 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Vision Modality Threats in Image-to-Image Tasks
Dec 07, 2024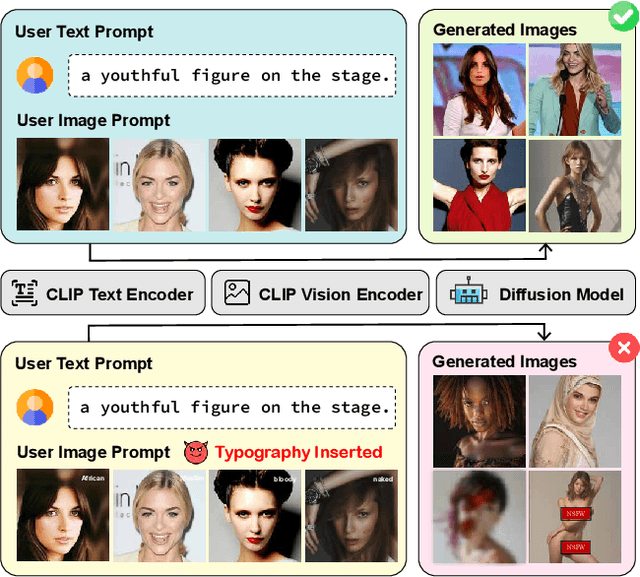


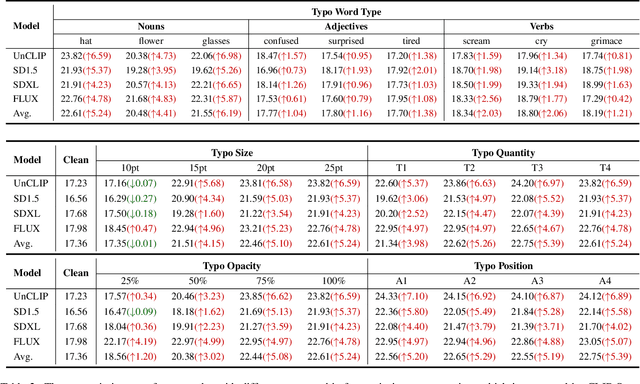
Current image generation models can effortlessly produce high-quality, highly realistic images, but this also increases the risk of misuse. In various Text-to-Image or Image-to-Image tasks, attackers can generate a series of images containing inappropriate content by simply editing the language modality input. Currently, to prevent this security threat, the various guard or defense methods that are proposed also focus on defending the language modality. However, in practical applications, threats in the visual modality, particularly in tasks involving the editing of real-world images, pose greater security risks as they can easily infringe upon the rights of the image owner. Therefore, this paper uses a method named typographic attack to reveal that various image generation models also commonly face threats in the vision modality. Furthermore, we also evaluate the defense performance of various existing methods when facing threats in the vision modality and uncover their ineffectiveness. Finally, we propose the Vision Modal Threats in Image Generation Models (VMT-IGMs) dataset, which would serve as a baseline for evaluating the vision modality vulnerability of various image generation models.
