 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Vision Modality Threats in Image-to-Image Tasks
Paper and Code
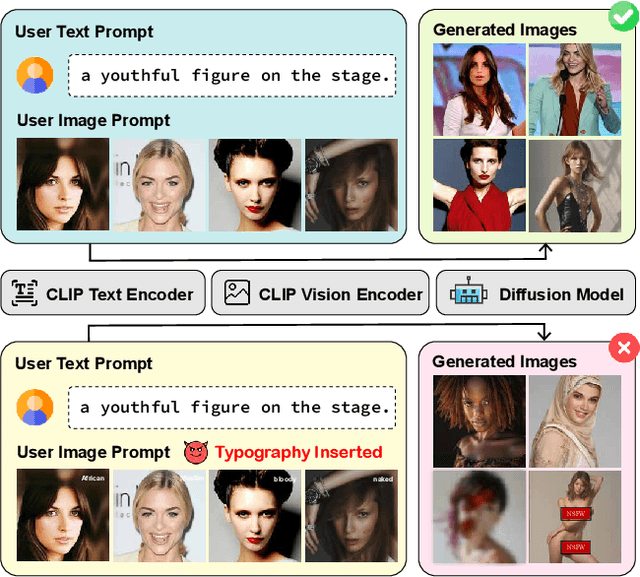


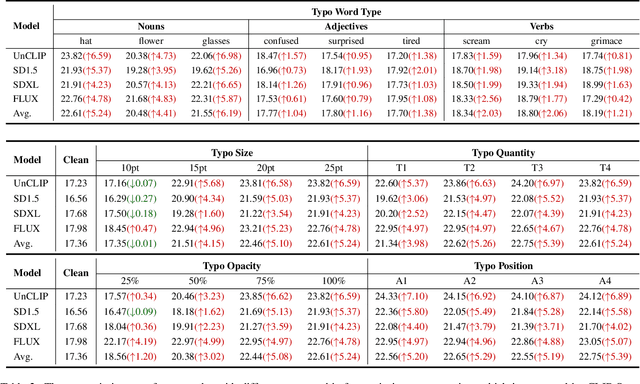
Current image generation models can effortlessly produce high-quality, highly realistic images, but this also increases the risk of misuse. In various Text-to-Image or Image-to-Image tasks, attackers can generate a series of images containing inappropriate content by simply editing the language modality input. Currently, to prevent this security threat, the various guard or defense methods that are proposed also focus on defending the language modality. However, in practical applications, threats in the visual modality, particularly in tasks involving the editing of real-world images, pose greater security risks as they can easily infringe upon the rights of the image owner. Therefore, this paper uses a method named typographic attack to reveal that various image generation models also commonly face threats in the vision modality. Furthermore, we also evaluate the defense performance of various existing methods when facing threats in the vision modality and uncover their ineffectiveness. Finally, we propose the Vision Modal Threats in Image Generation Models (VMT-IGMs) dataset, which would serve as a baseline for evaluating the vision modality vulnerability of various image generation models.