 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny Way You Look At It: Semantic Crossview Localization and Mapping with LiDAR
Mar 16, 2022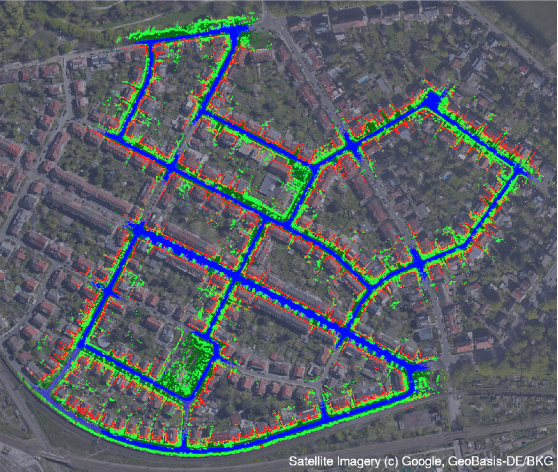
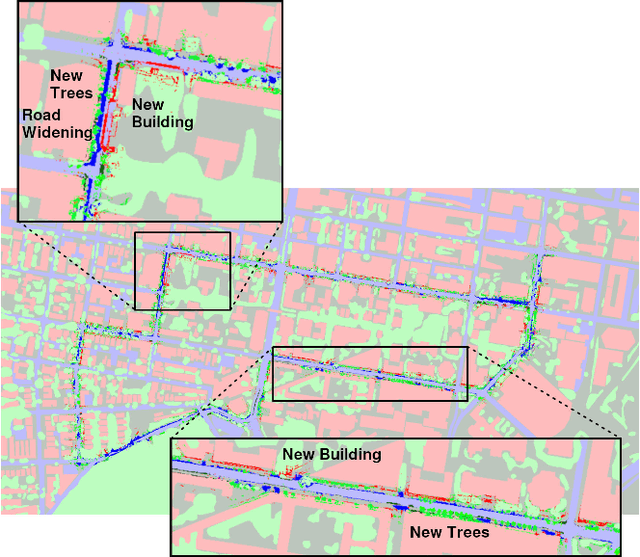
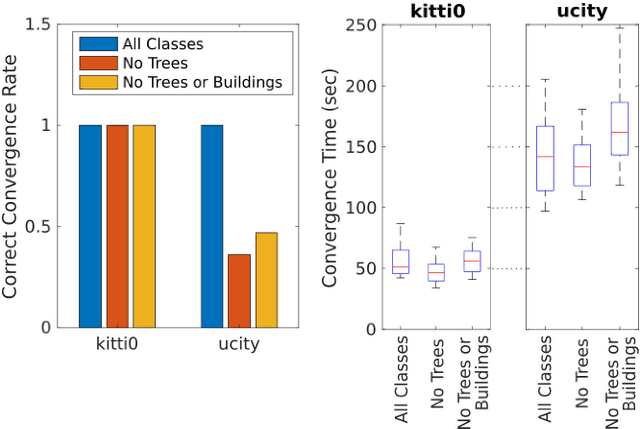
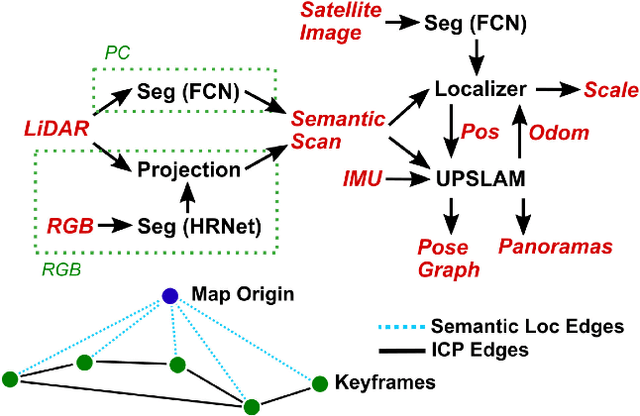
Currently, GPS is by far the most popular global localization method. However, it is not always reliable or accurate in all environments. SLAM methods enable local state estimation but provide no means of registering the local map to a global one, which can be important for inter-robot collaboration or human interaction. In this work, we present a real-time method for utilizing semantics to globally localize a robot using only egocentric 3D semantically labelled LiDAR and IMU as well as top-down RGB images obtained from satellites or aerial robots. Additionally, as it runs, our method builds a globally registered, semantic map of the environment. We validate our method on KITTI as well as our own challenging datasets, and show better than 10 meter accuracy, a high degree of robustness, and the ability to estimate the scale of a top-down map on the fly if it is initially unknown.
