 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyncFed: Time-Aware Federated Learning through Explicit Timestamping and Synchronization
Jun 11, 2025As Federated Learning (FL) expands to larger and more distributed environments, consistency in training is challenged by network-induced delays, clock unsynchronicity, and variability in client updates. This combination of factors may contribute to misaligned contributions that undermine model reliability and convergence. Existing methods like staleness-aware aggregation and model versioning address lagging updates heuristically, yet lack mechanisms to quantify staleness, especially in latency-sensitive and cross-regional deployments. In light of these considerations, we introduce \emph{SyncFed}, a time-aware FL framework that employs explicit synchronization and timestamping to establish a common temporal reference across the system. Staleness is quantified numerically based on exchanged timestamps under the Network Time Protocol (NTP), enabling the server to reason about the relative freshness of client updates and apply temporally informed weighting during aggregation. Our empirical evaluation on a geographically distributed testbed shows that, under \emph{SyncFed}, the global model evolves within a stable temporal context, resulting in improved accuracy and information freshness compared to round-based baselines devoid of temporal semantics.
A Survey on Performance, Current and Future Usage of Vehicle-To-Everything Communication Standards
Oct 14, 2024



Wireless communication between road users is essential for environmental perception, reasoning, and mission planning to enable fully autonomous vehicles, and thus improve road safety and transport efficiency. To enable collaborative driving, the concept of vehicle-to-Everything (V2X) has long been introduced to the industry. Within the last two decades, several communication standards have been developed based on IEEE 802.11p and cellular standards, namely Dedicated Short-Range Communication (DSRC), Intelligent Transportation System G5 (ITS-G5), and Cellular- and New Radio- Vehicle-to-Everything (C-V2X and NR-V2X). However, while there exists a high quantity of available publications concerning V2X and the analysis of the different standards, only few surveys exist that summarize these results. Furthermore, to our knowledge, no survey that provides an analysis about possible future trends and challenges for the global implementation of V2Xexists. Thus, this contribution provides a detailed survey on Vehicle-to-Everything communication standards, their performance, current and future applications, and associated challenges. Based on our research, we have identified several research gaps and provide a picture about the possible future of the Vehicle-to-Everything communication domain.
