 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlain Transformers are Surprisingly Powerful Link Predictors
Feb 02, 2026Link prediction is a core challenge in graph machine learning, demanding models that capture rich and complex topological dependencies. While Graph Neural Networks (GNNs) are the standard solution, state-of-the-art pipelines often rely on explicit structural heuristics or memory-intensive node embeddings -- approaches that struggle to generalize or scale to massive graphs. Emerging Graph Transformers (GTs) offer a potential alternative but often incur significant overhead due to complex structural encodings, hindering their applications to large-scale link prediction. We challenge these sophisticated paradigms with PENCIL, an encoder-only plain Transformer that replaces hand-crafted priors with attention over sampled local subgraphs, retaining the scalability and hardware efficiency of standard Transformers. Through experimental and theoretical analysis, we show that PENCIL extracts richer structural signals than GNNs, implicitly generalizing a broad class of heuristics and subgraph-based expressivity. Empirically, PENCIL outperforms heuristic-informed GNNs and is far more parameter-efficient than ID-embedding--based alternatives, while remaining competitive across diverse benchmarks -- even without node features. Our results challenge the prevailing reliance on complex engineering techniques, demonstrating that simple design choices are potentially sufficient to achieve the same capabilities.
Exploiting ID-Text Complementarity via Ensembling for Sequential Recommendation
Dec 19, 2025
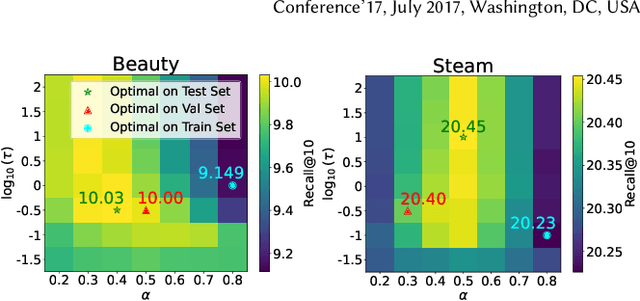
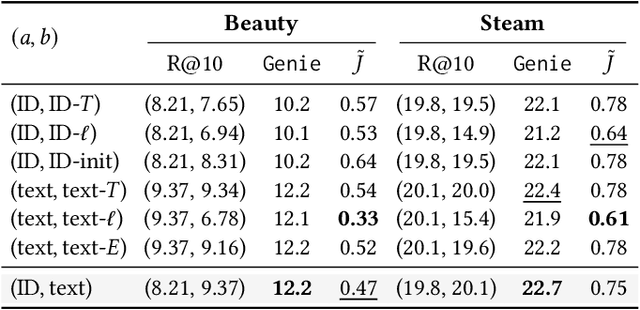
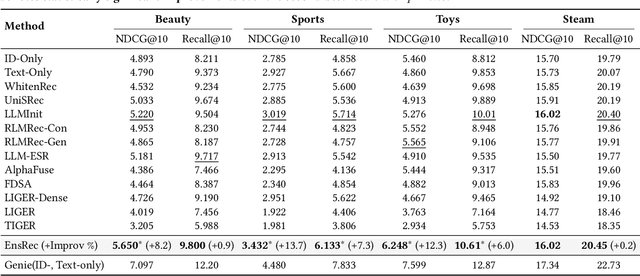
Modern Sequential Recommendation (SR) models commonly utilize modality features to represent items, motivated in large part by recent advancements in language and vision modeling. To do so, several works completely replace ID embeddings with modality embeddings, claiming that modality embeddings render ID embeddings unnecessary because they can match or even exceed ID embedding performance. On the other hand, many works jointly utilize ID and modality features, but posit that complex fusion strategies, such as multi-stage training and/or intricate alignment architectures, are necessary for this joint utilization. However, underlying both these lines of work is a lack of understanding of the complementarity of ID and modality features. In this work, we address this gap by studying the complementarity of ID- and text-based SR models. We show that these models do learn complementary signals, meaning that either should provide performance gain when used properly alongside the other. Motivated by this, we propose a new SR method that preserves ID-text complementarity through independent model training, then harnesses it through a simple ensembling strategy. Despite this method's simplicity, we show it outperforms several competitive SR baselines, implying that both ID and text features are necessary to achieve state-of-the-art SR performance but complex fusion architectures are not.
