 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAir-Ground Collaboration with SPOMP: Semantic Panoramic Online Mapping and Planning
Jul 13, 2024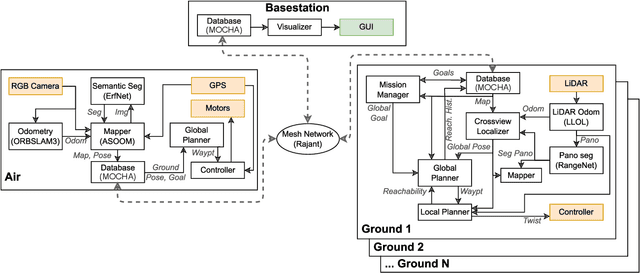


Mapping and navigation have gone hand-in-hand since long before robots existed. Maps are a key form of communication, allowing someone who has never been somewhere to nonetheless navigate that area successfully. In the context of multi-robot systems, the maps and information that flow between robots are necessary for effective collaboration, whether those robots are operating concurrently, sequentially, or completely asynchronously. In this paper, we argue that maps must go beyond encoding purely geometric or visual information to enable increasingly complex autonomy, particularly between robots. We propose a framework for multi-robot autonomy, focusing in particular on air and ground robots operating in outdoor 2.5D environments. We show that semantic maps can enable the specification, planning, and execution of complex collaborative missions, including localization in GPS-denied settings. A distinguishing characteristic of this work is that we strongly emphasize field experiments and testing, and by doing so demonstrate that these ideas can work at scale in the real world. We also perform extensive simulation experiments to validate our ideas at even larger scales. We believe these experiments and the experimental results constitute a significant step forward toward advancing the state-of-the-art of large-scale, collaborative multi-robot systems operating with real communication, navigation, and perception constraints.
* Video: https://www.youtube.com/watch?v=ieNYH40buBo
Challenges and Opportunities for Large-Scale Exploration with Air-Ground Teams using Semantics
May 12, 2024



One common and desirable application of robots is exploring potentially hazardous and unstructured environments. Air-ground collaboration offers a synergistic approach to addressing such exploration challenges. In this paper, we demonstrate a system for large-scale exploration using a team of aerial and ground robots. Our system uses semantics as lingua franca, and relies on fully opportunistic communications. We highlight the unique challenges from this approach, explain our system architecture and showcase lessons learned during our experiments. All our code is open-source, encouraging researchers to use it and build upon.
Enabling Large-scale Heterogeneous Collaboration with Opportunistic Communications
Sep 27, 2023Multi-robot collaboration in large-scale environments with limited-sized teams and without external infrastructure is challenging, since the software framework required to support complex tasks must be robust to unreliable and intermittent communication links. In this work, we present MOCHA (Multi-robot Opportunistic Communication for Heterogeneous Collaboration), a framework for resilient multi-robot collaboration that enables large-scale exploration in the absence of continuous communications. MOCHA is based on a gossip communication protocol that allows robots to interact opportunistically whenever communication links are available, propagating information on a peer-to-peer basis. We demonstrate the performance of MOCHA through real-world experiments with commercial-off-the-shelf (COTS) communication hardware. We further explore the system's scalability in simulation, evaluating the performance of our approach as the number of robots increases and communication ranges vary. Finally, we demonstrate how MOCHA can be tightly integrated with the planning stack of autonomous robots. We show a communication-aware planning algorithm for a high-altitude aerial robot executing a collaborative task while maximizing the amount of information shared with ground robots. The source code for MOCHA and the high-altitude UAV planning system is available open source: http://github.com/KumarRobotics/MOCHA, http://github.com/KumarRobotics/air_router.