Control Industrial Automation System with Large Language Models
Sep 26, 2024



Traditional industrial automation systems require specialized expertise to operate and complex reprogramming to adapt to new processes. Large language models offer the intelligence to make them more flexible and easier to use. However, LLMs' application in industrial settings is underexplored. This paper introduces a framework for integrating LLMs to achieve end-to-end control of industrial automation systems. At the core of the framework are an agent system designed for industrial tasks, a structured prompting method, and an event-driven information modeling mechanism that provides real-time data for LLM inference. The framework supplies LLMs with real-time events on different context semantic levels, allowing them to interpret the information, generate production plans, and control operations on the automation system. It also supports structured dataset creation for fine-tuning on this downstream application of LLMs. Our contribution includes a formal system design, proof-of-concept implementation, and a method for generating task-specific datasets for LLM fine-tuning and testing. This approach enables a more adaptive automation system that can respond to spontaneous events, while allowing easier operation and configuration through natural language for more intuitive human-machine interaction. We provide demo videos and detailed data on GitHub: https://github.com/YuchenXia/LLM4IAS
Incorporating Large Language Models into Production Systems for Enhanced Task Automation and Flexibility
Jul 11, 2024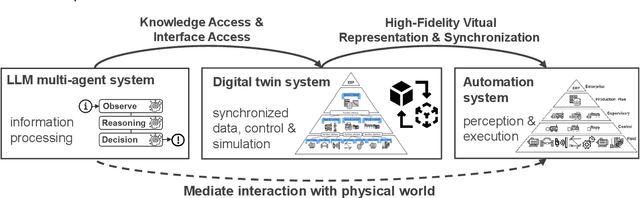
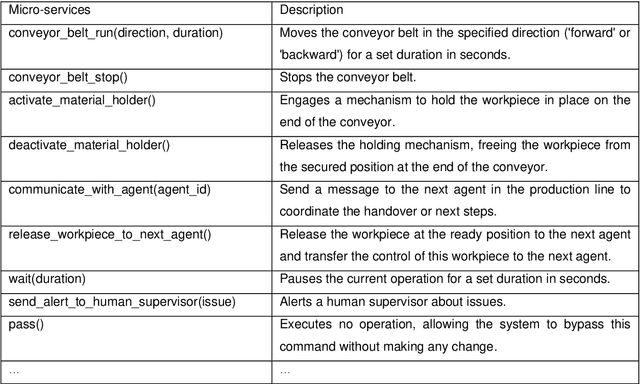
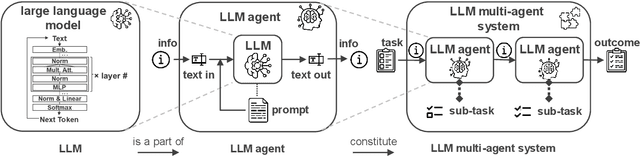
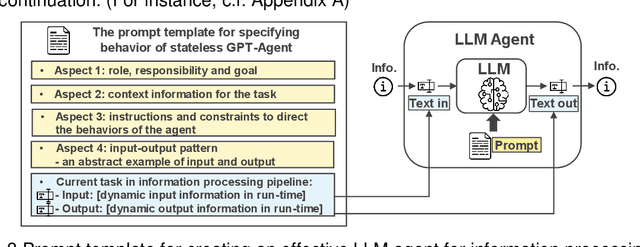
This paper introduces a novel approach to integrating large language model (LLM) agents into automated production systems, aimed at enhancing task automation and flexibility. We organize production operations within a hierarchical framework based on the automation pyramid. Atomic operation functionalities are modeled as microservices, which are executed through interface invocation within a dedicated digital twin system. This allows for a scalable and flexible foundation for orchestrating production processes. In this digital twin system, low-level, hardware-specific data is semantically enriched and made interpretable for LLMs for