* Published in the IEEE Robotics and Automation Letters and presented at the IEEE 2021 International Conference on Robotics and Automation. See https://www.youtube.com/watch?v=_qwAoYK9iGU for accompanying video
PennSyn2Real: Training Object Recognition Models without Human Labeling
Oct 16, 2020

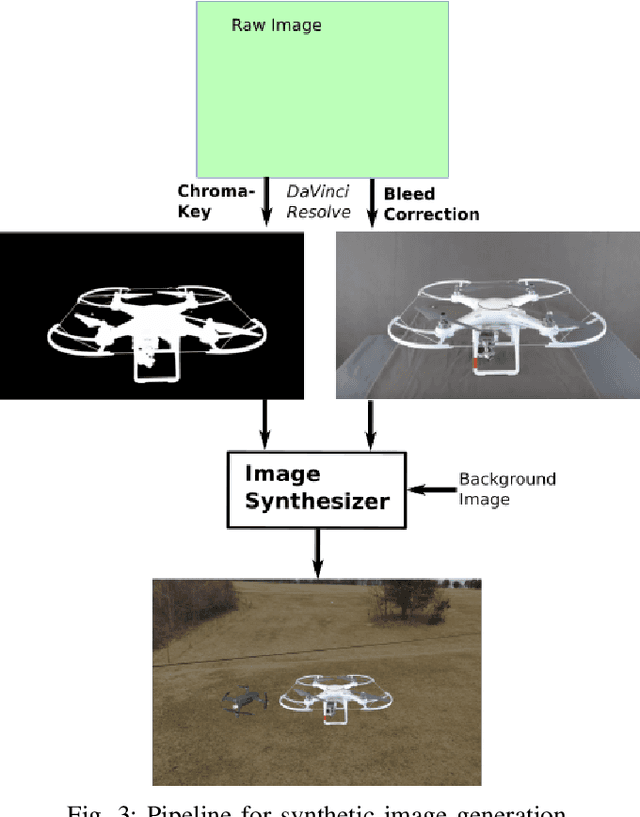
Scalable training data generation is a critical problem in deep learning. We propose PennSyn2Real - a photo-realistic synthetic dataset consisting of more than 100,000 4K images of more than 20 types of micro aerial vehicles (MAVs). The dataset can be used to generate arbitrary numbers of training images for high-level computer vision tasks such as MAV detection and classification. Our data generation framework bootstraps chroma-keying, a mature cinematography technique with a motion tracking system, providing artifact-free and curated annotated images where object orientations and lighting are controlled. This framework is easy to set up and can be applied to a broad range of objects, reducing the gap between synthetic and real-world data. We show that synthetic data generated using this framework can be directly used to train CNN models for common object recognition tasks such as detection and segmentation. We demonstrate competitive performance in comparison with training using only real images. Furthermore, bootstrapping the generated synthetic data in few-shot learning can significantly improve the overall performance, reducing the number of required training data samples to achieve the desired accuracy.