On the Role of Weight Decay in Collaborative Filtering: A Popularity Perspective
May 16, 2025Collaborative filtering (CF) enables large-scale recommendation systems by encoding information from historical user-item interactions into dense ID-embedding tables. However, as embedding tables grow, closed-form solutions become impractical, often necessitating the use of mini-batch gradient descent for training. Despite extensive work on designing loss functions to train CF models, we argue that one core component of these pipelines is heavily overlooked: weight decay. Attaining high-performing models typically requires careful tuning of weight decay, regardless of loss, yet its necessity is not well understood. In this work, we question why weight decay is crucial in CF pipelines and how it impacts training. Through theoretical and empirical analysis, we surprisingly uncover that weight decay's primary function is to encode popularity information into the magnitudes of the embedding vectors. Moreover, we find that tuning weight decay acts as a coarse, non-linear knob to influence preference towards popular or unpopular items. Based on these findings, we propose PRISM (Popularity-awaRe Initialization Strategy for embedding Magnitudes), a straightforward yet effective solution to simplify the training of high-performing CF models. PRISM pre-encodes the popularity information typically learned through weight decay, eliminating its necessity. Our experiments show that PRISM improves performance by up to 4.77% and reduces training times by 38.48%, compared to state-of-the-art training strategies. Additionally, we parameterize PRISM to modulate the initialization strength, offering a cost-effective and meaningful strategy to mitigate popularity bias.
GraphHash: Graph Clustering Enables Parameter Efficiency in Recommender Systems
Dec 23, 2024
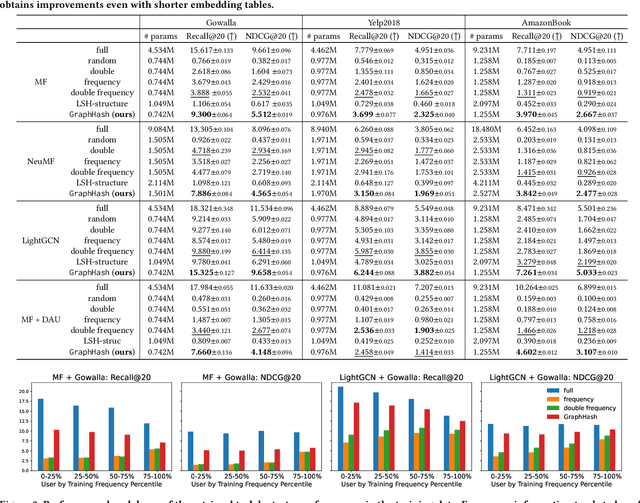
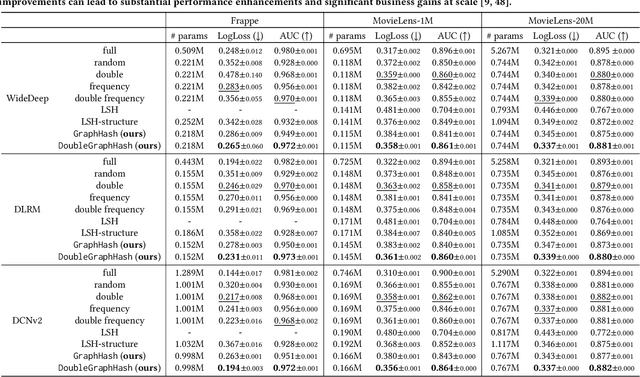
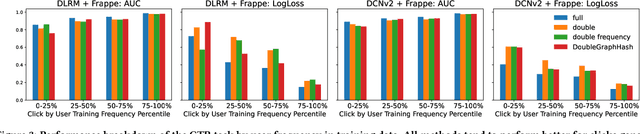
Deep recommender systems rely heavily on large embedding tables to handle high-cardinality categorical features such as user/item identifiers, and face significant memory constraints at scale. To tackle this challenge, hashing techniques are often employed to map multiple entities to the same embedding and thus reduce the size of the embedding tables. Concurrently, graph-based collaborative signals have emerged as powerful tools in recommender systems, yet their potential for optimizing embedding table reduction remains unexplored. This paper introduces GraphHash, the first graph-based approach that leverages modularity-based bipartite graph clustering on user-item interaction graphs to reduce embedding table sizes. We demonstrate that the modularity objective has a theoretical connection to message-passing, which provides a foundation for our method. By employing fast clustering algorithms, GraphHash serves as a computationally efficient proxy for message-passing during preprocessing and a plug-and-play graph-based alternative to traditional ID hashing. Extensive experiments show that GraphHash substantially outperforms diverse hashing baselines on both retrieval and click-through-rate prediction tasks. In particular, GraphHash achieves on average a 101.52% improvement in recall when reducing the embedding table size by more than 75%, highlighting the value of graph-based collaborative information for model reduction.