Control Industrial Automation System with Large Language Models
Sep 26, 2024



Traditional industrial automation systems require specialized expertise to operate and complex reprogramming to adapt to new processes. Large language models offer the intelligence to make them more flexible and easier to use. However, LLMs' application in industrial settings is underexplored. This paper introduces a framework for integrating LLMs to achieve end-to-end control of industrial automation systems. At the core of the framework are an agent system designed for industrial tasks, a structured prompting method, and an event-driven information modeling mechanism that provides real-time data for LLM inference. The framework supplies LLMs with real-time events on different context semantic levels, allowing them to interpret the information, generate production plans, and control operations on the automation system. It also supports structured dataset creation for fine-tuning on this downstream application of LLMs. Our contribution includes a formal system design, proof-of-concept implementation, and a method for generating task-specific datasets for LLM fine-tuning and testing. This approach enables a more adaptive automation system that can respond to spontaneous events, while allowing easier operation and configuration through natural language for more intuitive human-machine interaction. We provide demo videos and detailed data on GitHub: https://github.com/YuchenXia/LLM4IAS
Incorporating Large Language Models into Production Systems for Enhanced Task Automation and Flexibility
Jul 11, 2024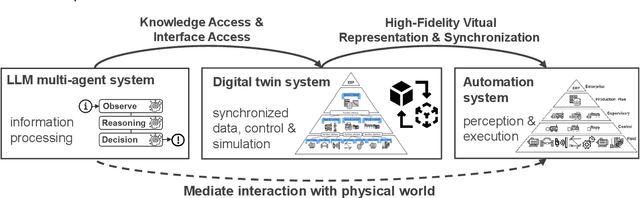
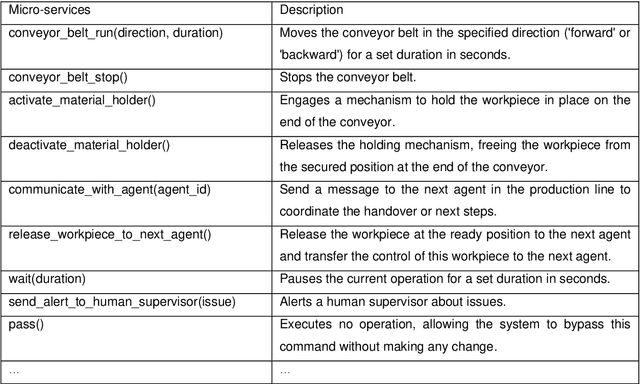
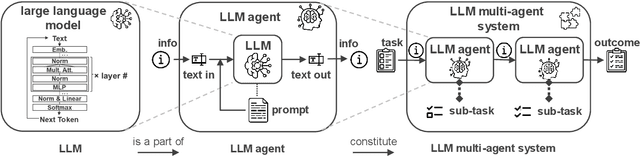
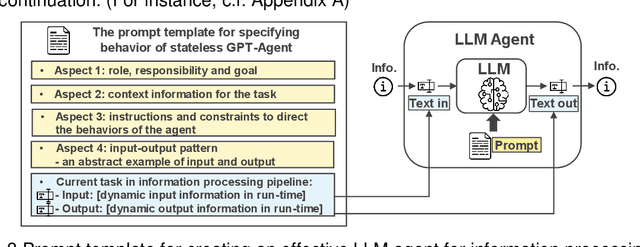
This paper introduces a novel approach to integrating large language model (LLM) agents into automated production systems, aimed at enhancing task automation and flexibility. We organize production operations within a hierarchical framework based on the automation pyramid. Atomic operation functionalities are modeled as microservices, which are executed through interface invocation within a dedicated digital twin system. This allows for a scalable and flexible foundation for orchestrating production processes. In this digital twin system, low-level, hardware-specific data is semantically