 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Deep Industrial Transfer Learning in Fault Prognostics
Jan 04, 2023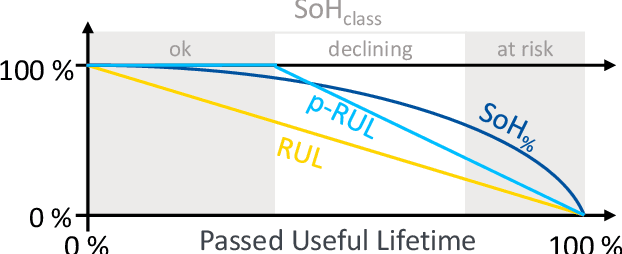

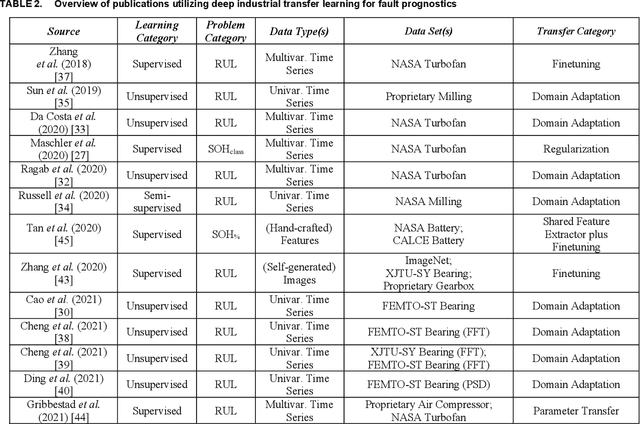

Due to its probabilistic nature, fault prognostics is a prime example of a use case for deep learning utilizing big data. However, the low availability of such data sets combined with the high effort of fitting, parameterizing and evaluating complex learning algorithms to the heterogenous and dynamic settings typical for industrial applications oftentimes prevents the practical application of this approach. Automatic adaptation to new or dynamically changing fault prognostics scenarios can be achieved using transfer learning or continual learning methods. In this paper, a first survey of such approaches is carried out, aiming at establishing best practices for future research in this field. It is shown that the field is lacking common benchmarks to robustly compare results and facilitate scientific progress. Therefore, the data sets utilized in these publications are surveyed as well in order to identify suitable candidates for such benchmark scenarios.
Intelligent Exploration of Solution Spaces Exemplified by Industrial Reconfiguration Management
Jul 04, 2022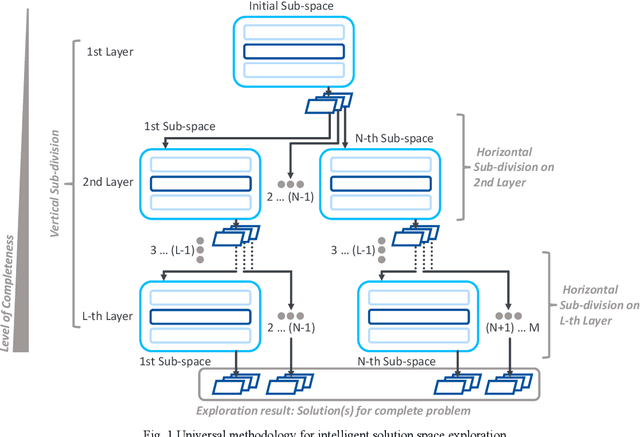

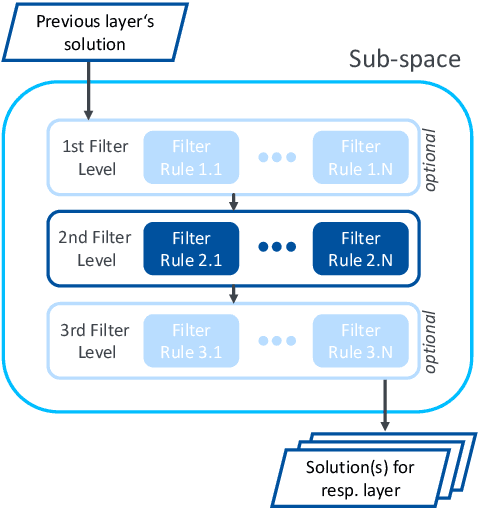
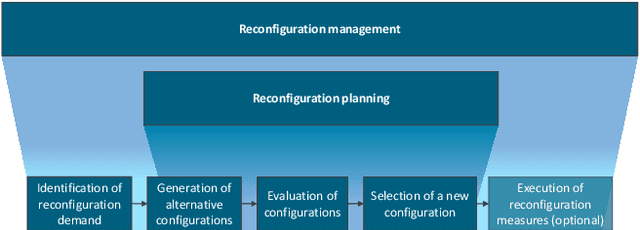
Many decision-making approaches rely on the exploration of solution spaces with regards to specified criteria. However, in complex environments, brute-force exploration strategies are usually not feasible. As an alternative, we propose the combination of an exploration task's vertical sub-division into layers representing different sequentially interdependent sub-problems of the paramount problem and a horizontal sub-division into self-sustained solution sub-spaces. In this paper, we present a universal methodology for the intelligent exploration of solution spaces and derive a use-case specific example from the field of reconfiguration management in industry 4.0.