Unveiling the Impact of Local Homophily on GNN Fairness: In-Depth Analysis and New Benchmarks
Oct 05, 2024
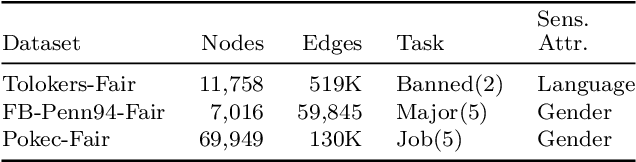
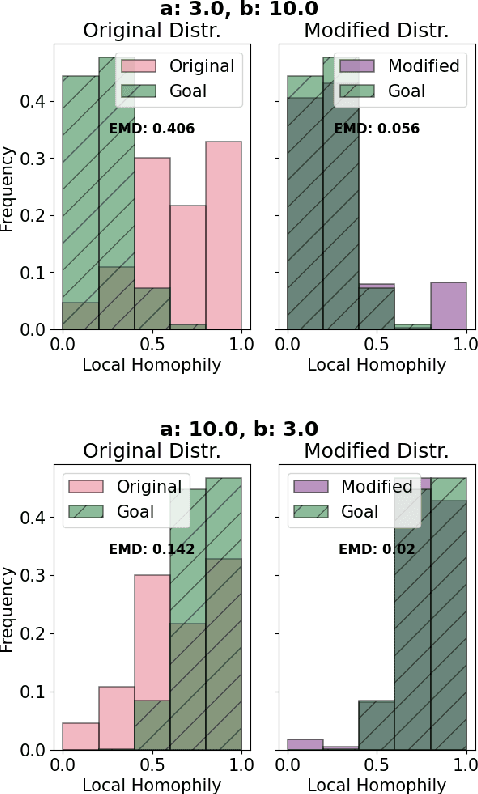
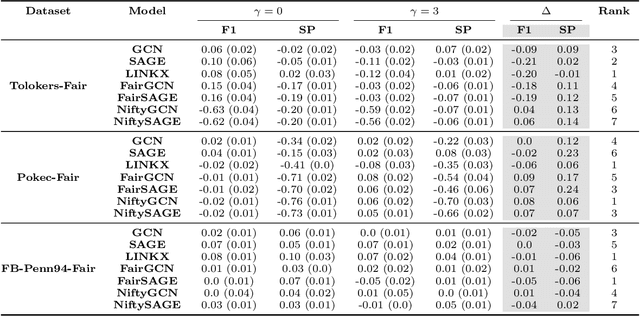
Graph Neural Networks (GNNs) often struggle to generalize when graphs exhibit both homophily (same-class connections) and heterophily (different-class connections). Specifically, GNNs tend to underperform for nodes with local homophily levels that differ significantly from the global homophily level. This issue poses a risk in user-centric applications where underrepresented homophily levels are present. Concurrently, fairness within GNNs has received substantial attention due to the potential amplification of biases via message passing. However, the connection between local homophily and fairness in GNNs remains underexplored. In this work, we move beyond global homophily and explore how local homophily levels can lead to unfair predictions. We begin by formalizing the challenge of fair predictions for underrepresented homophily levels as an out-of-distribution (OOD) problem. We then conduct a theoretical analysis that demonstrates how local homophily levels can alter predictions for differing sensitive attributes. We additionally introduce three new GNN fairness benchmarks, as well as a novel semi-synthetic graph generator, to empirically study the OOD problem. Across extensive analysis we find that two factors can promote unfairness: (a) OOD distance, and (b) heterophilous nodes situated in homophilous graphs. In cases where these two conditions are met, fairness drops by up to 24% on real world datasets, and 30% in semi-synthetic datasets. Together, our theoretical insights, empirical analysis, and algorithmic contributions unveil a previously overlooked source of unfairness rooted in the graph's homophily information.