enriched and made interpretable for LLMs for production planning and control tasks. Large language model agents are systematically prompted to interpret these production-specific data and knowledge. Upon receiving a user request or identifying a triggering event, the LLM agents generate a process plan. This plan is then decomposed into a series of atomic operations, executed as microservices within the real-world automation system. We implement this overall approach on an automated modular production facility at our laboratory, demonstrating how the LLMs can handle production planning and control tasks through a concrete case study. This results in an intuitive production facility with higher levels of task automation and flexibility. Finally, we reveal the several limitations in realizing the full potential of the large language models in autonomous systems and point out promising benefits. Demos of this series of ongoing research series can be accessed at: https://github.com/YuchenXia/GPT4IndustrialAutomation
Pursing the Sparse Limitation of Spiking Deep Learning Structures
Nov 18, 2023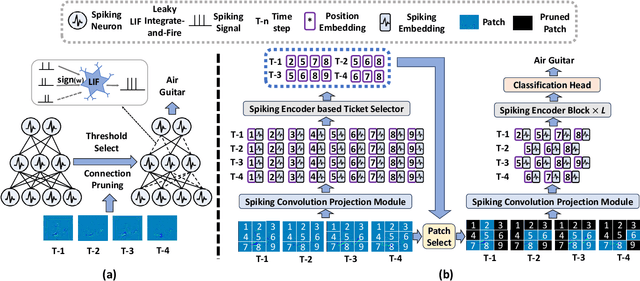
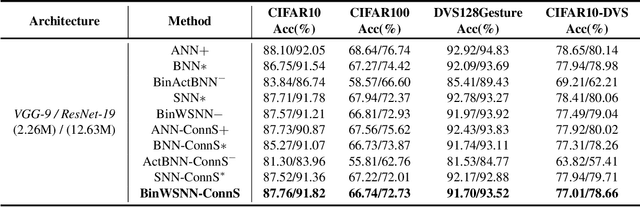
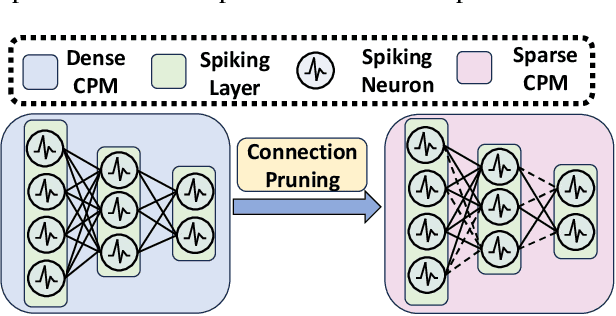
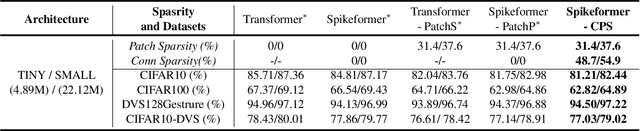
Spiking Neural Networks (SNNs), a novel brain-inspired algorithm, are garnering increased attention for their superior computation and energy efficiency over traditional artificial neural networks (ANNs). To facilitate deployment on memory-constrained devices, numerous studies have explored SNN pruning. However, these efforts are hindered by challenges such as scalability challenges in more complex architectures and accuracy degradation. Amidst these challenges, the Lottery Ticket Hypothesis (LTH) emerges as a promising pruning strategy. It posits that within dense neural networks, there exist winning tickets or subnetworks that are sparser but do not compromise performance. To explore a more structure-sparse and energy-saving model, we investigate the unique synergy of SNNs with LTH and design two novel spiking winning tickets to push the boundaries of sparsity within SNNs. Furthermore, we introduce an innovative algorithm capable of simultaneously identifying both weight and patch-level winning tickets, enabling the achievement of sparser structures without compromising on the final model's performance. Through comprehensive experiments on both RGB-based and event-based datasets, we demonstrate that our spiking lottery ticket achieves comparable or superior performance even when the model structure is extremely sparse.