Evaluating Robust, Perception Based Control with Quadrotors
Jul 08, 2020
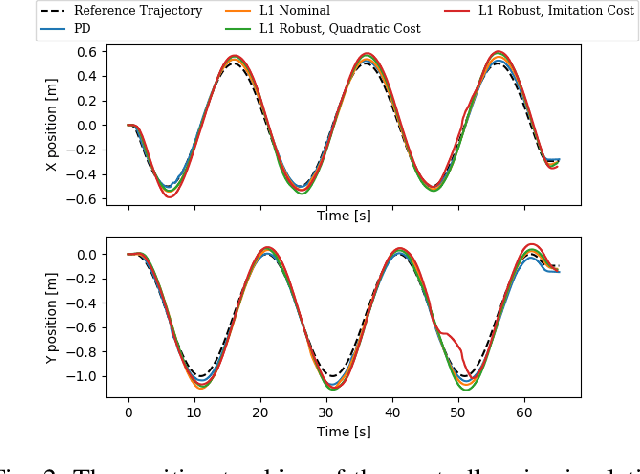
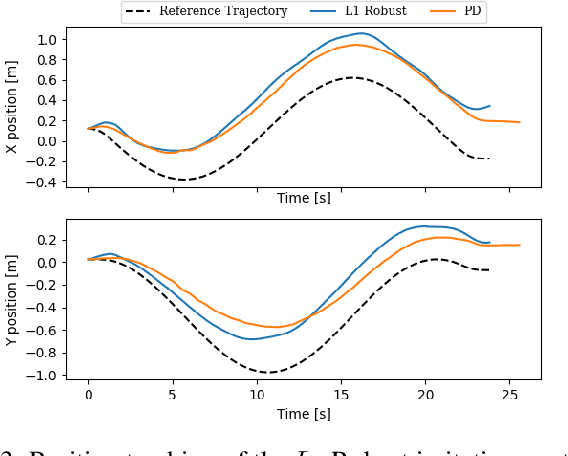
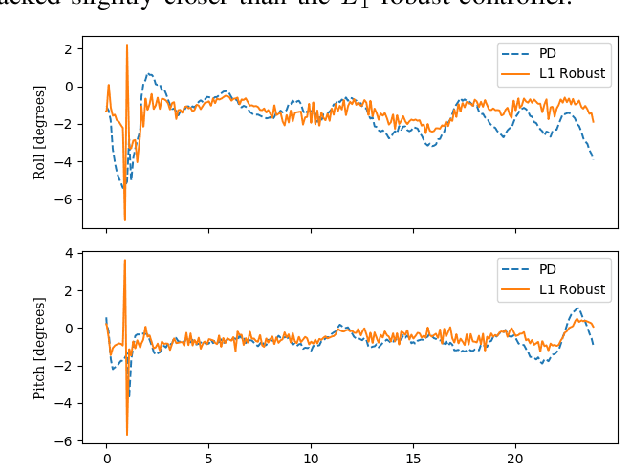
Traditionally, controllers and state estimators in robotic systems are designed independently. Controllers are often designed assuming perfect state estimation. However, state estimation methods such as Visual Inertial Odometry (VIO) drift over time and can cause the system to misbehave. While state estimation error can be corrected with the aid of GPS or motion capture, these complementary sensors are not always available or reliable. Recent work has shown that this issue can be dealt with by synthesizing robust controllers using a data-driven characterization of the perception error, and can bound the system's response to state estimation error using a robustness constraint. We investigate the application of this robust perception-based approach to a quadrotor model using VIO for state estimation and demonstrate the benefits and drawbacks of using this technique in simulation and hardware. Additionally, to make tuning easier, we introduce a new cost function to use in the control synthesis which allows one to take an existing controller and "robustify" it. To the best of our knowledge, this is the first robust perception-based controller implemented in real hardware, as well as one utilizing a data-driven perception model. We believe this as an important step towards safe, robust robots that explicitly account for the inherent dependence between perception and control.
Depth Completion via Deep Basis Fitting
Dec 21, 2019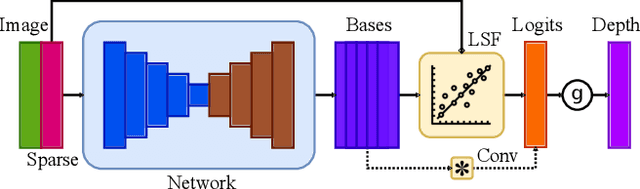
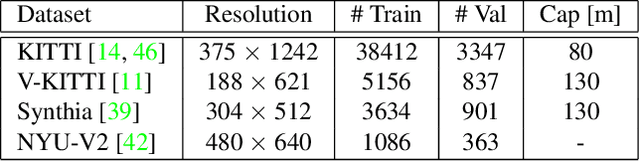
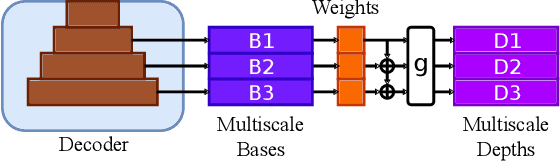
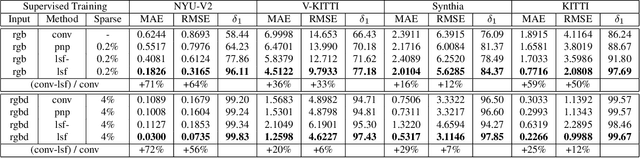
In this paper we consider the task of image-guided depth completion where our system must infer the depth at every pixel of an input image based on the image content and a sparse set of depth measurements. We propose a novel approach that builds upon the strengths of modern deep learning techniques and classical optimization algorithms and significantly improves performance. The proposed method replaces the final $1\times 1$ convolutional layer employed in most depth completion networks with a least squares fitting module which computes weights by fitting the implicit depth bases to the given sparse depth measurements. In addition, we show how our proposed method can be naturally extended to a multi-scale formulation for improved self-supervised training. We demonstrate through extensive experiments on various datasets that our approach achieves consistent improvements over state-of-the-art baseline methods with small computational overhead.
