 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSearch: Joint Training of Reasoning and Document Ranking via Reinforcement Learning for Agentic Search
Apr 21, 2026Agentic search -- the task of training agents that iteratively reason, issue queries, and synthesize retrieved information to answer complex questions -- has achieved remarkable progress through reinforcement learning (RL). However, existing approaches such as Search-R1, treat the retrieval system as a fixed tool, optimizing only the reasoning agent while the retrieval component remains unchanged. A preliminary experiment reveals that the gap between an oracle and a fixed retrieval system reaches up to +26.8% relative F1 improvement across seven QA benchmarks, suggesting that the retrieval system is a key bottleneck in scaling agentic search performance. Motivated by this finding, we propose CoSearch, a framework that jointly trains a multi-step reasoning agent and a generative document ranking model via Group Relative Policy Optimization (GRPO). To enable effective GRPO training for the ranker -- whose inputs vary across reasoning trajectories -- we introduce a semantic grouping strategy that clusters sub-queries by token-level similarity, forming valid optimization groups without additional rollouts. We further design a composite reward combining ranking quality signals with trajectory-level outcome feedback, providing the ranker with both immediate and long-term learning signals. Experiments on seven single-hop and multi-hop QA benchmarks demonstrate consistent improvements over strong baselines, with ablation studies validating each design choice. Our results show that joint training of the reasoning agent and retrieval system is both feasible and strongly performant, pointing to a key ingredient for future search agents.
Semantic IDs for Recommender Systems at Snapchat: Use Cases, Technical Challenges, and Design Choices
Apr 05, 2026Effective item identifiers (IDs) are an important component for recommender systems (RecSys) in practice, and are commonly adopted in many use cases such as retrieval and ranking. IDs can encode collaborative filtering signals within training data, such that RecSys models can extrapolate during the inference and personalize the prediction based on users' behavioral histories. Recently, Semantic IDs (SIDs) have become a trending paradigm for RecSys. In comparison to the conventional atomic ID, an SID is an ordered list of codes, derived from tokenizers such as residual quantization, applied to semantic representations commonly extracted from foundation models or collaborative signals. SIDs have drastically smaller cardinality than the atomic counterpart, and induce semantic clustering in the ID space. At Snapchat, we apply SIDs as auxiliary features for ranking models, and also explore SIDs as additional retrieval sources in different ML applications. In this paper, we discuss practical technical challenges we encountered while applying SIDs, experiments we have conducted, and design choices we have iterated to mitigate these challenges. Backed by promising offline results on both internal data and academic benchmarks as well as online A/B studies, SID variants have been launched in multiple production models with positive metrics impact.
FlexRec: Adapting LLM-based Recommenders for Flexible Needs via Reinforcement Learning
Mar 12, 2026Modern recommender systems must adapt to dynamic, need-specific objectives for diverse recommendation scenarios, yet most traditional recommenders are optimized for a single static target and struggle to reconfigure behavior on demand. Recent advances in reinforcement-learning-based post-training have unlocked strong instruction-following and reasoning capabilities in LLMs, suggesting a principled route for aligning them to complex recommendation goals. Motivated by this, we study closed-set autoregressive ranking, where an LLM generates a permutation over a fixed candidate set conditioned on user context and an explicit need instruction. However, applying RL to this setting faces two key obstacles: (i) sequence-level rewards yield coarse credit assignment that fails to provide fine-grained training signals, and (ii) interaction feedback is sparse and noisy, which together lead to inefficient and unstable updates. We propose FlexRec, a post-training RL framework that addresses both issues with (1) a causally grounded item-level reward based on counterfactual swaps within the remaining candidate pool, and (2) critic-guided, uncertainty-aware scaling that explicitly models reward uncertainty and down-weights low-confidence rewards to stabilize learning under sparse supervision. Across diverse recommendation scenarios and objectives, FlexRec achieves substantial gains: it improves NDCG@5 by up to \textbf{59\%} and Recall@5 by up to \textbf{109.4\%} in need-specific ranking, and further achieves up to \textbf{24.1\%} Recall@5 improvement under generalization settings, outperforming strong traditional recommenders and LLM-based baselines.