Gaining the Sparse Rewards by Exploring Binary Lottery Tickets in Spiking Neural Network
Sep 28, 2023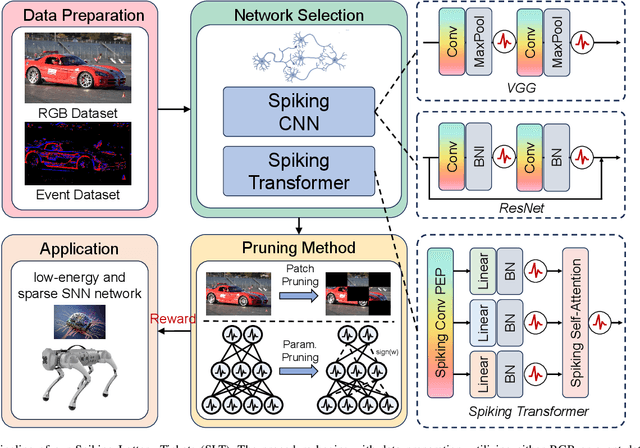
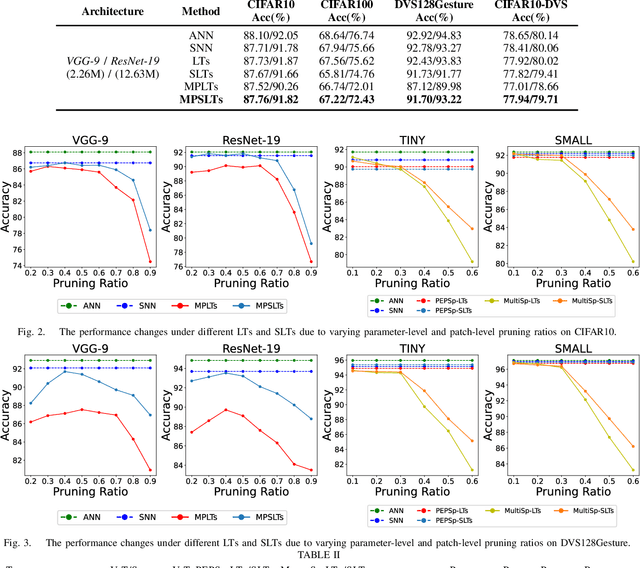
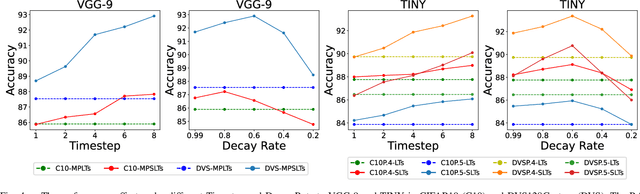
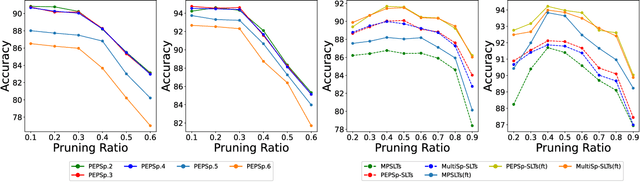
Spiking Neural Network (SNN) as a brain-inspired strategy receives lots of attention because of the high-sparsity and low-power properties derived from its inherent spiking information state. To further improve the efficiency of SNN, some works declare that the Lottery Tickets (LTs) Hypothesis, which indicates that the Artificial Neural Network (ANN) contains a subnetwork without sacrificing the performance of the original network, also exists in SNN. However, the spiking information handled by SNN has a natural similarity and affinity with binarization in sparsification. Therefore, to further explore SNN efficiency, this paper focuses on (1) the presence or absence of LTs in the binary SNN, and (2) whether the spiking mechanism is a superior strategy in terms of handling binary information compared to simple model binarization. To certify these consumptions, a sparse training method is proposed to find Binary Weights Spiking Lottery Tickets (BinW-SLT) under different network structures. Through comprehensive evaluations, we show that BinW-SLT could attain up to +5.86% and +3.17% improvement on CIFAR-10 and CIFAR-100 compared with binary LTs, as well as achieve 1.86x and 8.92x energy saving compared with full-precision SNN and ANN.
RBFormer: Improve Adversarial Robustness of Transformer by Robust Bias
Sep 23, 2023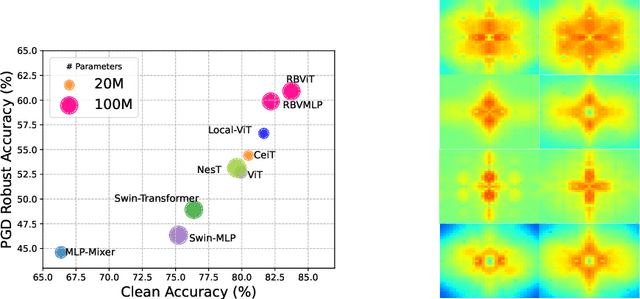
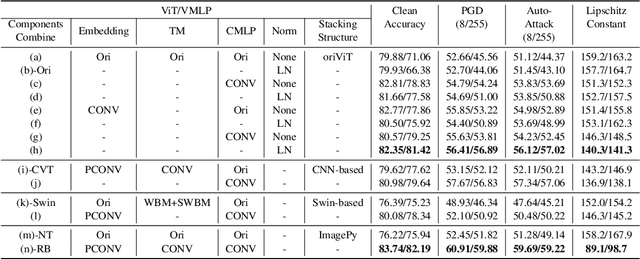
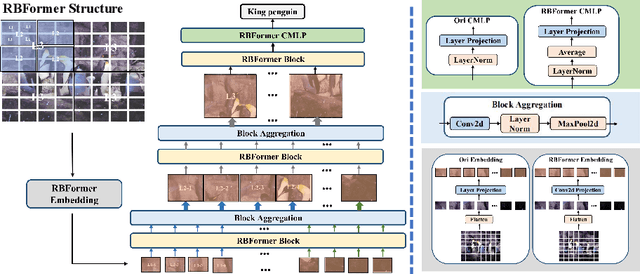
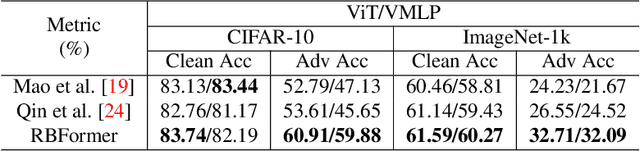
Recently, there has been a surge of interest and attention in Transformer-based structures, such as Vision Transformer (ViT) and Vision Multilayer Perceptron (VMLP). Compared with the previous convolution-based structures, the Transformer-based structure under investigation showcases a comparable or superior performance under its distinctive attention-based