Stuttgart Open Relay Degradation Dataset (SOReDD)
Apr 04, 2022
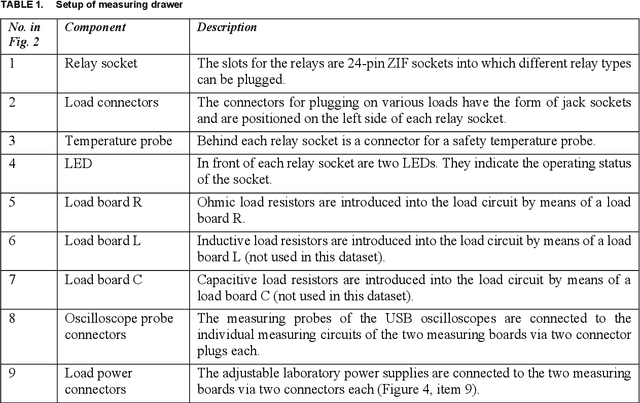


Real-life industrial use cases for machine learning oftentimes involve heterogeneous and dynamic assets, processes and data, resulting in a need to continuously adapt the learning algorithm accordingly. Industrial transfer learning offers to lower the effort of such adaptation by allowing the utilization of previously acquired knowledge in solving new (variants of) tasks. Being data-driven methods, the development of industrial transfer learning algorithms naturally requires appropriate datasets for training. However, open-source datasets suitable for transfer learning training, i.e. spanning different assets, processes and data (variants), are rare. With the Stuttgart Open Relay Degradation Dataset (SOReDD) we want to offer such a dataset. It provides data on the degradation of different electromechanical relays under different operating conditions, allowing for a large number of different transfer scenarios. Although such relays themselves are usually inexpensive standard components, their failure often leads to the failure of a machine as a whole due to their role as the central power switching element of a machine. The main cost factor in the event of a relay defect is therefore not the relay itself, but the reduced machine availability. It is therefore desirable to predict relay degradation as accurately as possible for specific applications in order to be able to replace relays in good time and avoid unplanned machine downtimes. Nevertheless, data-driven failure prediction for electromechanical relays faces the challenge that relay degradation behavior is highly dependent on the operating conditions, high-resolution measurement data on relay degradation behavior is only collected in rare cases, and such data can then only cover a fraction of the possible operating environments. Relays are thus representative of many other central standard components in automation technology.