Vision-based Multi-MAV Localization with Anonymous Relative Measurements Using Coupled Probabilistic Data Association Filter
Sep 18, 2019


We address the localization of robots in a multi-MAV system where external infrastructure like GPS or motion capture system may not be available. We introduce a vision plus IMU system for localization that uses relative distance and bearing measurements. Our approach lends itself to implementation on platforms with several constraints on size, weight, and payload (SWaP). Particularly, our framework fuses the odometry with anonymous, visual-based robot-to-robot detection to estimate all robot poses in one common frame, addressing three main challenges: 1) initial configuration of the robot team is unknown, 2) data association between detection and robot targets is unknown, and 3) vision-based detection yields false negatives, false positives, inaccurate, noisy bearing and distance measurements of other robots. Our approach extends the Coupled Probabilistic Data Association Filter (CPDAF) to cope with nonlinear measurements. We demonstrate the superior performance of our approach over a simple VIO-based method in a simulation using measurement models obtained from real data. We also show how on-board sensing, estimation and control can be used for formation flight.
DFineNet: Ego-Motion Estimation and Depth Refinement from Sparse, Noisy Depth Input with RGB Guidance
Apr 10, 2019

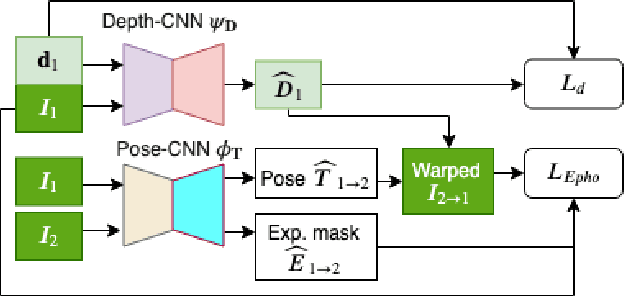

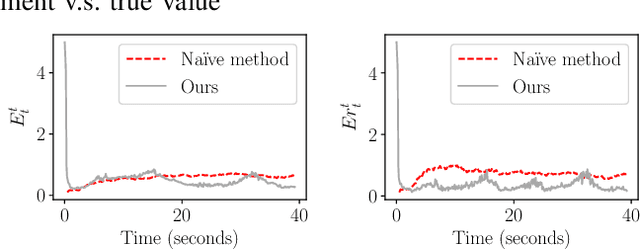
Depth estimation is an important capability for autonomous vehicles to understand and reconstruct 3D environments as well as avoid obstacles during the execution. Accurate depth sensors such as LiDARs are often heavy, expensive and can only provide sparse depth while lighter depth sensors such as stereo cameras are noiser in comparison. We propose an end-to-end learning algorithm that is capable of using sparse, noisy input depth for refinement and depth completion. Our model also produces the camera pose as a byproduct, making it a great solution for autonomous systems. We evaluate our approach on both indoor and outdoor datasets. Empirical results show that our method performs well on the KITTI~\cite{kitti_geiger2012we} dataset when compared to other competing methods, while having superior performance in dealing with sparse, noisy input depth on the TUM~\cite{sturm12iros} dataset.