Plain Transformers are Surprisingly Powerful Link Predictors
Feb 02, 2026Link prediction is a core challenge in graph machine learning, demanding models that capture rich and complex topological dependencies. While Graph Neural Networks (GNNs) are the standard solution, state-of-the-art pipelines often rely on explicit structural heuristics or memory-intensive node embeddings -- approaches that struggle to generalize or scale to massive graphs. Emerging Graph Transformers (GTs) offer a potential alternative but often incur significant overhead due to complex structural encodings, hindering their applications to large-scale link prediction. We challenge these sophisticated paradigms with PENCIL, an encoder-only plain Transformer that replaces hand-crafted priors with attention over sampled local subgraphs, retaining the scalability and hardware efficiency of standard Transformers. Through experimental and theoretical analysis, we show that PENCIL extracts richer structural signals than GNNs, implicitly generalizing a broad class of heuristics and subgraph-based expressivity. Empirically, PENCIL outperforms heuristic-informed GNNs and is far more parameter-efficient than ID-embedding--based alternatives, while remaining competitive across diverse benchmarks -- even without node features. Our results challenge the prevailing reliance on complex engineering techniques, demonstrating that simple design choices are potentially sufficient to achieve the same capabilities.
Threshold Differential Attention for Sink-Free, Ultra-Sparse, and Non-Dispersive Language Modeling
Jan 17, 2026Softmax attention struggles with long contexts due to structural limitations: the strict sum-to-one constraint forces attention sinks on irrelevant tokens, and probability mass disperses as sequence lengths increase. We tackle these problems with Threshold Differential Attention (TDA), a sink-free attention mechanism that achieves ultra-sparsity and improved robustness at longer sequence lengths without the computational overhead of projection methods or the performance degradation caused by noise accumulation of standard rectified attention. TDA applies row-wise extreme-value thresholding with a length-dependent gate, retaining only exceedances. Inspired by the differential transformer, TDA also subtracts an inhibitory view to enhance expressivity. Theoretically, we prove that TDA controls the expected number of spurious survivors per row to $O(1)$ and that consensus spurious matches across independent views vanish as context grows. Empirically, TDA produces $>99\%$ exact zeros and eliminates attention sinks while maintaining competitive performance on standard and long-context benchmarks.
MemRec: Collaborative Memory-Augmented Agentic Recommender System