production planning and control tasks. Large language model agents are systematically prompted to interpret these production-specific data and knowledge. Upon receiving a user request or identifying a triggering event, the LLM agents generate a process plan. This plan is then decomposed into a series of atomic operations, executed as microservices within the real-world automation system. We implement this overall approach on an automated modular production facility at our laboratory, demonstrating how the LLMs can handle production planning and control tasks through a concrete case study. This results in an intuitive production facility with higher levels of task automation and flexibility. Finally, we reveal the several limitations in realizing the full potential of the large language models in autonomous systems and point out promising benefits. Demos of this series of ongoing research series can be accessed at: https://github.com/YuchenXia/GPT4IndustrialAutomation
Illustrating the benefits of efficient creation and adaption of behavior models in intelligent Digital Twins over the machine life cycle
Jun 12, 2024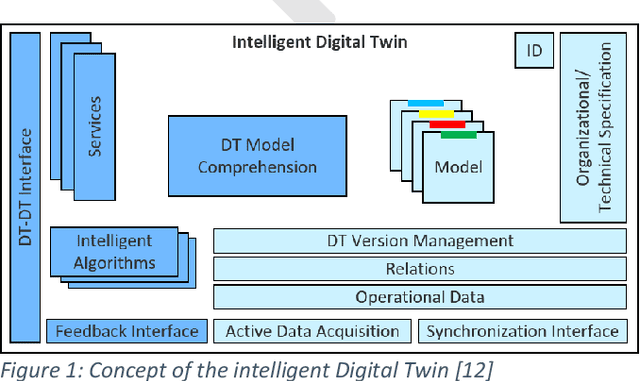
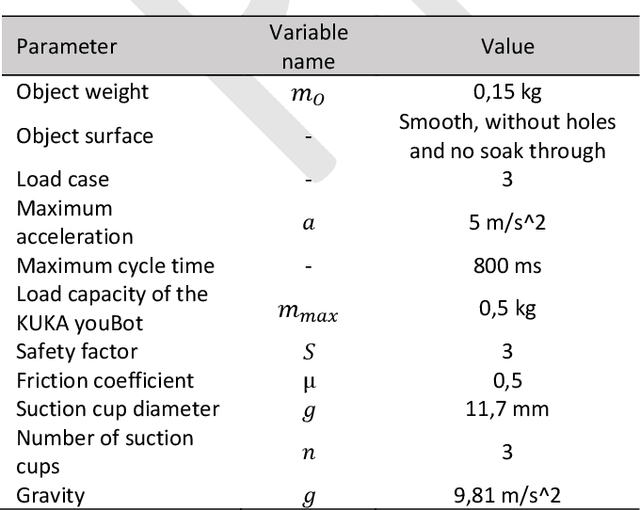
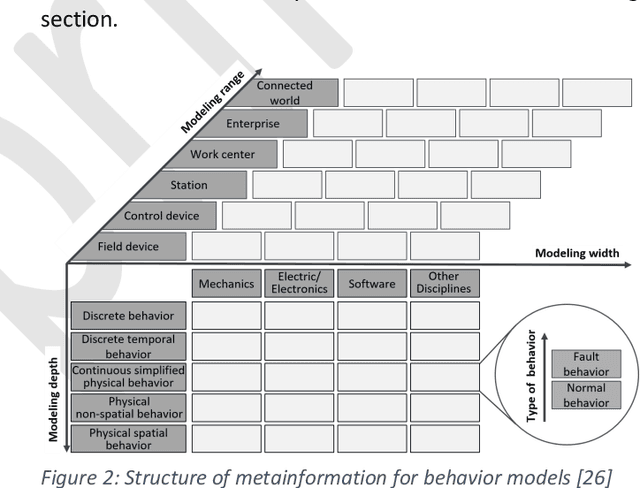
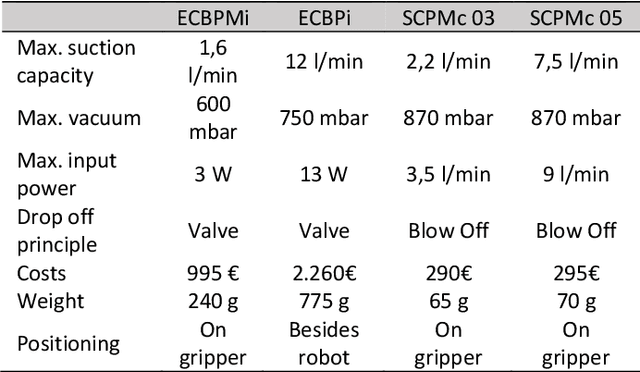
The concept of the Digital Twin, which in the context of this paper is the virtual representation of a production system or its components, can be used as a "digital playground" to master the increasing complexity of these assets. Central subcomponents of the Digital Twin are behavior models that can provide benefits over the entire machine life cycle. However, the creation, adaption and use of behavior models throughout the machine life cycle is very time-consuming, which is why approaches to improve the cost-benefit ratio are needed. Furthermore, there is a lack of specific use cases that illustrate the application and added benefit of behavior models over the machine life cycle, which is why the universal application of behavior models in industry is still lacking compared to research. This paper first presents the fundamentals, challenges and related work on Digital Twins and behavior models in the context of the machine life cycle. Then, concepts for low-effort creation and automatic adaption of Digital Twins are presented, with a focus on behavior models. Finally, the aforementioned gap between research and industry is addressed by demonstrating various realized use cases over the machine life cycle, in which the advantages as well as the application of behavior models in the different life phases are shown.