Active Metric-Semantic Mapping by Multiple Aerial Robots
Sep 24, 2022

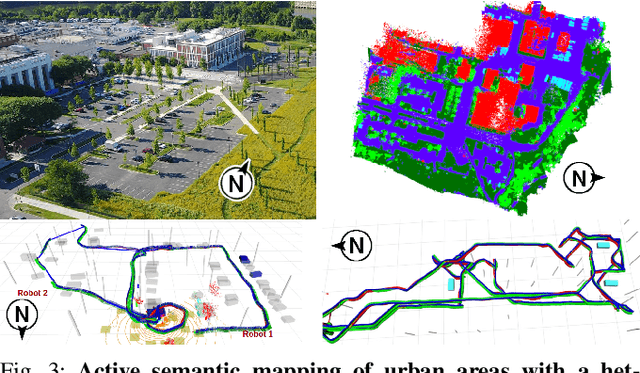
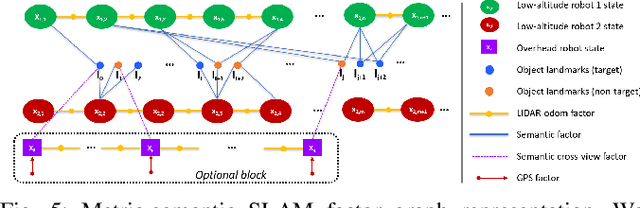
Traditional approaches for active mapping focus on building geometric maps. For most real-world applications, however, actionable information is related to semantically meaningful objects in the environment. We propose an approach to the active metric-semantic mapping problem that enables multiple heterogeneous robots to collaboratively build a map of the environment. The robots actively explore to minimize the uncertainties in both semantic (object classification) and geometric (object modeling) information. We represent the environment using informative but sparse object models, each consisting of a basic shape and a semantic class label, and characterize uncertainties empirically using a large amount of real-world data. Given a prior map, we use this model to select actions for each robot to minimize uncertainties. The performance of our algorithm is demonstrated through multi-robot experiments in diverse real-world environments. The proposed framework is applicable to a wide range of real-world problems, such as precision agriculture, infrastructure inspection, and asset mapping in factories. A demo video can be found at https://youtu.be/S86SgXi54oU.
Stronger Together: Air-Ground Robotic Collaboration Using Semantics
Jun 28, 2022
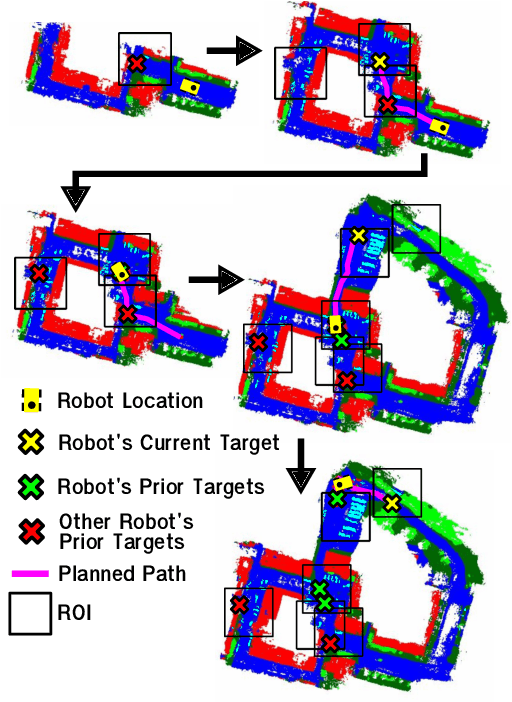

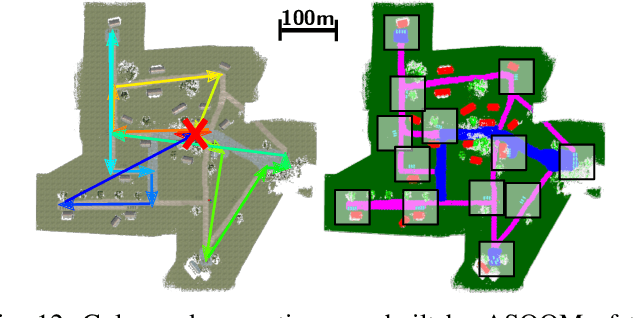
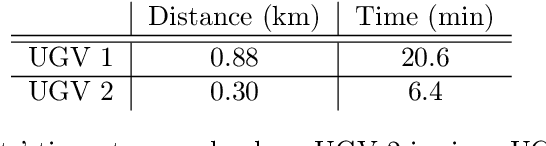
In this work, we present an end-to-end heterogeneous multi-robot system framework where ground robots are able to localize, plan, and navigate in a semantic map created in real time by a high-altitude quadrotor. The ground robots choose and deconflict their targets independently, without any external intervention. Moreover, they perform cross-view localization by matching their local maps with the overhead map using semantics. The communication backbone is opportunistic and distributed, allowing the entire system to operate with no external infrastructure aside from GPS for the quadrotor. We extensively tested our system by performing different missions on top of our framework over multiple experiments in different environments. Our ground robots travelled over 6 km autonomously with minimal intervention in the real world and over 96 km in simulation without interventions.