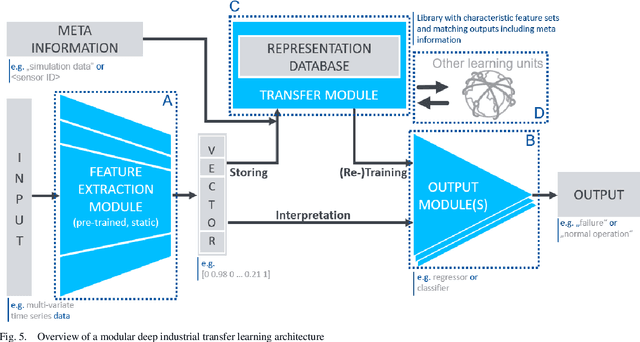
Towards Deep Industrial Transfer Learning: Clustering for Transfer Case Selection
Apr 04, 2022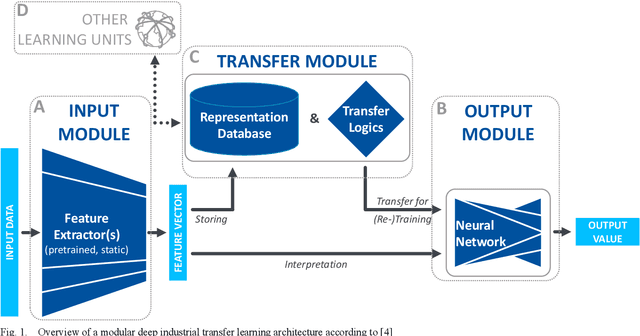
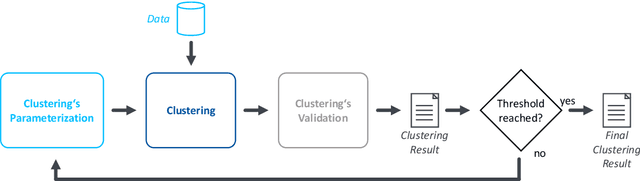
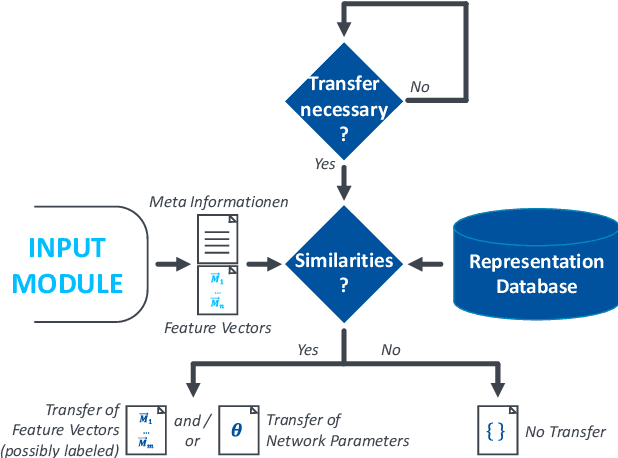
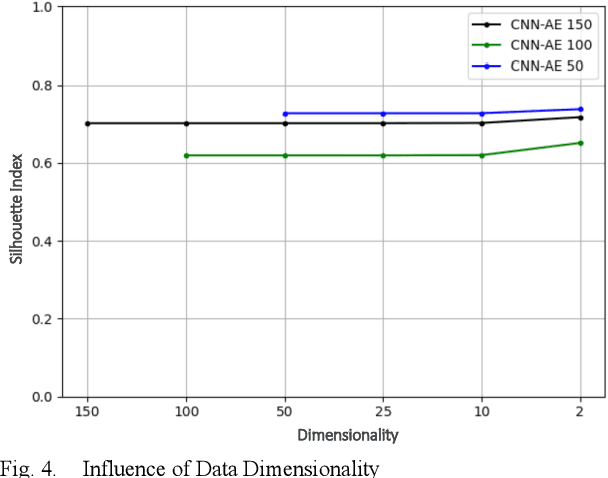
Industrial transfer learning increases the adaptability of deep learning algorithms towards heterogenous and dynamic industrial use cases without high manual efforts. The appropriate selection of what to transfer can vastly improve a transfer's results. In this paper, a transfer case selection based upon clustering is presented. Founded on a survey of clustering algorithms, the BIRCH algorithm is selected for this purpose. It is evaluated on an industrial time series dataset from a discrete manufacturing scenario. Results underline the approaches' applicability caused by its results' reproducibility and practical indifference to sequence, size and dimensionality of (sub-)datasets to be clustered sequentially.