LLM experiments with simulation: Large Language Model Multi-Agent System for Process Simulation Parametrization in Digital Twins
May 28, 2024This paper presents a novel design of a multi-agent system framework that applies a large language model (LLM) to automate the parametrization of process simulations in digital twins. We propose a multi-agent framework that includes four types of agents: observation, reasoning, decision and summarization. By enabling dynamic interaction between LLM agents and simulation model, the developed system can automatically explore the parametrization of the simulation and use heuristic reasoning to determine a set of parameters to control the simulation to achieve an objective. The proposed approach enhances the simulation model by infusing it with heuristics from LLM and enables autonomous search for feasible parametrization to solve a user task. Furthermore, the system has the potential to increase user-friendliness and reduce the cognitive load on human users by assisting in complex decision-making processes. The effectiveness and functionality of the system are demonstrated through a case study, and the visualized demos are available at a GitHub Repository: https://github.com/YuchenXia/LLMDrivenSimulation
Generation of Asset Administration Shell with Large Language Model Agents: Interoperability in Digital Twins with Semantic Node
Mar 25, 2024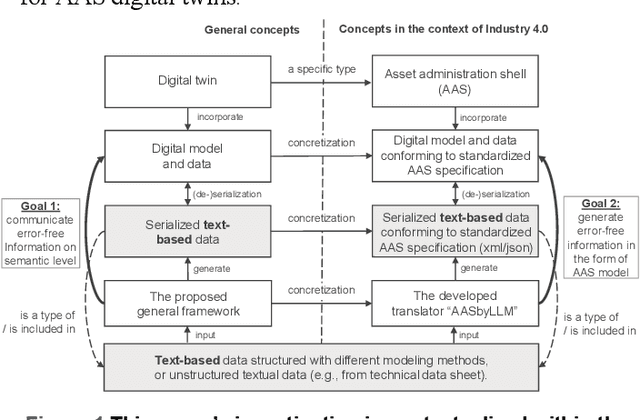
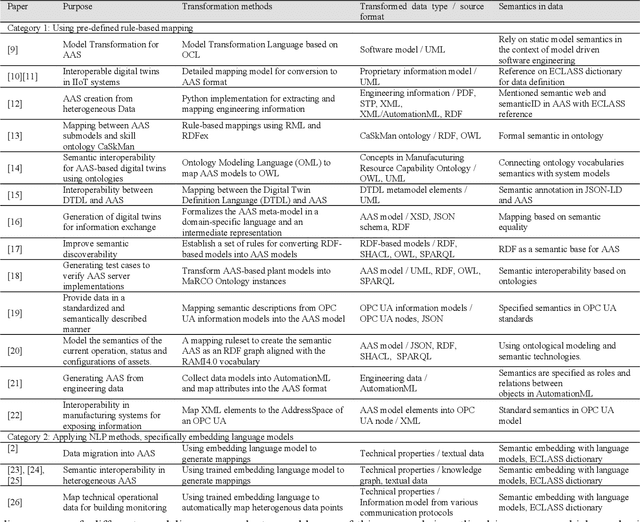
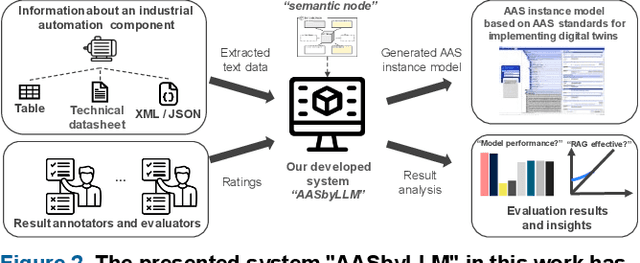
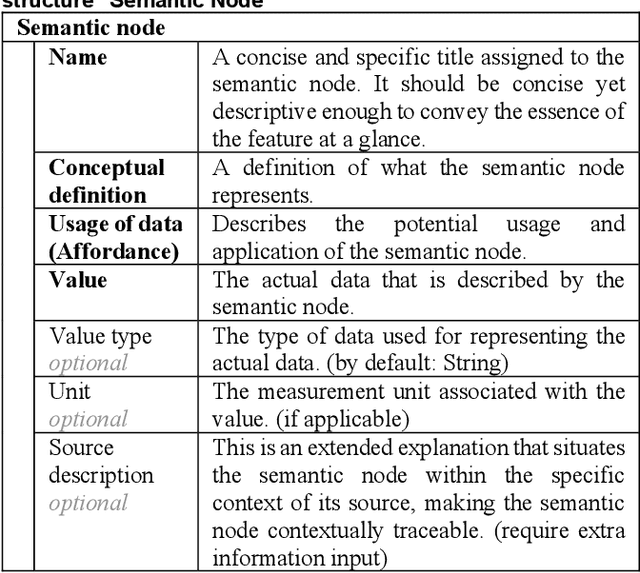
This research introduces a novel approach for assisting the creation of Asset Administration Shell (AAS) instances for digital twin modeling within the context of Industry 4.0, aiming to enhance interoperability in smart manufacturing and reduce manual effort. We construct a "semantic node" data structure to capture the semantic essence of textual data. Then, a