Network Design through Graph Neural Networks: Identifying Challenges and Improving Performance
Oct 26, 2023
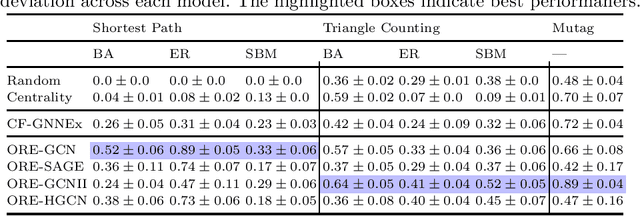


Graph Neural Network (GNN) research has produced strategies to modify a graph's edges using gradients from a trained GNN, with the goal of network design. However, the factors which govern gradient-based editing are understudied, obscuring why edges are chosen and if edits are grounded in an edge's importance. Thus, we begin by analyzing the gradient computation in previous works, elucidating the factors that influence edits and highlighting the potential over-reliance on structural properties. Specifically, we find that edges can achieve high gradients due to structural biases, rather than importance, leading to erroneous edits when the factors are unrelated to the design task. To improve editing, we propose ORE, an iterative editing method that (a) edits the highest scoring edges and (b) re-embeds the edited graph to refresh gradients, leading to less biased edge choices. We empirically study ORE through a set of proposed design tasks, each with an external validation method, demonstrating that ORE improves upon previous methods by up to 50%.
On Performance Discrepancies Across Local Homophily Levels in Graph Neural Networks
Jun 08, 2023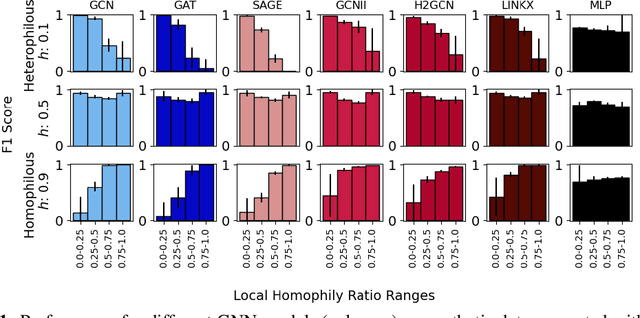

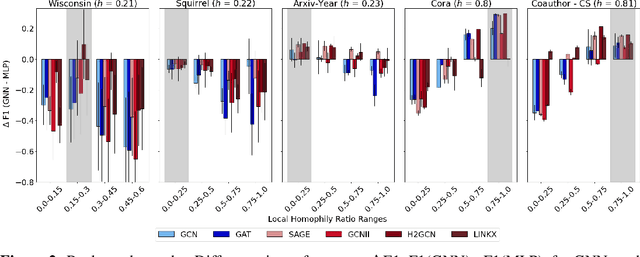

Research on GNNs has highlighted a relationship between high homophily (i.e., the tendency for nodes of a similar class to connect) and strong predictive performance in node classification. However, recent research has found the relationship to be more nuanced, demonstrating that even simple GNNs can learn in certain heterophilous settings. To bridge the gap between these findings, we revisit the assumptions made in previous works and identify that datasets are often treated as having a constant homophily level across nodes. To align closer to real-world datasets, we theoretically and empirically study the performance of GNNs when the local homophily level of a node deviates at test-time from the global homophily level of its graph. To aid our theoretical analysis, we introduce a new parameter to the preferential attachment model commonly used in homophily analysis to enable the control of local homophily levels in generated graphs, enabling a systematic empirical study on how local homophily can impact performance. We additionally perform a granular analysis on a number of real-world datasets with varying global homophily levels. Across our theoretical and empirical results, we find that (a)~ GNNs can fail to generalize to test nodes that deviate from the global homophily of a graph, (b)~ high local homophily does not necessarily confer high performance for a node, and (c)~ GNN models designed to handle heterophily are able to perform better across varying heterophily ranges irrespective of the dataset's global homophily. These findings point towards a GNN's over-reliance on the global homophily used for training and motivates the need to design GNNs that can better generalize across large local homophily ranges.
