 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODAM: Object Detection, Association, and Mapping using Posed RGB Video
Aug 23, 2021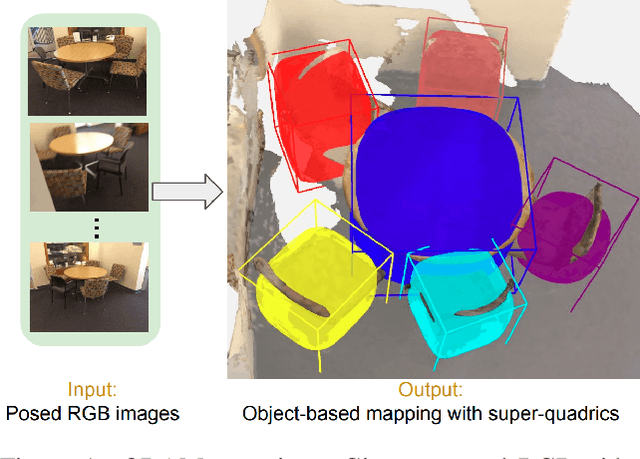

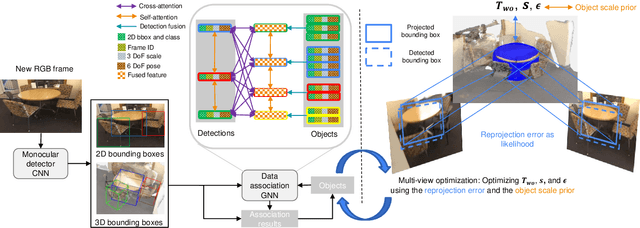
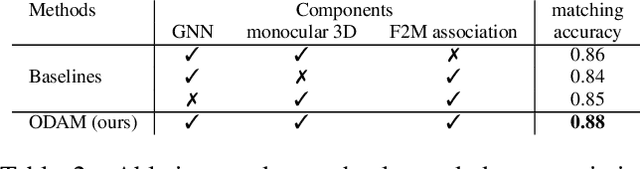
Localizing objects and estimating their extent in 3D is an important step towards high-level 3D scene understanding, which has many applications in Augmented Reality and Robotics. We present ODAM, a system for 3D Object Detection, Association, and Mapping using posed RGB videos. The proposed system relies on a deep learning front-end to detect 3D objects from a given RGB frame and associate them to a global object-based map using a graph neural network (GNN). Based on these frame-to-model associations, our back-end optimizes object bounding volumes, represented as super-quadrics, under multi-view geometry constraints and the object scale prior. We validate the proposed system on ScanNet where we show a significant improvement over existing RGB-only methods.
Pose Trainer: Correcting Exercise Posture using Pose Estimation
Jun 21, 2020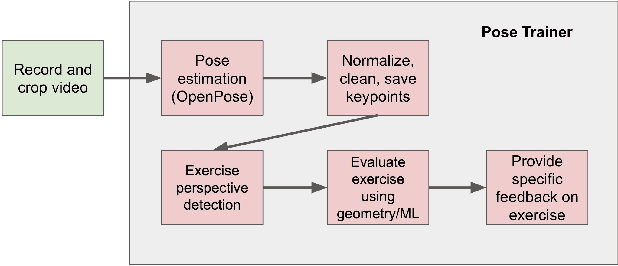
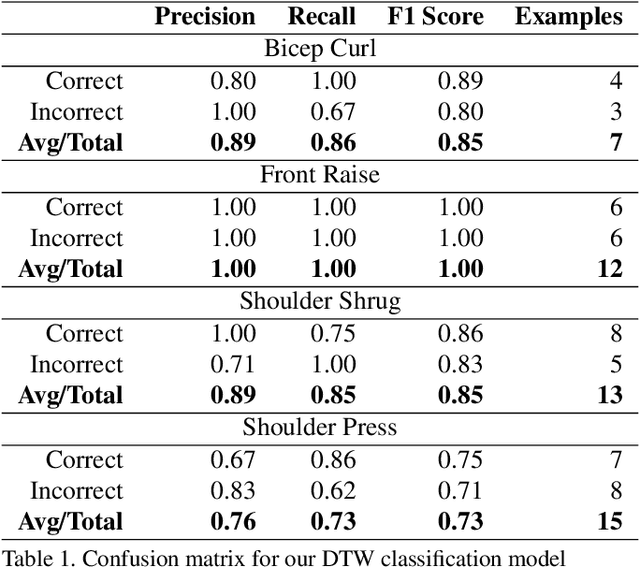
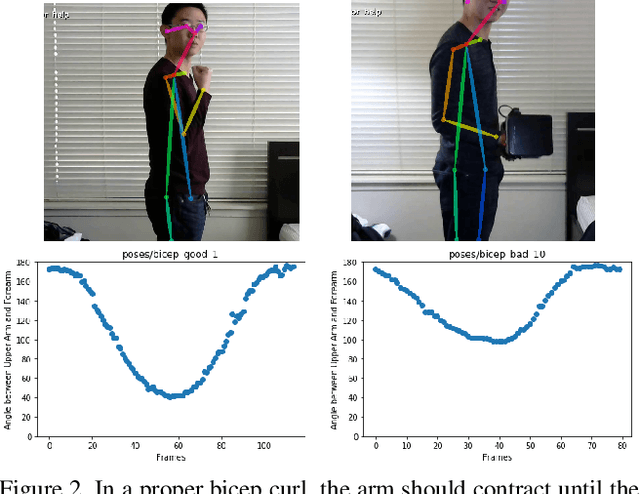
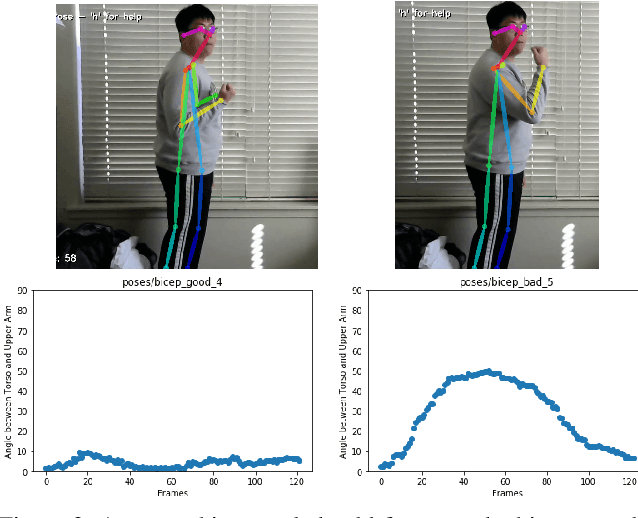