Jan 13, 2026The evolution of recommender systems has shifted preference storage from rating matrices and dense embeddings to semantic memory in the agentic era. Yet existing agents rely on isolated memory, overlooking crucial collaborative signals. Bridging this gap is hindered by the dual challenges of distilling vast graph contexts without overwhelming reasoning agents with cognitive load, and evolving the collaborative memory efficiently without incurring prohibitive computational costs. To address this, we propose MemRec, a framework that architecturally decouples reasoning from memory management to enable efficient collaborative augmentation. MemRec introduces a dedicated, cost-effective LM_Mem to manage a dynamic collaborative memory graph, serving synthesized, high-signal context to a downstream LLM_Rec. The framework operates via a practical pipeline featuring efficient retrieval and cost-effective asynchronous graph propagation that evolves memory in the background. Extensive experiments on four benchmarks demonstrate that MemRec achieves state-of-the-art performance. Furthermore, architectural analysis confirms its flexibility, establishing a new Pareto frontier that balances reasoning quality, cost, and privacy through support for diverse deployments, including local open-source models. Code:https://github.com/rutgerswiselab/memrec and Homepage: https://memrec.weixinchen.com
Exploiting ID-Text Complementarity via Ensembling for Sequential Recommendation
Dec 19, 2025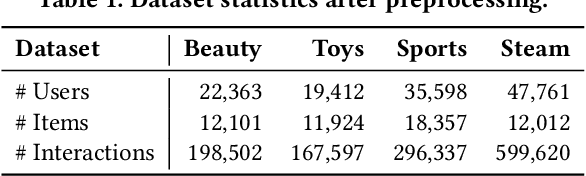
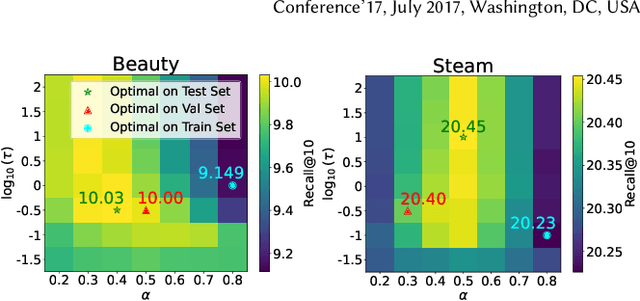
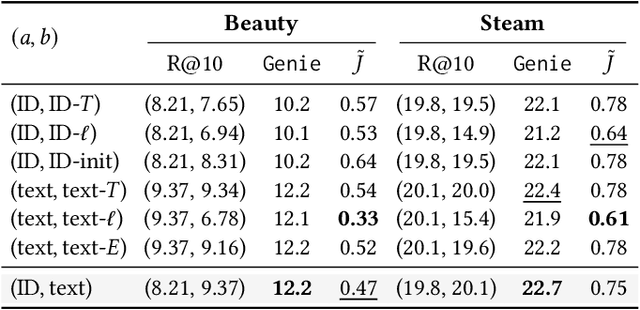
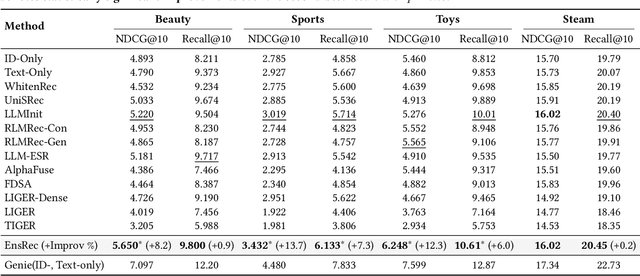
Modern Sequential Recommendation (SR) models commonly utilize modality features to represent items, motivated in large part by recent advancements in language and vision modeling. To do so, several works completely replace ID embeddings with modality embeddings, claiming that modality embeddings render ID embeddings unnecessary because they can match or even exceed ID embedding performance. On the other hand, many works jointly utilize ID and modality features, but posit that complex fusion strategies, such as multi-stage training and/or intricate alignment architectures, are necessary for this joint utilization. However, underlying both these lines of work is a lack of understanding of the complementarity of ID and modality features. In this work, we address this gap by studying the complementarity of ID- and text-based SR models. We show that these models do learn complementary signals, meaning that either should provide performance gain when used properly alongside the other. Motivated by this, we propose a new SR method that preserves ID-text complementarity through independent model training, then harnesses it through a simple ensembling strategy. Despite this method's simplicity, we show it outperforms several competitive SR baselines, implying that both ID and text features are necessary to achieve state-of-the-art SR performance but complex fusion architectures are not.
