 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemRec: Collaborative Memory-Augmented Agentic Recommender System
Jan 13, 2026The evolution of recommender systems has shifted preference storage from rating matrices and dense embeddings to semantic memory in the agentic era. Yet existing agents rely on isolated memory, overlooking crucial collaborative signals. Bridging this gap is hindered by the dual challenges of distilling vast graph contexts without overwhelming reasoning agents with cognitive load, and evolving the collaborative memory efficiently without incurring prohibitive computational costs. To address this, we propose MemRec, a framework that architecturally decouples reasoning from memory management to enable efficient collaborative augmentation. MemRec introduces a dedicated, cost-effective LM_Mem to manage a dynamic collaborative memory graph, serving synthesized, high-signal context to a downstream LLM_Rec. The framework operates via a practical pipeline featuring efficient retrieval and cost-effective asynchronous graph propagation that evolves memory in the background. Extensive experiments on four benchmarks demonstrate that MemRec achieves state-of-the-art performance. Furthermore, architectural analysis confirms its flexibility, establishing a new Pareto frontier that balances reasoning quality, cost, and privacy through support for diverse deployments, including local open-source models. Code:https://github.com/rutgerswiselab/memrec and Homepage: https://memrec.weixinchen.com
Exploiting ID-Text Complementarity via Ensembling for Sequential Recommendation
Dec 19, 2025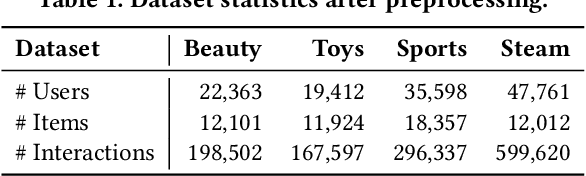
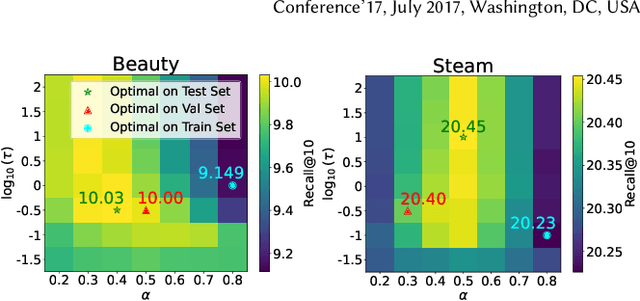
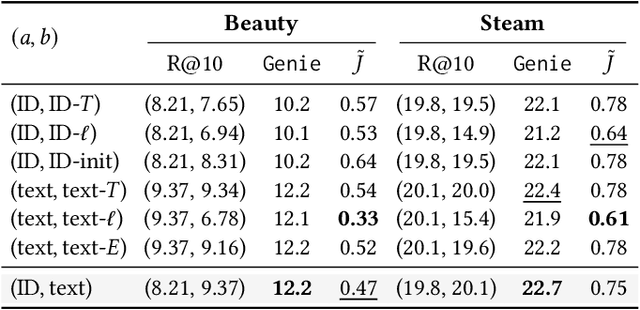
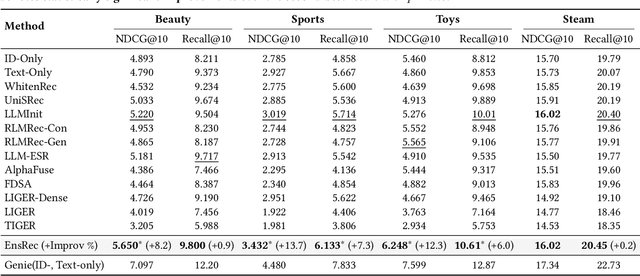
Modern Sequential Recommendation (SR) models commonly utilize modality features to represent items, motivated in large part by recent advancements in language and vision modeling. To do so, several works completely replace ID embeddings with modality embeddings, claiming that modality embeddings render ID embeddings unnecessary because they can match or even exceed ID embedding performance. On the other hand, many works jointly utilize ID and modality features, but posit that complex fusion strategies, such as multi-stage training and/or intricate alignment architectures, are necessary for this joint utilization. However, underlying both these lines of work is a lack of understanding of the complementarity of ID and modality features. In this work, we address this gap by studying the complementarity of ID- and text-based SR models. We show that these models do learn complementary signals, meaning that either should provide performance gain when used properly alongside the other. Motivated by this, we propose a new SR method that preserves ID-text complementarity through independent model training, then harnesses it through a simple ensembling strategy. Despite this method's simplicity, we show it outperforms several competitive SR baselines, implying that both ID and text features are necessary to achieve state-of-the-art SR performance but complex fusion architectures are not.