Regularization-based Continual Learning for Fault Prediction in Lithium-Ion Batteries
Jul 07, 2021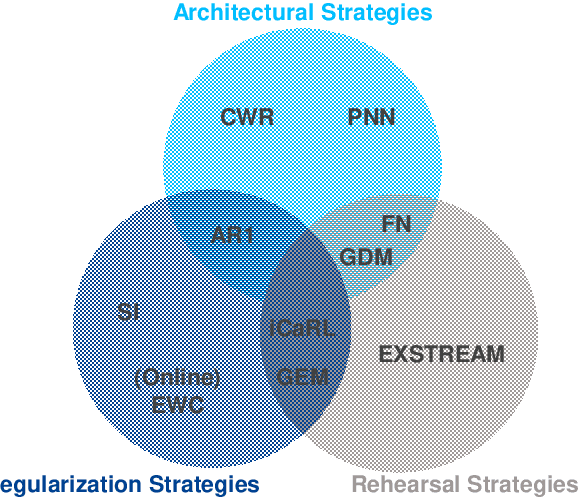


In recent years, the use of lithium-ion batteries has greatly expanded into products from many industrial sectors, e.g. cars, power tools or medical devices. An early prediction and robust understanding of battery faults could therefore greatly increase product quality in those fields. While current approaches for data-driven fault prediction provide good results on the exact processes they were trained on, they often lack the ability to flexibly adapt to changes, e.g. in operational or environmental parameters. Continual learning promises such flexibility, allowing for an automatic adaption of previously learnt knowledge to new tasks. Therefore, this article discusses different continual learning approaches from the group of regularization strategies, which are implemented, evaluated and compared based on a real battery wear dataset. Online elastic weight consolidation delivers the best results, but, as with all examined approaches, its performance appears to be strongly dependent on task characteristics and task sequence.
Towards Deep Industrial Transfer Learning for Anomaly Detection on Time Series Data
Jun 09, 2021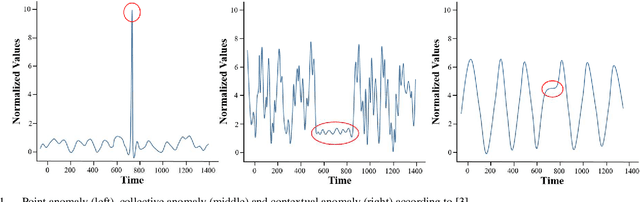
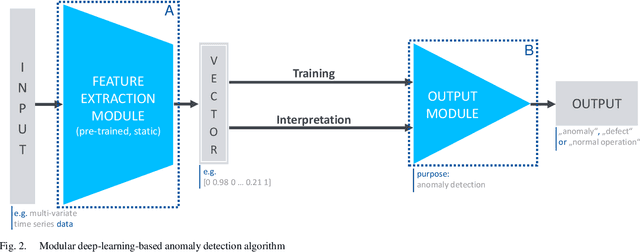
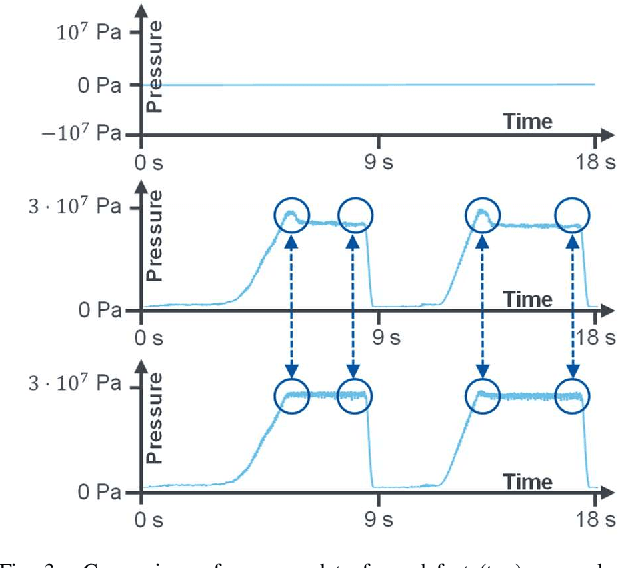
Deep learning promises performant anomaly detection on time-variant datasets, but greatly suffers from low availability of suitable training datasets and frequently changing tasks. Deep transfer learning offers mitigation by letting algorithms built upon previous knowledge from different tasks or locations. In this article, a modular deep learning algorithm for anomaly detection on time series datasets is presented that allows for an easy integration of such transfer learning capabilities. It is thoroughly tested on a dataset from a discrete manufacturing process in order to prove its fundamental adequacy towards deep industrial transfer learning - the transfer of knowledge in industrial applications' special environment.