Fitness exercises are very beneficial to personal health and fitness; however, they can also be ineffective and potentially dangerous if performed incorrectly by the user. Exercise mistakes are made when the user does not use the proper form, or pose. In our work, we introduce Pose Trainer, an application that detects the user's exercise pose and provides personalized, detailed recommendations on how the user can improve their form. Pose Trainer uses the state of the art in pose estimation to detect a user's pose, then evaluates the vector geometry of the pose through an exercise to provide useful feedback. We record a dataset of over 100 exercise videos of correct and incorrect form, based on personal training guidelines, and build geometric-heuristic and machine learning algorithms for evaluation. Pose Trainer works on four common exercises and supports any Windows or Linux computer with a GPU.
Minority Reports Defense: Defending Against Adversarial Patches
Apr 28, 2020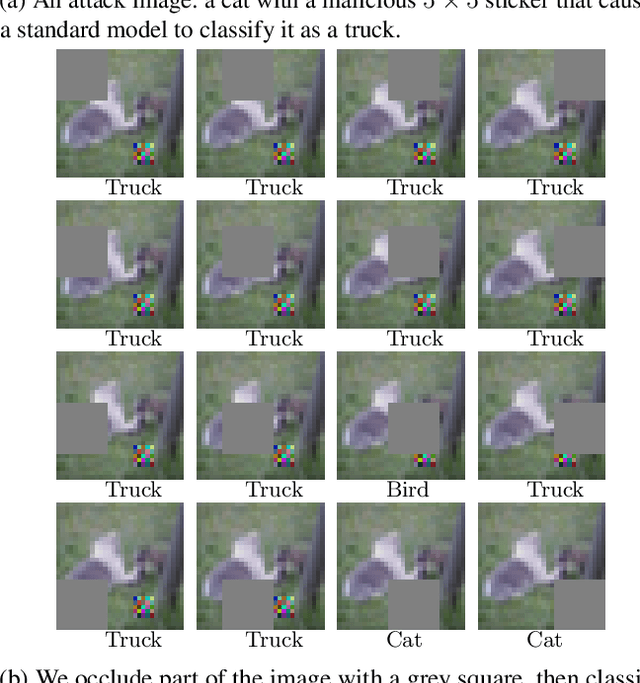
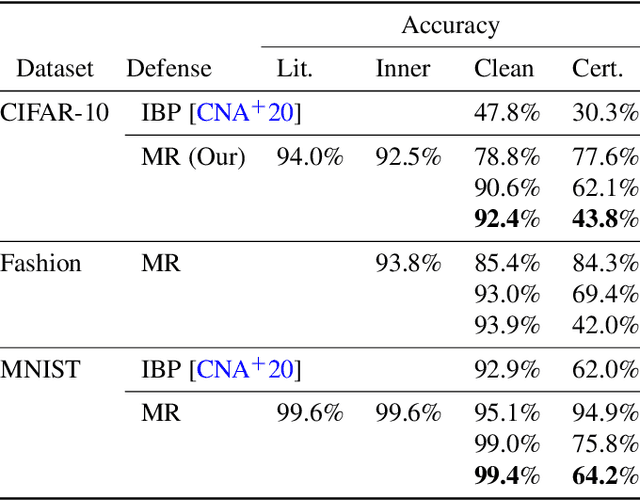
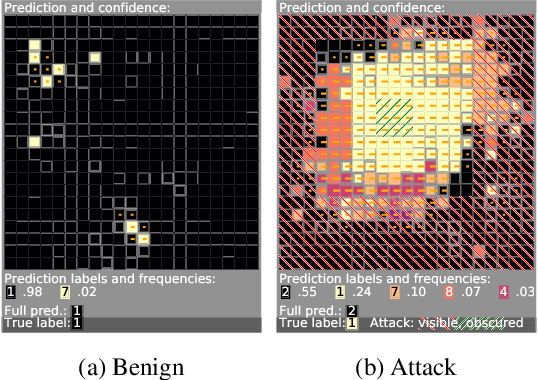
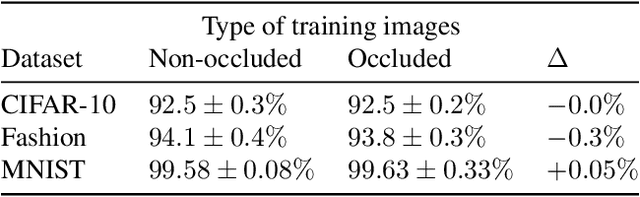
Deep learning image classification is vulnerable to adversarial attack, even if the attacker changes just a small patch of the image. We propose a defense against patch attacks based on partially occluding the image around each candidate patch location, so that a few occlusions each completely hide the patch. We demonstrate on CIFAR-10, Fashion MNIST, and MNIST that our defense provides certified security against patch attacks of a certain size.