On Graph Neural Network Fairness in the Presence of Heterophilous Neighborhoods
Jul 10, 2022
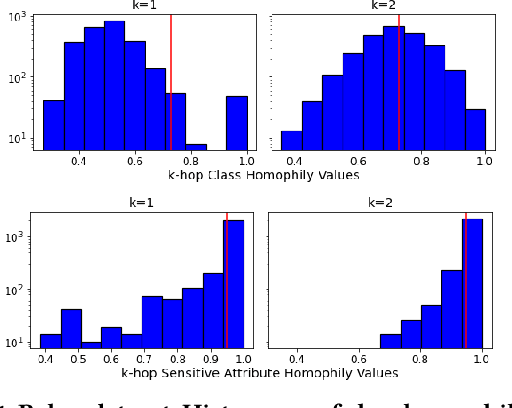


We study the task of node classification for graph neural networks (GNNs) and establish a connection between group fairness, as measured by statistical parity and equal opportunity, and local assortativity, i.e., the tendency of linked nodes to have similar attributes. Such assortativity is often induced by homophily, the tendency for nodes of similar properties to connect. Homophily can be common in social networks where systemic factors have forced individuals into communities which share a sensitive attribute. Through synthetic graphs, we study the interplay between locally occurring homophily and fair predictions, finding that not all node neighborhoods are equal in this respect -- neighborhoods dominated by one category of a sensitive attribute often struggle to obtain fair treatment, especially in the case of diverging local class and sensitive attribute homophily. After determining that a relationship between local homophily and fairness exists, we investigate if the issue of unfairness can be associated to the design of the applied GNN model. We show that by adopting heterophilous GNN designs capable of handling disassortative group labels, group fairness in locally heterophilous neighborhoods can be improved by up to 25% over homophilous designs in real and synthetic datasets.
Zeroth-Order SciML: Non-intrusive Integration of Scientific Software with Deep Learning
Jun 04, 2022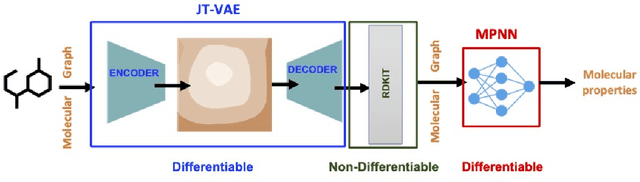

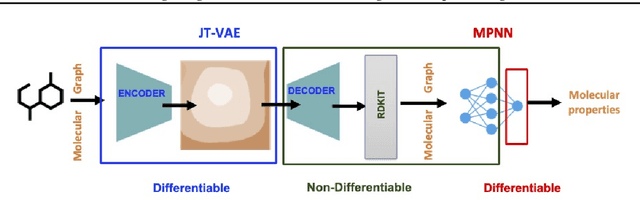
Using deep learning (DL) to accelerate and/or improve scientific workflows can yield discoveries that are otherwise impossible. Unfortunately, DL models have yielded limited success in complex scientific domains due to large data requirements. In this work, we propose to overcome this issue by integrating the abundance of scientific knowledge sources (SKS) with the DL training process. Existing knowledge integration approaches are limited to using differentiable knowledge source to be compatible with first-order DL training paradigm. In contrast, our proposed approach treats knowledge source as a black-box in turn allowing to integrate virtually any knowledge source. To enable an end-to-end training of SKS-coupled-DL, we propose to use zeroth-order optimization (ZOO) based gradient-free training schemes, which is non-intrusive, i.e., does not require making any changes to the SKS. We evaluate the performance of our ZOO training scheme on two real-world material science applications. We show that proposed scheme is able to effectively integrate scientific knowledge with DL training and is able to outperform purely data-driven model for data-limited scientific applications. We also discuss some limitations of the proposed method and mention potentially worthwhile future directions.