system powered by large language models is designed and implemented to process "semantic node" and generate AAS instance models from textual technical data. Our evaluation demonstrates a 62-79% effective generation rate, indicating a substantial proportion of manual creation effort can be converted into easier validation effort, thereby reducing the time and cost in creating AAS instance models. In our evaluation, a comparative analysis of different LLMs and an in-depth ablation study of Retrieval-Augmented Generation (RAG) mechanisms provide insights into the effectiveness of LLM systems for interpreting technical concepts. Our findings emphasize LLMs' capability in automating AAS instance creation, enhancing semantic interoperability, and contributing to the broader field of semantic interoperability for digital twins in industrial applications. The prototype implementation and evaluation results are released on our GitHub Repository with the link: https://github.com/YuchenXia/AASbyLLM
Towards autonomous system: flexible modular production system enhanced with large language model agents
May 02, 2023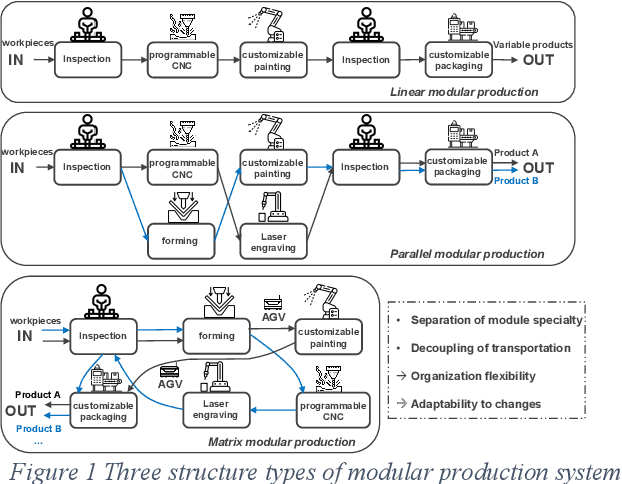
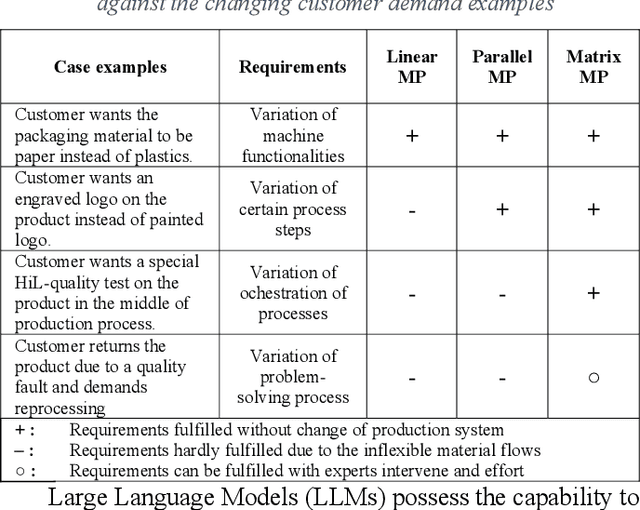
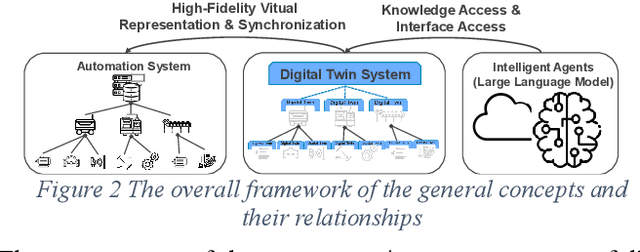
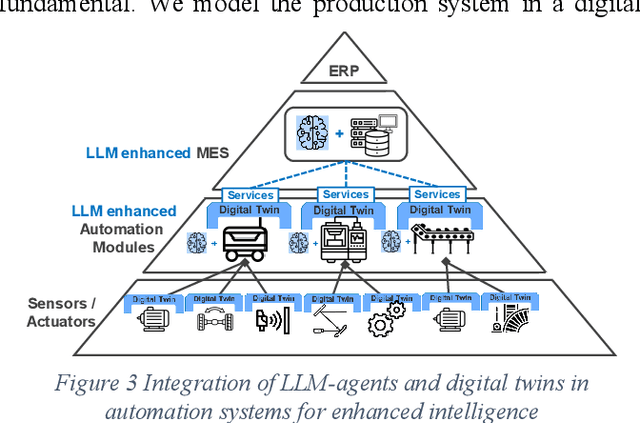
In this paper, we present a novel framework that combines large language models (LLMs), digital twins and industrial automation system to enable intelligent planning and control of production processes. We retrofit the automation system for a modular production facility and create executable control interfaces of fine-granular functionalities and coarse-granular skills. Low-level functionalities are executed by automation components, and high-level skills are performed by automation modules. Subsequently, a digital twin system is developed, registering these interfaces and containing additional descriptive information about the