Hierarchical Token Prepending: Enhancing Information Flow in Decoder-based LLM Embeddings
Nov 18, 2025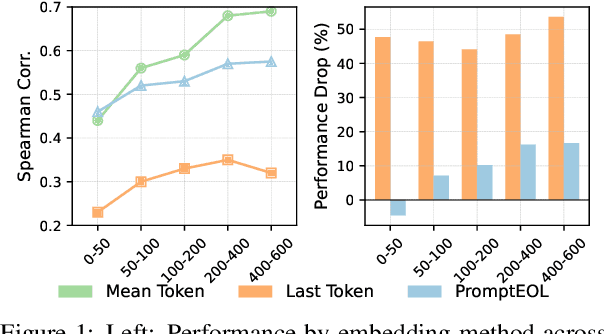
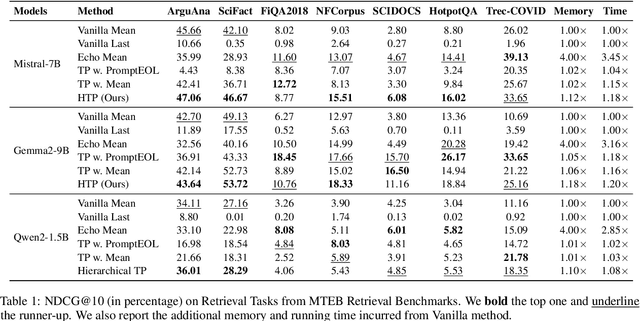
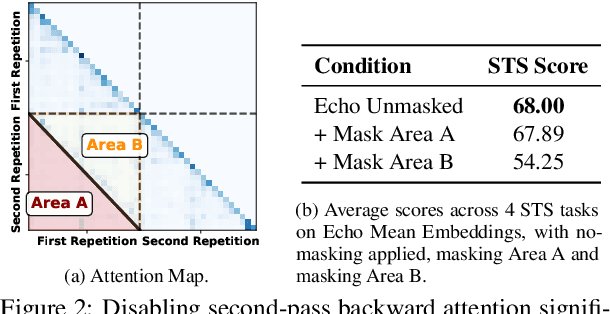
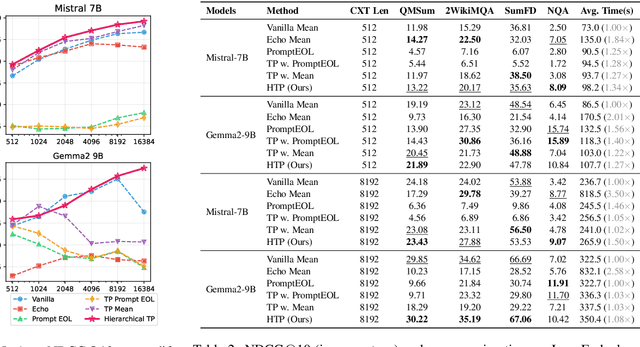
Large language models produce powerful text embeddings, but their causal attention mechanism restricts the flow of information from later to earlier tokens, degrading representation quality. While recent methods attempt to solve this by prepending a single summary token, they over-compress information, hence harming performance on long documents. We propose Hierarchical Token Prepending (HTP), a method that resolves two critical bottlenecks. To mitigate attention-level compression, HTP partitions the input into blocks and prepends block-level summary tokens to subsequent blocks, creating multiple pathways for backward information flow. To address readout-level over-squashing, we replace last-token pooling with mean-pooling, a choice supported by theoretical analysis. HTP achieves consistent performance gains across 11 retrieval datasets and 30 general embedding benchmarks, especially in long-context settings. As a simple, architecture-agnostic method, HTP enhances both zero-shot and finetuned models, offering a scalable route to superior long-document embeddings.
Generative Recommendation with Semantic IDs: A Practitioner's Handbook
Jul 29, 2025Generative recommendation (GR) has gained increasing attention for its promising performance compared to traditional models. A key factor contributing to the success of GR is the semantic ID (SID), which converts continuous semantic representations (e.g., from large language models) into discrete ID sequences. This enables GR models with SIDs to both incorporate semantic information and learn collaborative filtering signals, while retaining the benefits of discrete decoding. However, varied modeling techniques, hyper-parameters, and experimental setups in existing literature make direct comparisons between GR proposals challenging. Furthermore, the absence of an open-source, unified framework hinders systematic benchmarking and extension, slowing model iteration. To address this challenge, our work introduces and open-sources a framework for Generative Recommendation with semantic ID, namely GRID, specifically designed for modularity to facilitate easy component swapping and accelerate idea iteration. Using GRID, we systematically experiment with and ablate different components of GR models with SIDs on public benchmarks. Our comprehensive experiments with GRID reveal that many overlooked architectural components in GR models with SIDs substantially impact performance. This offers both novel insights and validates the utility of an open-source platform for robust benchmarking and GR research advancement. GRID is open-sourced at https://github.com/snap-research/GRID.