MAVNet: an Effective Semantic Segmentation Micro-Network for MAV-based Tasks
Apr 03, 2019

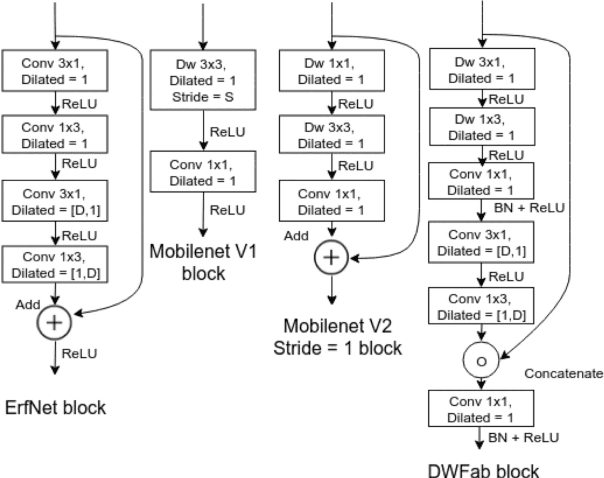

Real-time image semantic segmentation is an essential capability to enhance robot autonomy and improve human situational awareness. In this paper, we present MAVNet, a novel deep neural network approach for semantic segmentation suitable for small scale Micro Aerial Vehicles (MAVs). Our approach is compatible with the size, weight, and power(SWaP) constraints typical of small scale MAVs, which can only employ small processing units and GPUs. These units have typically limited computational capacity, which has to be concurrently shared with other real time performance tasks such as visual odometry and path planning. Our proposed solution MAVNet, is a fast and compact network inspired by ERFNet and features about 400 times fewer parameters in comparison. Experimental results on multiple datasets validate our proposed approach. Additionally, comparisons with other state of the art approaches show that our solution outperforms theirs in terms of speed and accuracy achieving up to 48 FPS on an NVIDIA 1080Ti and 9 FPS on the NVIDIA Jetson Xavier when processing high resolution imagery. Our algorithm and datasets are made publicly available.
DFuseNet: Deep Fusion of RGB and Sparse Depth Information for Image Guided Dense Depth Completion
Feb 02, 2019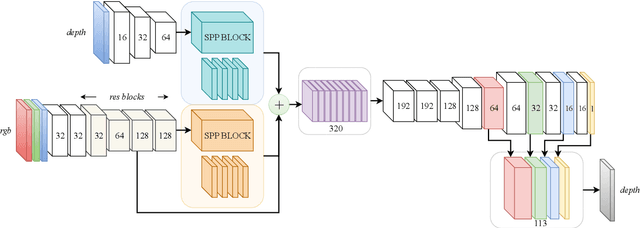


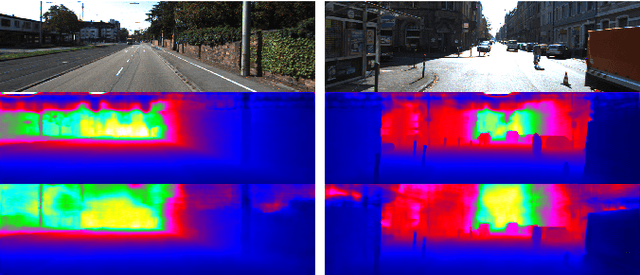
In this paper we propose a convolutional neural network that is designed to upsample a series of sparse range measurements based on the contextual cues gleaned from a high resolution intensity image. Our approach draws inspiration from related work on super-resolution and in-painting. We propose a novel architecture that seeks to pull contextual cues separately from the intensity image and the depth features and then fuse them later in the network. We argue that this approach effectively exploits the relationship between the two modalities and produces accurate results while respecting salient image structures. We present experimental results to demonstrate that our approach is comparable with state of the art methods and generalizes well across multiple datasets.
