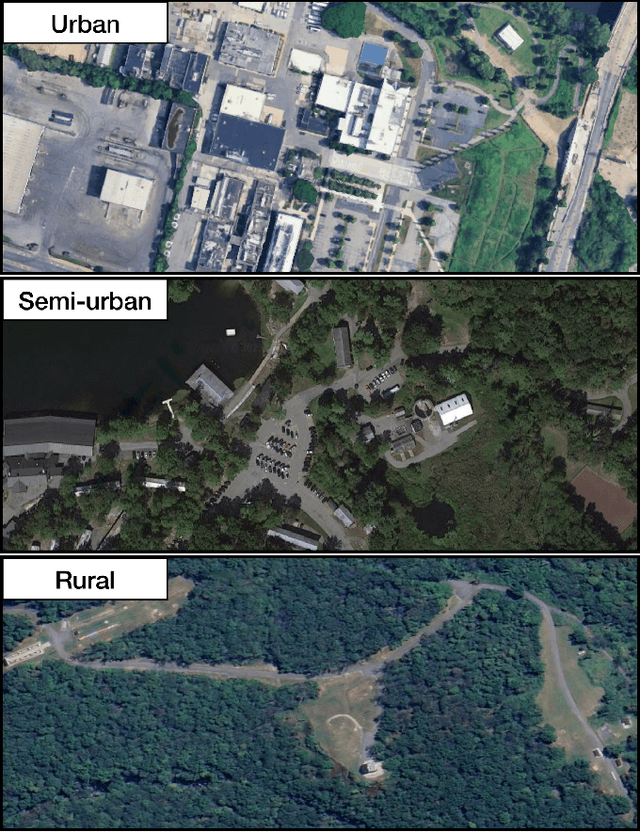
The integration of foundation models (FMs) into robotics has enabled robots to understand natural language and reason about the semantics in their environments. However, existing FM-enabled robots primary operate in closed-world settings, where the robot is given a full prior map or has a full view of its workspace. This paper addresses the deployment of FM-enabled robots in the field, where missions often require a robot to operate in large-scale and unstructured environments. To effectively accomplish these missions, robots must actively explore their environments, navigate obstacle-cluttered terrain, handle unexpected sensor inputs, and operate with compute constraints. We discuss recent deployments of SPINE, our LLM-enabled autonomy framework, in field robotic settings. To the best of our knowledge, we present the first demonstration of large-scale LLM-enabled robot planning in unstructured environments with several kilometers of missions. SPINE is agnostic to a particular LLM, which allows us to distill small language models capable of running onboard size, weight and power (SWaP) limited platforms. Via preliminary model distillation work, we then present the first language-driven UAV planner using on-device language models. We conclude our paper by proposing several promising directions for future research.
Air-Ground Collaboration for Language-Specified Missions in Unknown Environments
May 14, 2025As autonomous robotic systems become increasingly mature, users will want to specify missions at the level of intent rather than in low-level detail. Language is an expressive and intuitive medium for such mission specification. However, realizing language-guided robotic teams requires overcoming significant technical hurdles. Interpreting and realizing language-specified missions requires advanced semantic reasoning. Successful heterogeneous robots must effectively coordinate actions and share information across varying viewpoints. Additionally, communication between robots is typically intermittent, necessitating robust strategies that leverage communication opportunities to maintain coordination and achieve mission objectives. In this work, we present a first-of-its-kind system where an unmanned aerial vehicle (UAV) and an unmanned ground vehicle (UGV) are able to collaboratively accomplish missions specified in natural language while reacting to changes in specification on the fly. We leverage a Large Language Model (LLM)-enabled planner to reason over semantic-metric maps that are built online and opportunistically shared between an aerial and a ground robot. We consider task-driven navigation in urban and rural areas. Our system must infer mission-relevant semantics and actively acquire information via semantic mapping. In both ground and air-ground teaming experiments, we demonstrate our system on seven different natural-language specifications at up to kilometer-scale navigation.
Estimating the Diameter at Breast Height of Trees in a Forest With a Single 360 Camera
May 06, 2025Forest inventories rely on accurate measurements of the diameter at breast height (DBH) for ecological monitoring, resource management, and carbon accounting. While LiDAR-based techniques can achieve centimeter-level precision, they are cost-prohibitive and operationally complex. We present a low-cost alternative that only needs a consumer-grade 360 video camera. Our semi-automated pipeline comprises of (i) a dense point cloud reconstruction using Structure from Motion (SfM) photogrammetry software called Agisoft Metashape, (ii) semantic trunk segmentation by projecting Grounded Segment Anything (SAM) masks onto the 3D cloud, and (iii) a robust RANSAC-based technique to estimate cross section shape and DBH. We introduce an interactive visualization tool for inspecting segmented trees and their estimated DBH. On 61 acquisitions of 43 trees under a variety of conditions, our method attains median absolute relative errors of 5-9% with respect to "ground-truth" manual measurements. This is only 2-4% higher than LiDAR-based estimates, while employing a single 360 camera that costs orders of magnitude less, requires minimal setup, and is widely available.
4D Metric-Semantic Mapping for Persistent Orchard Monitoring: Method and Dataset
Sep 29, 2024
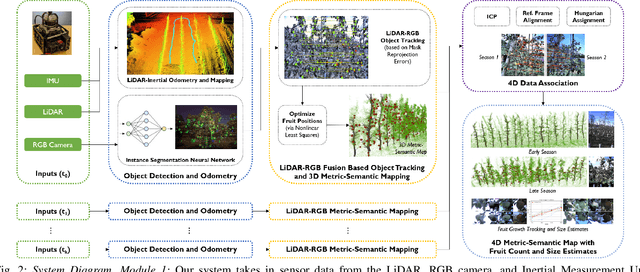