Any Way You Look At It: Semantic Crossview Localization and Mapping with LiDAR
Mar 16, 2022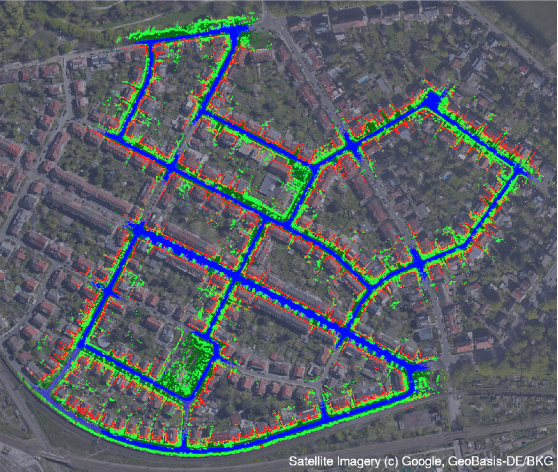
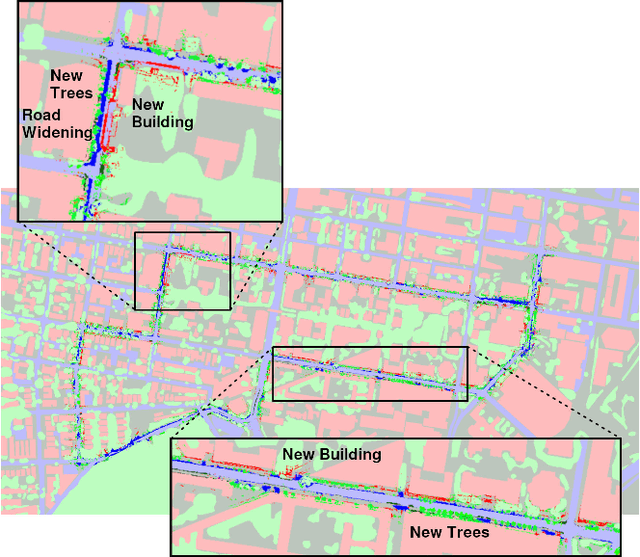
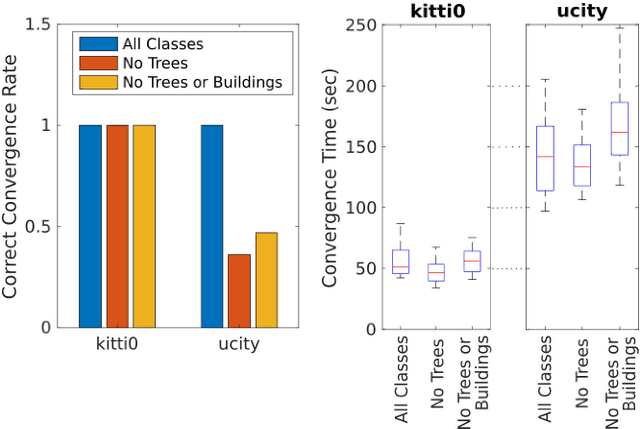
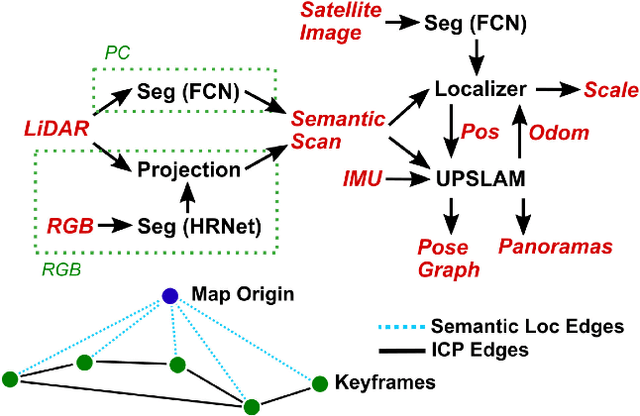
Currently, GPS is by far the most popular global localization method. However, it is not always reliable or accurate in all environments. SLAM methods enable local state estimation but provide no means of registering the local map to a global one, which can be important for inter-robot collaboration or human interaction. In this work, we present a real-time method for utilizing semantics to globally localize a robot using only egocentric 3D semantically labelled LiDAR and IMU as well as top-down RGB images obtained from satellites or aerial robots. Additionally, as it runs, our method builds a globally registered, semantic map of the environment. We validate our method on KITTI as well as our own challenging datasets, and show better than 10 meter accuracy, a high degree of robustness, and the ability to estimate the scale of a top-down map on the fly if it is initially unknown.