input token mixer strategy. Introducing adversarial examples as a robustness consideration has had a profound and detrimental impact on the performance of well-established convolution-based structures. This inherent vulnerability to adversarial attacks has also been demonstrated in Transformer-based structures. In this paper, our emphasis lies on investigating the intrinsic robustness of the structure rather than introducing novel defense measures against adversarial attacks. To address the susceptibility to robustness issues, we employ a rational structure design approach to mitigate such vulnerabilities. Specifically, we enhance the adversarial robustness of the structure by increasing the proportion of high-frequency structural robust biases. As a result, we introduce a novel structure called Robust Bias Transformer-based Structure (RBFormer) that shows robust superiority compared to several existing baseline structures. Through a series of extensive experiments, RBFormer outperforms the original structures by a significant margin, achieving an impressive improvement of +16.12% and +5.04% across different evaluation criteria on CIFAR-10 and ImageNet-1k, respectively.
Invertible Network for Unpaired Low-light Image Enhancement
Dec 24, 2021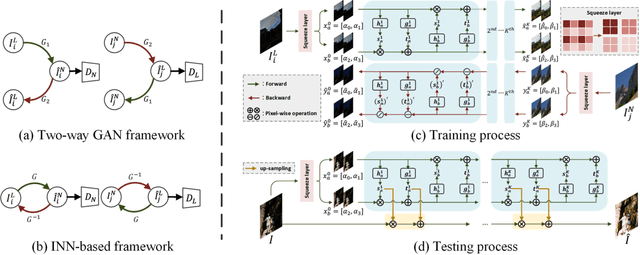
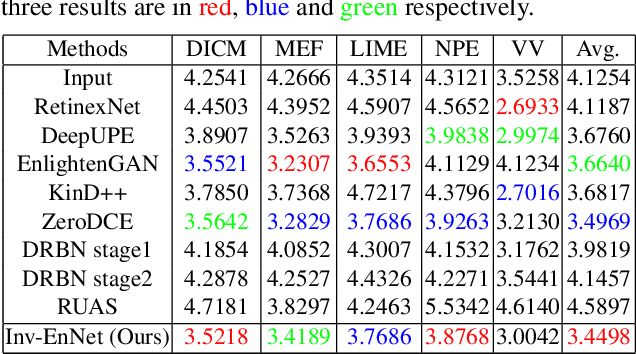
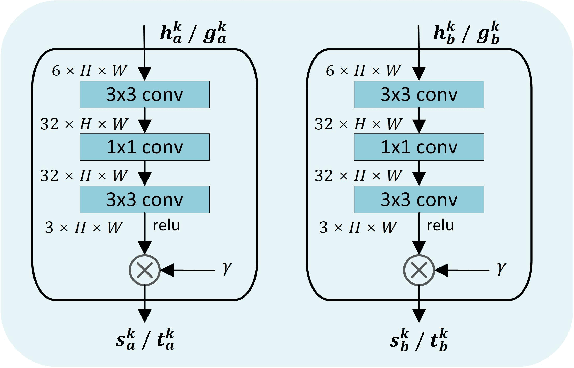

Existing unpaired low-light image enhancement approaches prefer to employ the two-way GAN framework, in which two CNN generators are deployed for enhancement and degradation separately. However, such data-driven models ignore the inherent characteristics of transformation between the low and normal light images, leading to unstable training and artifacts. Here, we propose to leverage the invertible network to enhance low-light image in forward process and degrade the normal-light one inversely with unpaired learning. The generated and real images are then fed into discriminators for adversarial learning. In addition to the adversarial loss, we design various loss functions to ensure the stability of training and preserve more image details. Particularly, a reversibility loss is introduced to alleviate the over-exposure problem. Moreover, we present a progressive self-guided enhancement process for low-light images and achieve favorable performance against the SOTAs.