Generating Semantic Adversarial Examples with Differentiable Rendering
Oct 02, 2019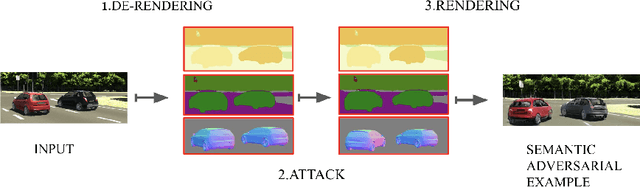



Machine learning (ML) algorithms, especially deep neural networks, have demonstrated success in several domains. However, several types of attacks have raised concerns about deploying ML in safety-critical domains, such as autonomous driving and security. An attacker perturbs a data point slightly in the concrete feature space (e.g., pixel space) and causes the ML algorithm to produce incorrect output (e.g. a perturbed stop sign is classified as a yield sign). These perturbed data points are called adversarial examples, and there are numerous algorithms in the literature for constructing adversarial examples and defending against them. In this paper we explore semantic adversarial examples (SAEs) where an attacker creates perturbations in the semantic space representing the environment that produces input for the ML model. For example, an attacker can change the background of the image to be cloudier to cause misclassification. We present an algorithm for constructing SAEs that uses recent advances in differential rendering and inverse graphics.