* Published in the IEEE Robotics and Automation Letters and presented at the IEEE 2021 International Conference on Robotics and Automation. See https://www.youtube.com/watch?v=_qwAoYK9iGU for accompanying video
DSOL: A Fast Direct Sparse Odometry Scheme
Mar 15, 2022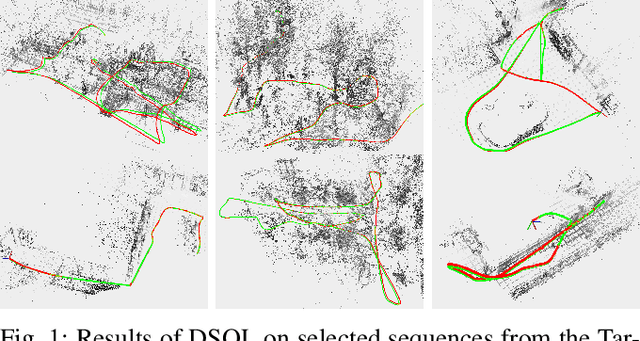


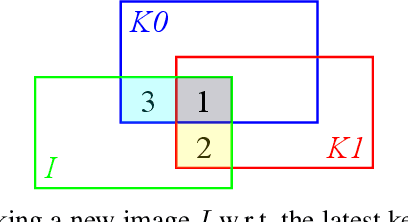
In this paper, we describe Direct Sparse Odometry Lite (DSOL), an improved version of Direct Sparse Odometry (DSO). We propose several algorithmic and implementation enhancements which speed up computation by a significant factor (on average 5x) even on resource constrained platforms. The increase in speed allows us to process images at higher frame rates, which in turn provides better results on rapid motions. Our open-source implementation is available at https://github.com/versatran01/dsol.