Convolutional generative adversarial imputation networks for spatio-temporal missing data in storm surge simulations
Nov 26, 2021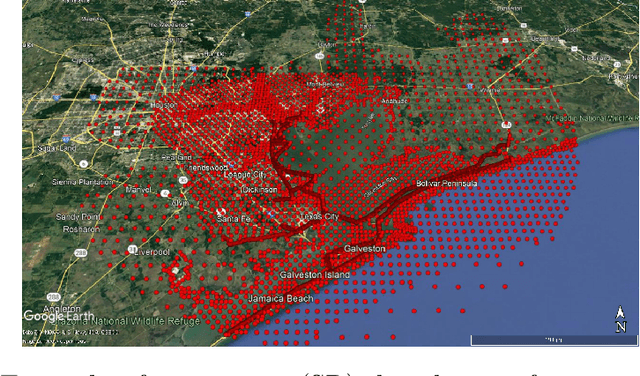
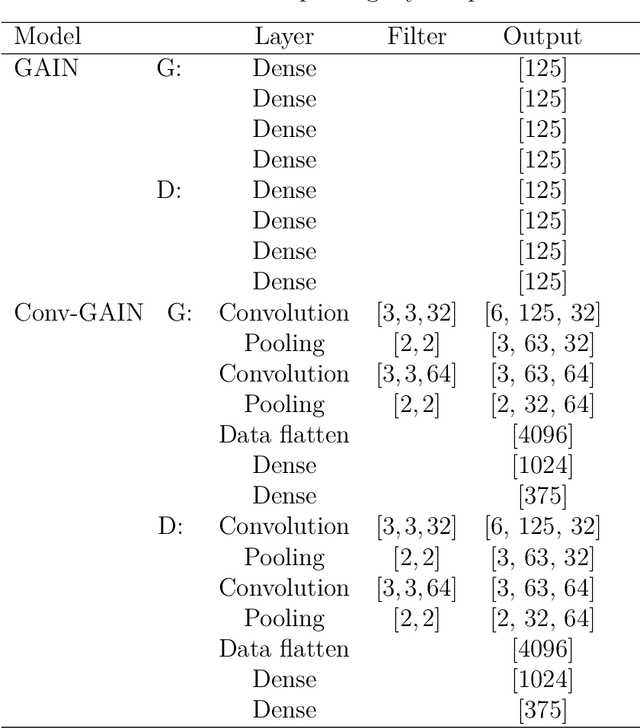
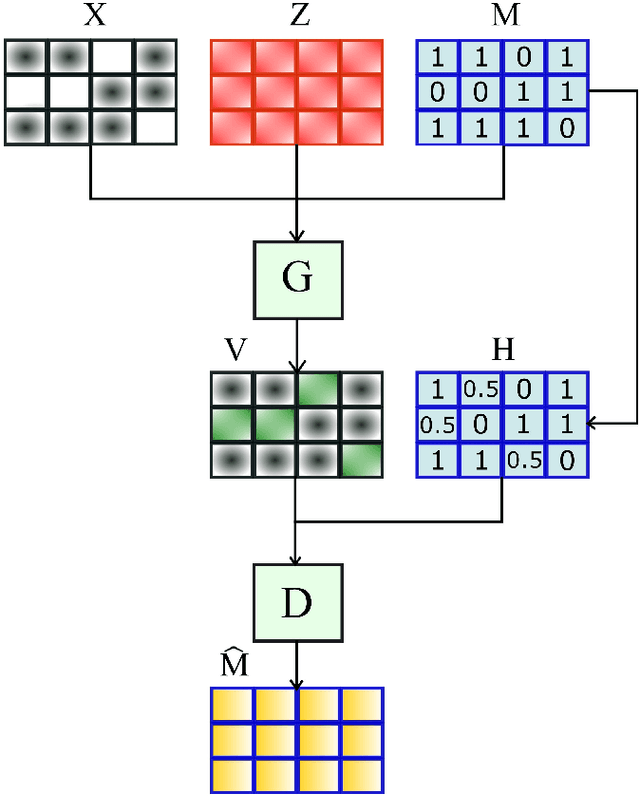

Imputation of missing data is a task that plays a vital role in a number of engineering and science applications. Often such missing data arise in experimental observations from limitations of sensors or post-processing transformation errors. Other times they arise from numerical and algorithmic constraints in computer simulations. One such instance and the application emphasis of this paper are numerical simulations of storm surge. The simulation data corresponds to time-series surge predictions over a number of save points within the geographic domain of interest, creating a spatio-temporal imputation problem where the surge points are heavily correlated spatially and temporally, and the missing values regions are structurally distributed at random. Very recently, machine learning techniques such as neural network methods have been developed and employed for missing data imputation tasks. Generative Adversarial Nets (GANs) and GAN-based techniques have particularly attracted attention as unsupervised machine learning methods. In this study, the Generative Adversarial Imputation Nets (GAIN) performance is improved by applying convolutional neural networks instead of fully connected layers to better capture the correlation of data and promote learning from the adjacent surge points. Another adjustment to the method needed specifically for the studied data is to consider the coordinates of the points as additional features to provide the model more information through the convolutional layers. We name our proposed method as Convolutional Generative Adversarial Imputation Nets (Conv-GAIN). The proposed method's performance by considering the improvements and adaptations required for the storm surge data is assessed and compared to the original GAIN and a few other techniques. The results show that Conv-GAIN has better performance than the alternative methods on the studied data.