production system. Based on the retrofitted automation system and the created digital twins, LLM-agents are designed to interpret descriptive information in the digital twins and control the physical system through service interfaces. These LLM-agents serve as intelligent agents on different levels within an automation system, enabling autonomous planning and control of flexible production. Given a task instruction as input, the LLM-agents orchestrate a sequence of atomic functionalities and skills to accomplish the task. We demonstrate how our implemented prototype can handle un-predefined tasks, plan a production process, and execute the operations. This research highlights the potential of integrating LLMs into industrial automation systems in the context of smart factory for more agile, flexible, and adaptive production processes, while it also underscores the critical insights and limitations for future work.
Intelligent Exploration of Solution Spaces Exemplified by Industrial Reconfiguration Management
Jul 04, 2022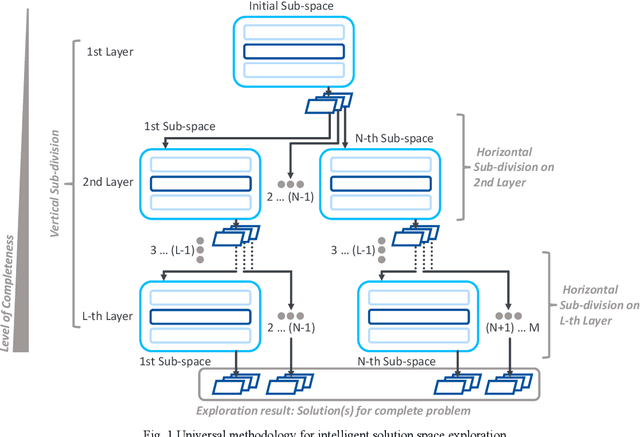

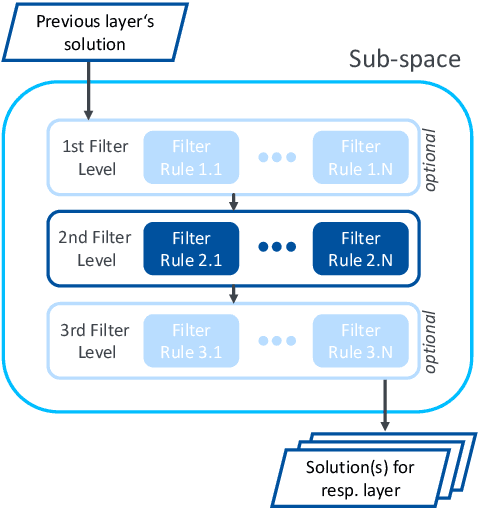
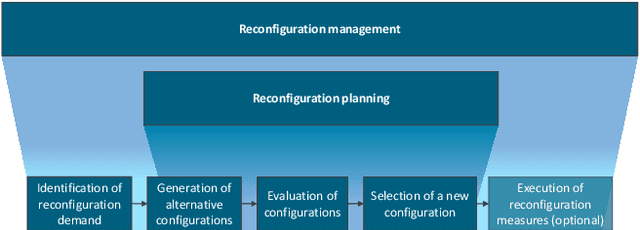
Many decision-making approaches rely on the exploration of solution spaces with regards to specified criteria. However, in complex environments, brute-force exploration strategies are usually not feasible. As an alternative, we propose the combination of an exploration task's vertical sub-division into layers representing different sequentially interdependent sub-problems of the paramount problem and a horizontal sub-division into self-sustained solution sub-spaces. In this paper, we present a universal methodology for the intelligent exploration of solution spaces and derive a use-case specific example from the field of reconfiguration management in industry 4.0.
Stuttgart Open Relay Degradation Dataset (SOReDD)
Apr 04, 2022
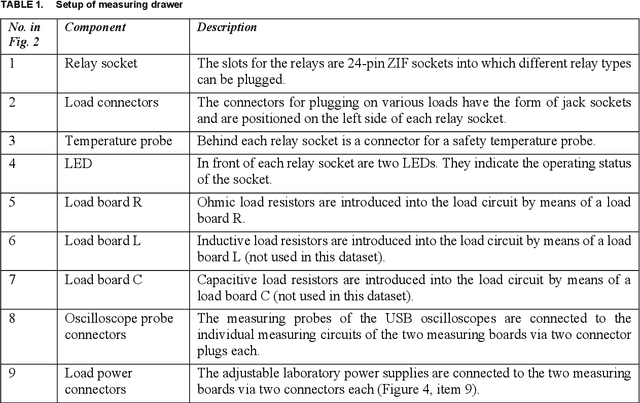