FairEdit: Preserving Fairness in Graph Neural Networks through Greedy Graph Editing
Jan 12, 2022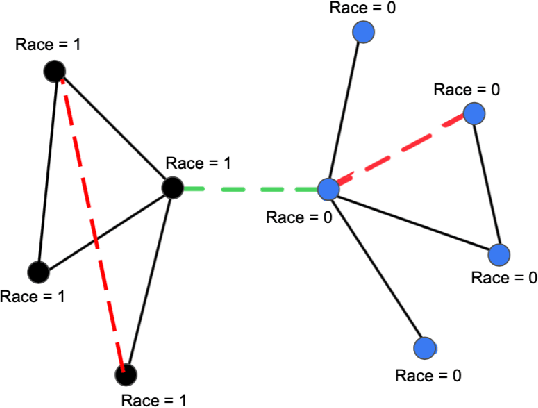
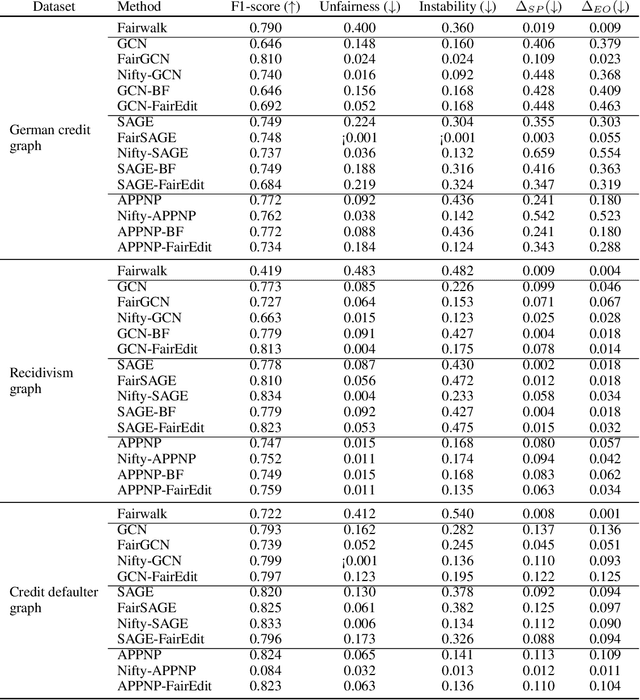
Graph Neural Networks (GNNs) have proven to excel in predictive modeling tasks where the underlying data is a graph. However, as GNNs are extensively used in human-centered applications, the issue of fairness has arisen. While edge deletion is a common method used to promote fairness in GNNs, it fails to consider when data is inherently missing fair connections. In this work we consider the unexplored method of edge addition, accompanied by deletion, to promote fairness. We propose two model-agnostic algorithms to perform edge editing: a brute force approach and a continuous approximation approach, FairEdit. FairEdit performs efficient edge editing by leveraging gradient information of a fairness loss to find edges that improve fairness. We find that FairEdit outperforms standard training for many data sets and GNN methods, while performing comparably to many state-of-the-art methods, demonstrating FairEdit's ability to improve fairness across many domains and models.