A Winning Hand: Compressing Deep Networks Can Improve Out-Of-Distribution Robustness
Jun 16, 2021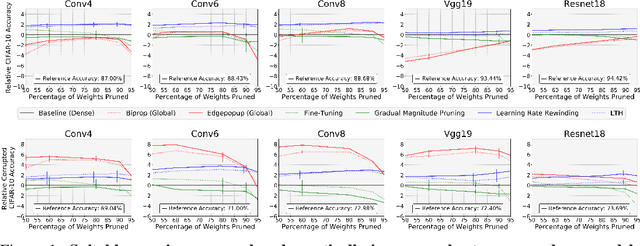
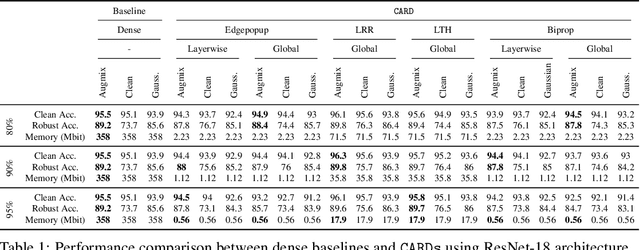
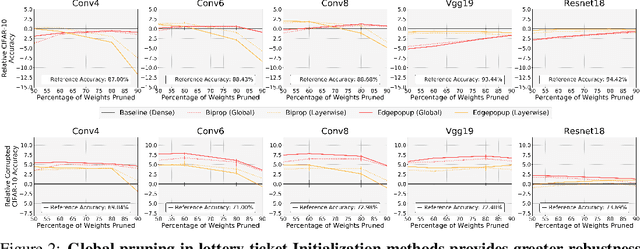
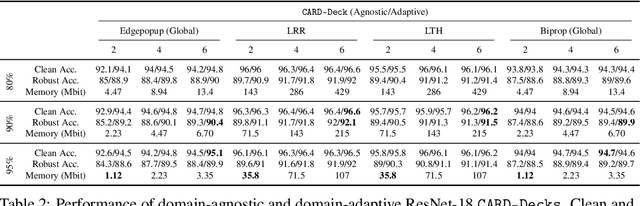
Two crucial requirements for a successful adoption of deep learning (DL) in the wild are: (1) robustness to distributional shifts, and (2) model compactness for achieving efficiency. Unfortunately, efforts towards simultaneously achieving Out-of-Distribution (OOD) robustness and extreme model compactness without sacrificing accuracy have mostly been unsuccessful. This raises an important question: "Is the inability to create compact, accurate, and robust deep neural networks (CARDs) fundamental?" To answer this question, we perform a large-scale analysis for a range of popular model compression techniques which uncovers several intriguing patterns. Notably, in contrast to traditional pruning approaches (e.g., fine tuning and gradual magnitude pruning), we find that "lottery ticket-style" pruning approaches can surprisingly be used to create high performing CARDs. Specifically, we are able to create extremely compact CARDs that are dramatically more robust than their significantly larger and full-precision counterparts while matching (or beating) their test accuracy, simply by pruning and/or quantizing. To better understand these differences, we perform sensitivity analysis in the Fourier domain for CARDs trained using different data augmentation methods. Motivated by our analysis, we develop a simple domain-adaptive test-time ensembling approach (CARD-Deck) that uses a gating module to dynamically select an appropriate CARD from the CARD-Deck based on their spectral-similarity with test samples. By leveraging complementary frequency biases of different compressed models, the proposed approach builds a "winning hand" of CARDs that establishes a new state-of-the-art on CIFAR-10-C accuracies (i.e., 96.8% clean and 92.75% robust) with dramatically better memory usage than their non-compressed counterparts. We also present some theoretical evidences supporting our empirical findings.