Stateful Detection of Black-Box Adversarial Attacks
Jul 12, 2019


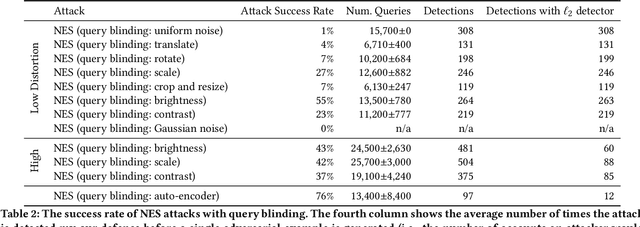
The problem of adversarial examples, evasion attacks on machine learning classifiers, has proven extremely difficult to solve. This is true even when, as is the case in many practical settings, the classifier is hosted as a remote service and so the adversary does not have direct access to the model parameters. This paper argues that in such settings, defenders have a much larger space of actions than have been previously explored. Specifically, we deviate from the implicit assumption made by prior work that a defense must be a stateless function that operates on individual examples, and explore the possibility for stateful defenses. To begin, we develop a defense designed to detect the process of adversarial example generation. By keeping a history of the past queries, a defender can try to identify when a sequence of queries appears to be for the purpose of generating an adversarial example. We then introduce query blinding, a new class of attacks designed to bypass defenses that rely on such a defense approach. We believe that expanding the study of adversarial examples from stateless classifiers to stateful systems is not only more realistic for many black-box settings, but also gives the defender a much-needed advantage in responding to the adversary.
DFineNet: Ego-Motion Estimation and Depth Refinement from Sparse, Noisy Depth Input with RGB Guidance
Apr 10, 2019

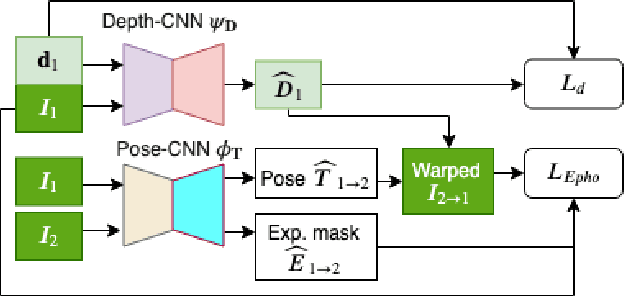

Depth estimation is an important capability for autonomous vehicles to understand and reconstruct 3D environments as well as avoid obstacles during the execution. Accurate depth sensors such as LiDARs are often heavy, expensive and can only provide sparse depth while lighter depth sensors such as stereo cameras are noiser in comparison. We propose an end-to-end learning algorithm that is capable of using sparse, noisy input depth for refinement and depth completion. Our model also produces the camera pose as a byproduct, making it a great solution for autonomous systems. We evaluate our approach on both indoor and outdoor datasets. Empirical results show that our method performs well on the KITTI~\cite{kitti_geiger2012we} dataset when compared to other competing methods, while having superior performance in dealing with sparse, noisy input depth on the TUM~\cite{sturm12iros} dataset.
Online Model Distillation for Efficient Video Inference
Dec 06, 2018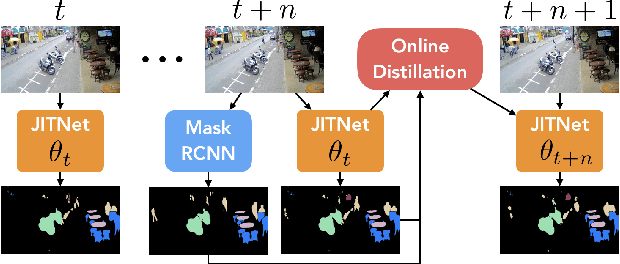
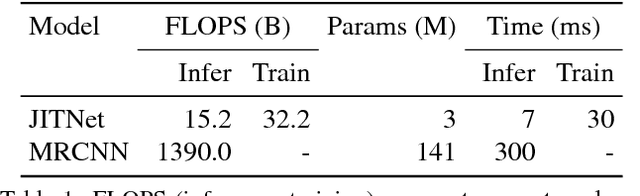
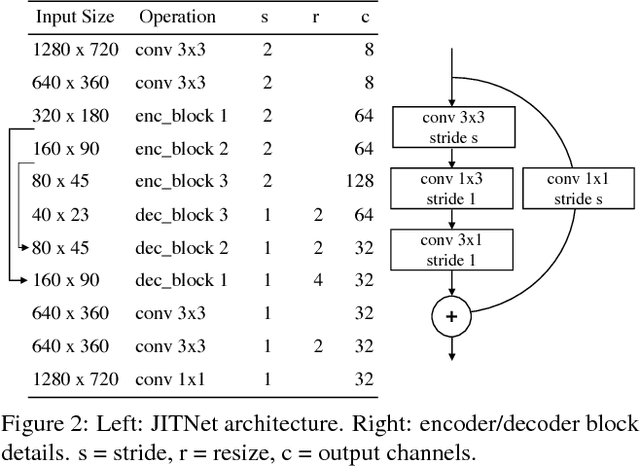
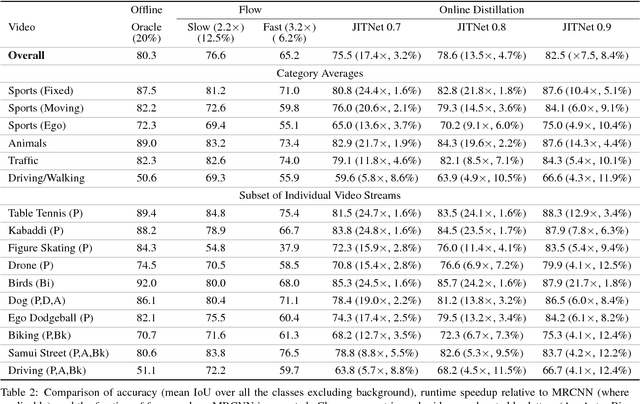