UPSLAM: Union of Panoramas SLAM
Jan 03, 2021
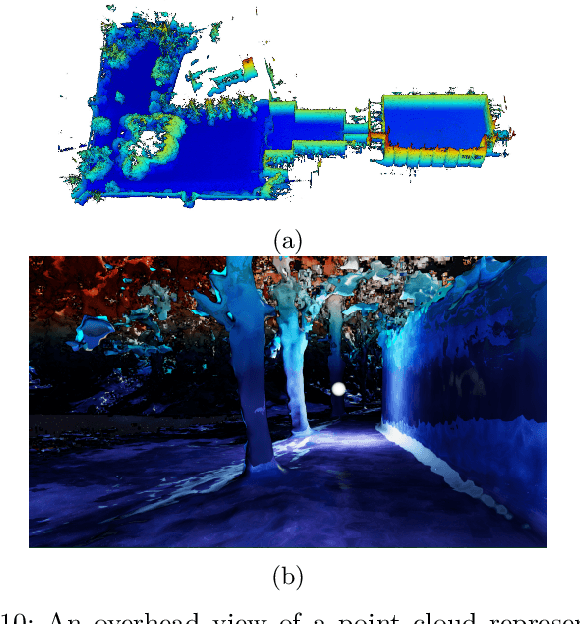
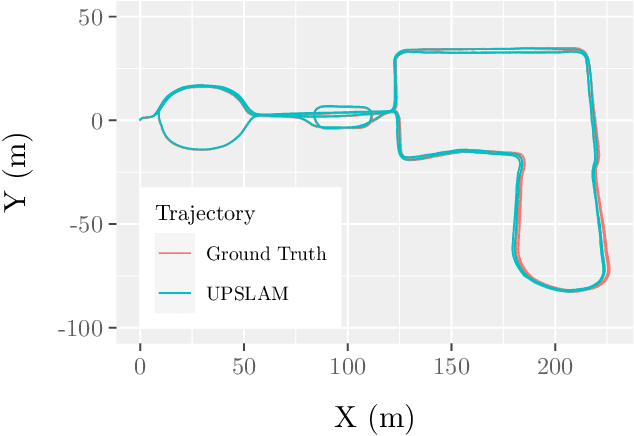
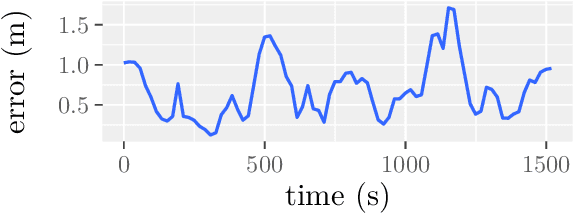
We present an empirical investigation of a new mapping system based on a graph of panoramic depth images. Panoramic images efficiently capture range measurements taken by a spinning lidar sensor, recording fine detail on the order of a few centimeters within maps of expansive scope on the order of tens of millions of cubic meters. The flexibility of the system is demonstrated by running the same mapping software against data collected by hand-carrying a sensor around a laboratory space at walking pace, moving it outdoors through a campus environment at running pace, driving the sensor on a small wheeled vehicle on- and off-road, flying the sensor through a forest, carrying it on the back of a legged robot navigating an underground coal mine, and mounting it on the roof of a car driven on public roads. The full 3D maps are built online with a median update time of less than ten milliseconds on an embedded NVIDIA Jetson AGX Xavier system.
PennSyn2Real: Training Object Recognition Models without Human Labeling
Oct 16, 2020

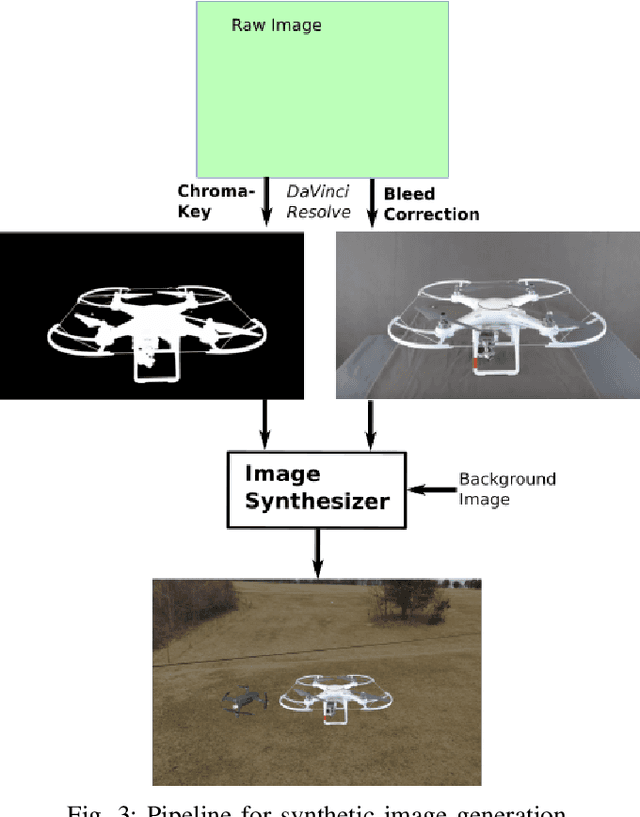
Scalable training data generation is a critical problem in deep learning. We propose PennSyn2Real - a photo-realistic synthetic dataset consisting of more than 100,000 4K images of more than 20 types of micro aerial vehicles (MAVs). The dataset can be used to generate arbitrary numbers of training images for high-level computer vision tasks such as MAV detection and classification. Our data generation framework bootstraps chroma-keying, a mature cinematography technique with a motion tracking system, providing artifact-free and curated annotated images where object orientations and lighting are controlled. This framework is easy to set up and can be applied to a broad range of objects, reducing the gap between synthetic and real-world data. We show that synthetic data generated using this framework can be directly used to train CNN models for common object recognition tasks such as detection and segmentation. We demonstrate competitive performance in comparison with training using only real images. Furthermore, bootstrapping the generated synthetic data in few-shot learning can significantly improve the overall performance, reducing the number of required training data samples to achieve the desired accuracy.