Generative Recommendation with Semantic IDs: A Practitioner's Handbook
Jul 29, 2025Generative recommendation (GR) has gained increasing attention for its promising performance compared to traditional models. A key factor contributing to the success of GR is the semantic ID (SID), which converts continuous semantic representations (e.g., from large language models) into discrete ID sequences. This enables GR models with SIDs to both incorporate semantic information and learn collaborative filtering signals, while retaining the benefits of discrete decoding. However, varied modeling techniques, hyper-parameters, and experimental setups in existing literature make direct comparisons between GR proposals challenging. Furthermore, the absence of an open-source, unified framework hinders systematic benchmarking and extension, slowing model iteration. To address this challenge, our work introduces and open-sources a framework for Generative Recommendation with semantic ID, namely GRID, specifically designed for modularity to facilitate easy component swapping and accelerate idea iteration. Using GRID, we systematically experiment with and ablate different components of GR models with SIDs on public benchmarks. Our comprehensive experiments with GRID reveal that many overlooked architectural components in GR models with SIDs substantially impact performance. This offers both novel insights and validates the utility of an open-source platform for robust benchmarking and GR research advancement. GRID is open-sourced at https://github.com/snap-research/GRID.
Revisiting Self-attention for Cross-domain Sequential Recommendation
May 27, 2025Sequential recommendation is a popular paradigm in modern recommender systems. In particular, one challenging problem in this space is cross-domain sequential recommendation (CDSR), which aims to predict future behaviors given user interactions across multiple domains. Existing CDSR frameworks are mostly built on the self-attention transformer and seek to improve by explicitly injecting additional domain-specific components (e.g. domain-aware module blocks). While these additional components help, we argue they overlook the core self-attention module already present in the transformer, a naturally powerful tool to learn correlations among behaviors. In this work, we aim to improve the CDSR performance for simple models from a novel perspective of enhancing the self-attention. Specifically, we introduce a Pareto-optimal self-attention and formulate the cross-domain learning as a multi-objective problem, where we optimize the recommendation task while dynamically minimizing the cross-domain attention scores. Our approach automates knowledge transfer in CDSR (dubbed as AutoCDSR) -- it not only mitigates negative transfer but also encourages complementary knowledge exchange among auxiliary domains. Based on the idea, we further introduce AutoCDSR+, a more performant variant with slight additional cost. Our proposal is easy to implement and works as a plug-and-play module that can be incorporated into existing transformer-based recommenders. Besides flexibility, it is practical to deploy because it brings little extra computational overheads without heavy hyper-parameter tuning. AutoCDSR on average improves Recall@10 for SASRec and Bert4Rec by 9.8% and 16.0% and NDCG@10 by 12.0% and 16.7%, respectively. Code is available at https://github.com/snap-research/AutoCDSR.
Learning Universal User Representations Leveraging Cross-domain User Intent at Snapchat
Apr 30, 2025The development of powerful user representations is a key factor in the success of recommender systems (RecSys). Online platforms employ a range of RecSys techniques to personalize user experience across diverse in-app surfaces. User representations are often learned individually through user's historical interactions within each surface and user representations across different surfaces can be shared post-hoc as auxiliary features or additional retrieval sources. While effective, such schemes cannot directly encode collaborative filtering signals across different surfaces, hindering its capacity to discover complex relationships between user behaviors and preferences across the whole platform. To bridge this gap at Snapchat, we seek to conduct universal user modeling (UUM) across different in-app surfaces, learning general-purpose user representations which encode behaviors across surfaces. Instead of replacing domain-specific representations, UUM representations capture cross-domain trends, enriching existing representations with complementary information. This work discusses our efforts in developing initial UUM versions, practical challenges, technical choices and modeling and research directions with promising offline performance. Following successful A/B testing, UUM representations have been launched in production, powering multiple use cases and demonstrating their value. UUM embedding has been incorporated into (i) Long-form Video embedding-based retrieval, leading to 2.78% increase in Long-form Video Open Rate, (ii) Long-form Video L2 ranking, with 19.2% increase in Long-form Video View Time sum, (iii) Lens L2 ranking, leading to 1.76% increase in Lens play time, and (iv) Notification L2 ranking, with 0.87% increase in Notification Open Rate.