Learning Along the Arrow of Time: Hyperbolic Geometry for Backward-Compatible Representation Learning
Jun 06, 2025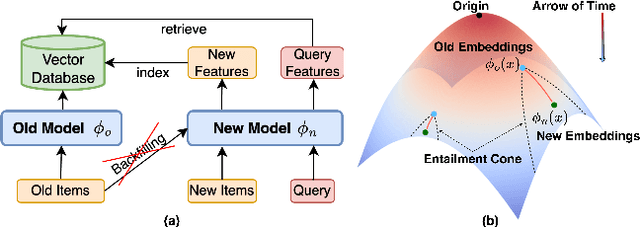
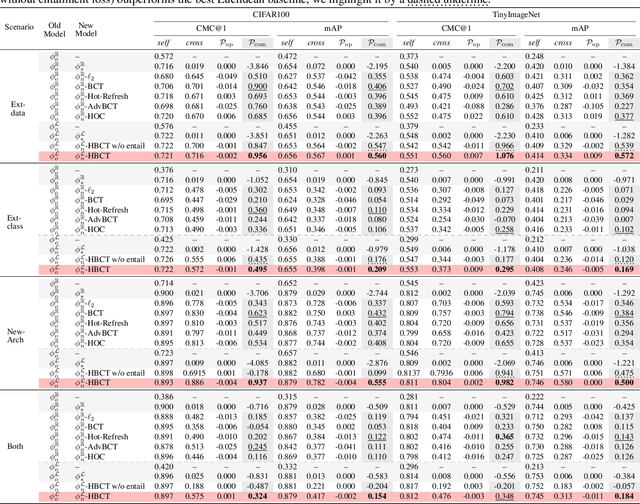
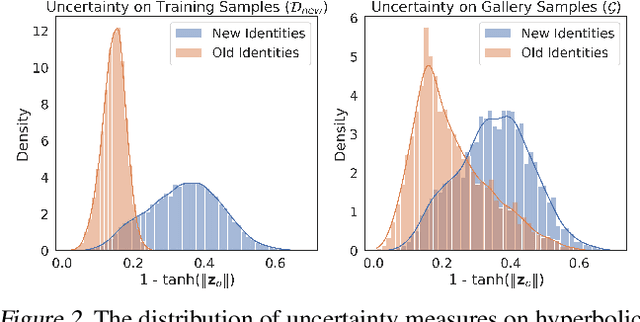
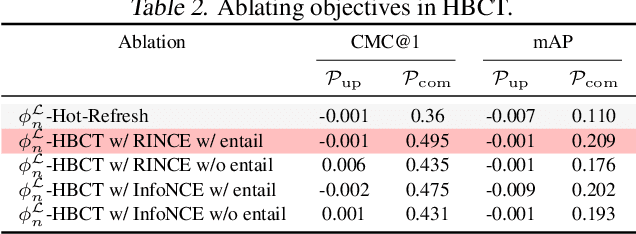
Backward compatible representation learning enables updated models to integrate seamlessly with existing ones, avoiding to reprocess stored data. Despite recent advances, existing compatibility approaches in Euclidean space neglect the uncertainty in the old embedding model and force the new model to reconstruct outdated representations regardless of their quality, thereby hindering the learning process of the new model. In this paper, we propose to switch perspectives to hyperbolic geometry, where we treat time as a natural axis for capturing a model's confidence and evolution. By lifting embeddings into hyperbolic space and constraining updated embeddings to lie within the entailment cone of the old ones, we maintain generational consistency across models while accounting for uncertainties in the representations. To further enhance compatibility, we introduce a robust contrastive alignment loss that dynamically adjusts alignment weights based on the uncertainty of the old embeddings. Experiments validate the superiority of the proposed method in achieving compatibility, paving the way for more resilient and adaptable machine learning systems.