High-quality computer vision models typically address the problem of understanding the general distribution of real-world images. However, most cameras observe only a very small fraction of this distribution. This offers the possibility of achieving more efficient inference by specializing compact, low-cost models to the specific distribution of frames observed by a single camera. In this paper, we employ the technique of model distillation (supervising a low-cost student model using the output of a high-cost teacher) to specialize accurate, low-cost semantic segmentation models to a target video stream. Rather than learn a specialized student model on offline data from the video stream, we train the student in an online fashion on the live video, intermittently running the teacher to provide a target for learning. Online model distillation yields semantic segmentation models that closely approximate their Mask R-CNN teacher with 7 to 17x lower inference runtime cost (11 to 26x in FLOPs), even when the target video's distribution is non-stationary. Our method requires no offline pretraining on the target video stream, and achieves higher accuracy and lower cost than solutions based on flow or video object segmentation. We also provide a new video dataset for evaluating the efficiency of inference over long running video streams.
AI Blue Book: Vehicle Price Prediction using Visual Features
Oct 18, 2018

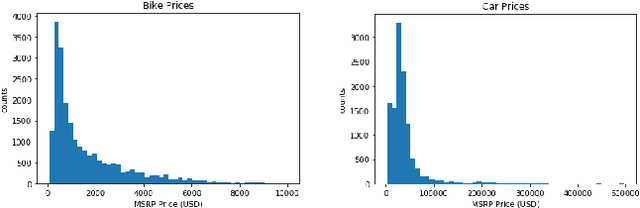

In this work, we build a series of machine learning models to predict the price of a product given its image, and visualize the features that result in higher or lower price predictions. We collect two novel datasets of product images and their MSRP prices for this purpose: a bicycle dataset and a car dataset. We set baselines for price regression using linear regression on histogram of oriented gradients (HOG) and convolutional neural network (CNN) features, and a baseline for price segment classification using a multiclass SVM. For our main models, we train several deep CNNs using both transfer learning and our own architectures, for both regression and classification. We achieve strong results on both datasets, with deep CNNs significantly outperforming other models in a variety of metrics. Finally, we use several recently-developed methods to visualize the image features that result in higher or lower prices.
Compare and Contrast: Learning Prominent Visual Differences
Apr 13, 2018



Relative attribute models can compare images in terms of all detected properties or attributes, exhaustively predicting which image is fancier, more natural, and so on without any regard to ordering. However, when humans compare images, certain differences will naturally stick out and come to mind first. These most noticeable differences, or prominent differences, are likely to be described first. In addition, many differences, although present, may not be mentioned at all. In this work, we introduce and model prominent differences, a rich new functionality for comparing images. We collect instance-level annotations of most noticeable differences, and build a model trained on relative attribute features that predicts prominent differences for unseen pairs. We test our model on the challenging UT-Zap50K shoes and LFW10 faces datasets, and outperform an array of baseline methods. We then demonstrate how our prominence model improves two vision tasks, image search and description generation, enabling more natural communication between people and vision systems.