GraphHash: Graph Clustering Enables Parameter Efficiency in Recommender Systems
Dec 23, 2024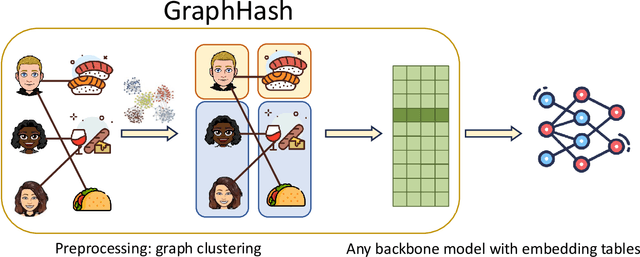
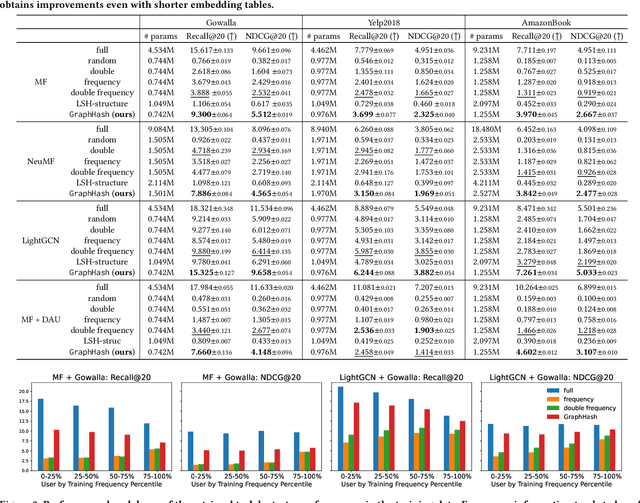
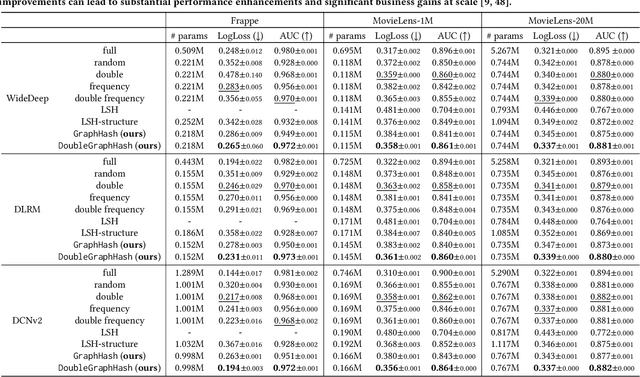
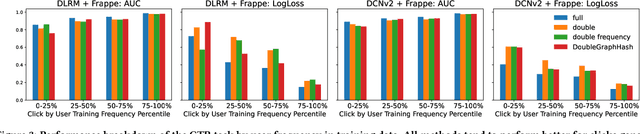
Deep recommender systems rely heavily on large embedding tables to handle high-cardinality categorical features such as user/item identifiers, and face significant memory constraints at scale. To tackle this challenge, hashing techniques are often employed to map multiple entities to the same embedding and thus reduce the size of the embedding tables. Concurrently, graph-based collaborative signals have emerged as powerful tools in recommender systems, yet their potential for optimizing embedding table reduction remains unexplored. This paper introduces GraphHash, the first graph-based approach that leverages modularity-based bipartite graph clustering on user-item interaction graphs to reduce embedding table sizes. We demonstrate that the modularity objective has a theoretical connection to message-passing, which provides a foundation for our method. By employing fast clustering algorithms, GraphHash serves as a computationally efficient proxy for message-passing during preprocessing and a plug-and-play graph-based alternative to traditional ID hashing. Extensive experiments show that GraphHash substantially outperforms diverse hashing baselines on both retrieval and click-through-rate prediction tasks. In particular, GraphHash achieves on average a 101.52% improvement in recall when reducing the embedding table size by more than 75%, highlighting the value of graph-based collaborative information for model reduction.