Automated persistent and fine-grained monitoring of orchards at the individual tree or fruit level helps maximize crop yield and optimize resources such as water, fertilizers, and pesticides while preventing agricultural waste. Towards this goal, we present a 4D spatio-temporal metric-semantic mapping method that fuses data from multiple sensors, including LiDAR, RGB camera, and IMU, to monitor the fruits in an orchard across their growth season. A LiDAR-RGB fusion module is designed for 3D fruit tracking and localization, which first segments fruits using a deep neural network and then tracks them using the Hungarian Assignment algorithm. Additionally, the 4D data association module aligns data from different growth stages into a common reference frame and tracks fruits spatio-temporally, providing information such as fruit counts, sizes, and positions. We demonstrate our method's accuracy in 4D metric-semantic mapping using data collected from a real orchard under natural, uncontrolled conditions with seasonal variations. We achieve a 3.1 percent error in total fruit count estimation for over 1790 fruits across 60 apple trees, along with accurate size estimation results with a mean error of 1.1 cm. The datasets, consisting of LiDAR, RGB, and IMU data of five fruit species captured across their growth seasons, along with corresponding ground truth data, will be made publicly available at: https://4d-metric-semantic-mapping.org/
EvMAPPER: High Altitude Orthomapping with Event Cameras
Sep 26, 2024



Traditionally, unmanned aerial vehicles (UAVs) rely on CMOS-based cameras to collect images about the world below. One of the most successful applications of UAVs is to generate orthomosaics or orthomaps, in which a series of images are integrated together to develop a larger map. However, the use of CMOS-based cameras with global or rolling shutters mean that orthomaps are vulnerable to challenging light conditions, motion blur, and high-speed motion of independently moving objects under the camera. Event cameras are less sensitive to these issues, as their pixels are able to trigger asynchronously on brightness changes. This work introduces the first orthomosaic approach using event cameras. In contrast to existing methods relying only on CMOS cameras, our approach enables map generation even in challenging light conditions, including direct sunlight and after sunset.
Air-Ground Collaboration with SPOMP: Semantic Panoramic Online Mapping and Planning
Jul 13, 2024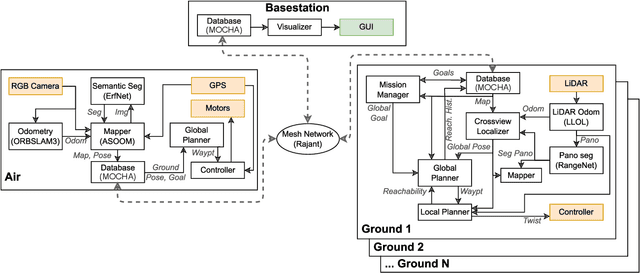


Mapping and navigation have gone hand-in-hand since long before robots existed. Maps are a key form of communication, allowing someone who has never been somewhere to nonetheless navigate that area successfully. In the context of multi-robot systems, the maps and information that flow between robots are necessary for effective collaboration, whether those robots are operating concurrently, sequentially, or completely asynchronously. In this paper, we argue that maps must go beyond encoding purely geometric or visual information to enable increasingly complex autonomy, particularly between robots. We propose a framework for multi-robot autonomy, focusing in particular on air and ground robots operating in outdoor 2.5D environments. We show that semantic maps can enable the specification, planning, and execution of complex collaborative missions, including localization in GPS-denied settings. A distinguishing characteristic of this work is that we strongly emphasize field experiments and testing, and by doing so demonstrate that these ideas can work at scale in the real world. We also perform extensive simulation experiments to validate our ideas at even larger scales. We believe these experiments and the experimental results constitute a significant step forward toward advancing the state-of-the-art of large-scale, collaborative multi-robot systems operating with real communication, navigation, and perception constraints.
* Video: https://www.youtube.com/watch?v=ieNYH40buBo
Challenges and Opportunities for Large-Scale Exploration with Air-Ground Teams using Semantics
May 12, 2024



One common and desirable application of robots is exploring potentially hazardous and unstructured environments. Air-ground collaboration offers a synergistic approach to addressing such exploration challenges. In this paper, we demonstrate a system for large-scale exploration using a team of aerial and ground robots. Our system uses semantics as lingua franca, and relies on fully opportunistic communications. We highlight the unique challenges from this approach, explain our system architecture and showcase lessons learned during our experiments. All our code is open-source, encouraging researchers to use it and build upon.