Mine Tunnel Exploration using Multiple Quadrupedal Robots
Sep 20, 2019
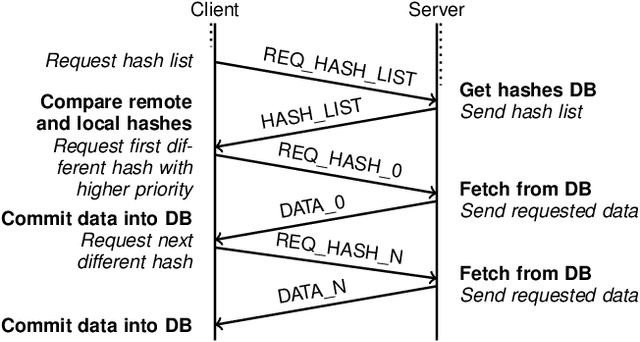
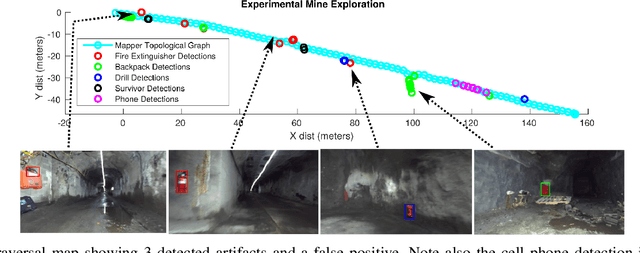
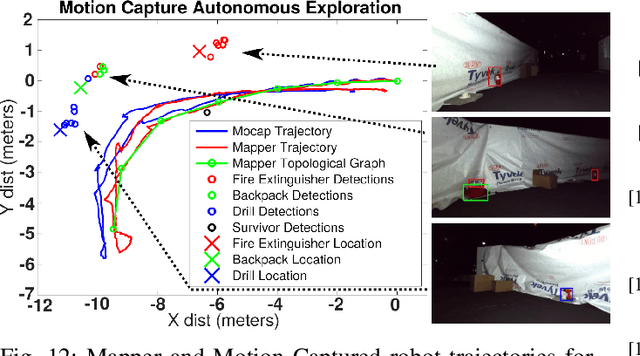
Robotic exploration of underground environments is a particularly challenging problem due to communication, endurance, and traversability constraints which necessitate high degrees of autonomy and agility. These challenges are further enhanced by the need to minimize human intervention for practical applications. While legged robots have the ability to traverse extremely challenging terrain, they also engender further inherent challenges for planning, estimation, and control. In this work, we describe a fully autonomous system for multi-robot mine exploration and mapping using legged quadrupeds, as well as a distributed database mesh networking system for reporting data. In addition, we show results from the DARPA Subterranean Challenge (SubT) Tunnel Circuit demonstrating localization of artifacts after traversals of hundreds of meters. To our knowledge, these experiments represent the first fully autonomous exploration of an unknown GNSS-denied environment undertaken by legged robots.