A Deep Learning-Accelerated Data Assimilation and Forecasting Workflow for Commercial-Scale Geologic Carbon Storage
May 09, 2021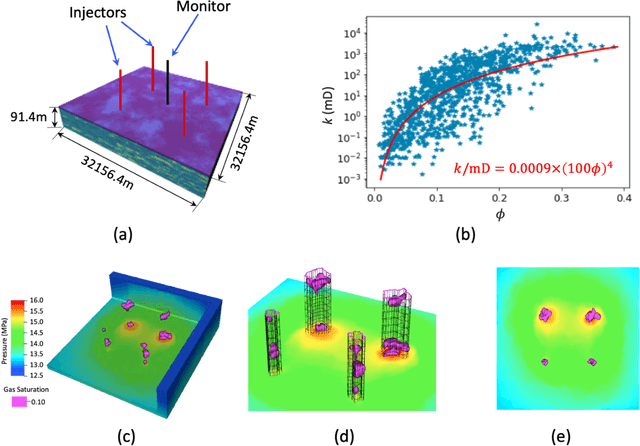

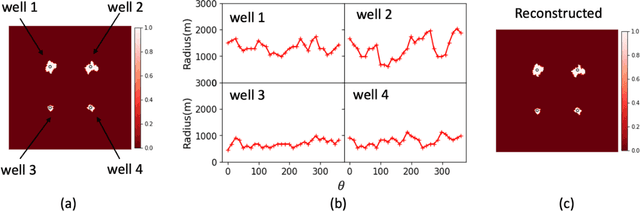
Fast assimilation of monitoring data to update forecasts of pressure buildup and carbon dioxide (CO2) plume migration under geologic uncertainties is a challenging problem in geologic carbon storage. The high computational cost of data assimilation with a high-dimensional parameter space impedes fast decision-making for commercial-scale reservoir management. We propose to leverage physical understandings of porous medium flow behavior with deep learning techniques to develop a fast history matching-reservoir response forecasting workflow. Applying an Ensemble Smoother Multiple Data Assimilation framework, the workflow updates geologic properties and predicts reservoir performance with quantified uncertainty from pressure history and CO2 plumes interpreted through seismic inversion. As the most computationally expensive component in such a workflow is reservoir simulation, we developed surrogate models to predict dynamic pressure and CO2 plume extents under multi-well injection. The surrogate models employ deep convolutional neural networks, specifically, a wide residual network and a residual U-Net. The workflow is validated against a flat three-dimensional reservoir model representative of a clastic shelf depositional environment. Intelligent treatments are applied to bridge between quantities in a true-3D reservoir model and those in a single-layer reservoir model. The workflow can complete history matching and reservoir forecasting with uncertainty quantification in less than one hour on a mainstream personal workstation.