U-Net for MAV-based Penstock Inspection: an Investigation of Focal Loss in Multi-class Segmentation for Corrosion Identification
Sep 18, 2018
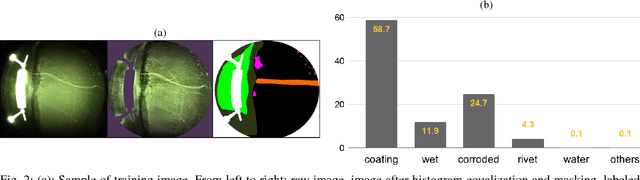
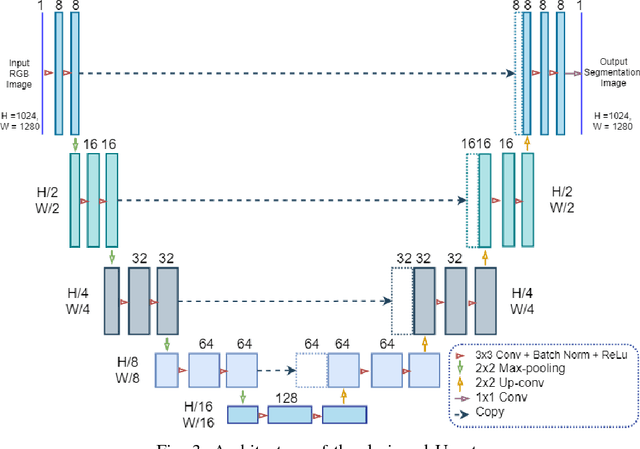
Periodical inspection and maintenance of critical infrastructure such as dams, penstocks, and locks are of significant importance to prevent catastrophic failures. Conventional manual inspection methods require inspectors to climb along a penstock to spot corrosion, rust and crack formation which is unsafe, labor-intensive, and requires intensive training. This work presents an alternative approach using a Micro Aerial Vehicle (MAV) that autonomously flies to collect imagery which is then fed into a pretrained deep-learning model to identify corrosion. Our simplified U-Net trained with less than 40 image samples can do inference at 12 fps on a single GPU. We analyze different loss functions to solve the class imbalance problem, followed by a discussion on choosing proper metrics and weights for object classes. Results obtained with the dataset collected from Center Hill Dam, TN show that focal loss function, combined with a proper set of class weights yield better segmentation results than the base loss, Softmax cross entropy. Our method can be used in combination with planning algorithm to offer a complete, safe and cost-efficient solution to autonomous infrastructure inspection.
Unsupervised Deep Homography: A Fast and Robust Homography Estimation Model
Feb 21, 2018
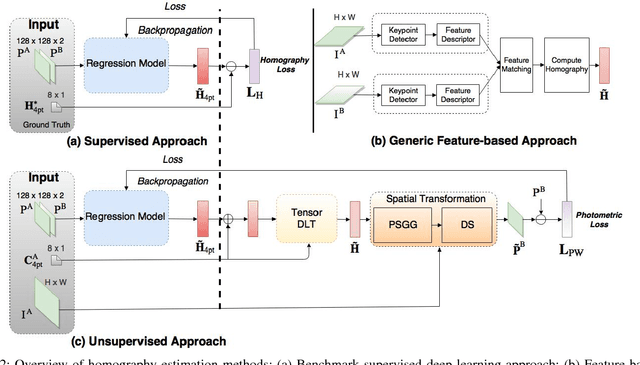
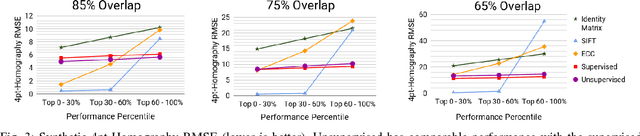
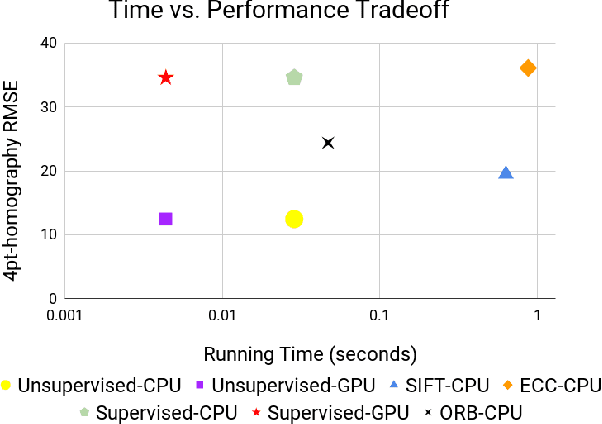
Homography estimation between multiple aerial images can provide relative pose estimation for collaborative autonomous exploration and monitoring. The usage on a robotic system requires a fast and robust homography estimation algorithm. In this study, we propose an unsupervised learning algorithm that trains a Deep Convolutional Neural Network to estimate planar homographies. We compare the proposed algorithm to traditional feature-based and direct methods, as well as a corresponding supervised learning algorithm. Our empirical results demonstrate that compared to traditional approaches, the unsupervised algorithm achieves faster inference speed, while maintaining comparable or better accuracy and robustness to illumination variation. In addition, on both a synthetic dataset and representative real-world aerial dataset, our unsupervised method has superior adaptability and performance compared to the supervised deep learning method.