Real-life industrial use cases for machine learning oftentimes involve heterogeneous and dynamic assets, processes and data, resulting in a need to continuously adapt the learning algorithm accordingly. Industrial transfer learning offers to lower the effort of such adaptation by allowing the utilization of previously acquired knowledge in solving new (variants of) tasks. Being data-driven methods, the development of industrial transfer learning algorithms naturally requires appropriate datasets for training. However, open-source datasets suitable for transfer learning training, i.e. spanning different assets, processes and data (variants), are rare. With the Stuttgart Open Relay Degradation Dataset (SOReDD) we want to offer such a dataset. It provides data on the degradation of different electromechanical relays under different operating conditions, allowing for a large number of different transfer scenarios. Although such relays themselves are usually inexpensive standard components, their failure often leads to the failure of a machine as a whole due to their role as the central power switching element of a machine. The main cost factor in the event of a relay defect is therefore not the relay itself, but the reduced machine availability. It is therefore desirable to predict relay degradation as accurately as possible for specific applications in order to be able to replace relays in good time and avoid unplanned machine downtimes. Nevertheless, data-driven failure prediction for electromechanical relays faces the challenge that relay degradation behavior is highly dependent on the operating conditions, high-resolution measurement data on relay degradation behavior is only collected in rare cases, and such data can then only cover a fraction of the possible operating environments. Relays are thus representative of many other central standard components in automation technology.