Transfer Learning as an Enhancement for Reconfiguration Management of Cyber-Physical Production Systems
May 31, 2021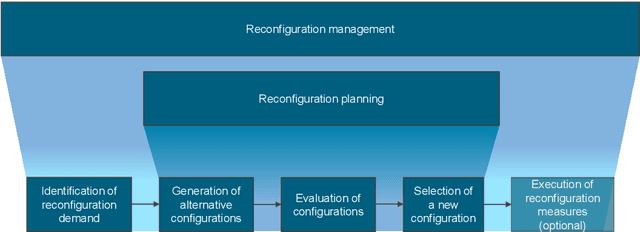

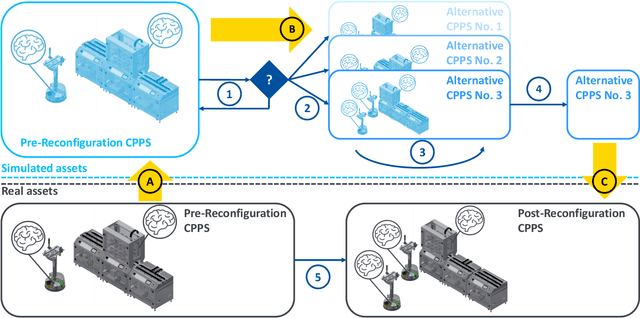
Reconfiguration demand is increasing due to frequent requirement changes for manufacturing systems. Recent approaches aim at investigating feasible configuration alternatives from which they select the optimal one. This relies on processes whose behavior is not reliant on e.g. the production sequence. However, when machine learning is used, components' behavior depends on the process' specifics, requiring additional concepts to successfully conduct reconfiguration management. Therefore, we propose the enhancement of the comprehensive reconfiguration management with transfer learning. This provides the ability to assess the machine learning dependent behavior of the different CPPS configurations with reduced effort and further assists the recommissioning of the chosen one. A real cyber-physical production system from the discrete manufacturing domain is utilized to demonstrate the aforementioned proposal.
A Survey on Anomaly Detection for Technical Systems using LSTM Networks
May 28, 2021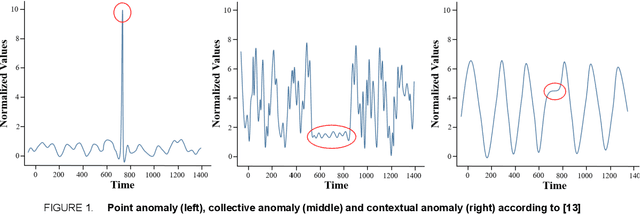
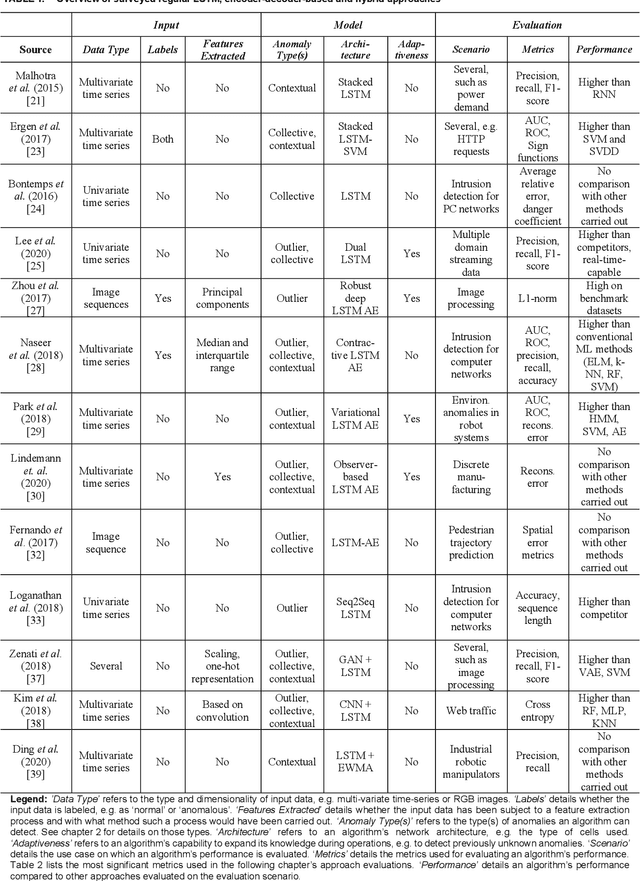
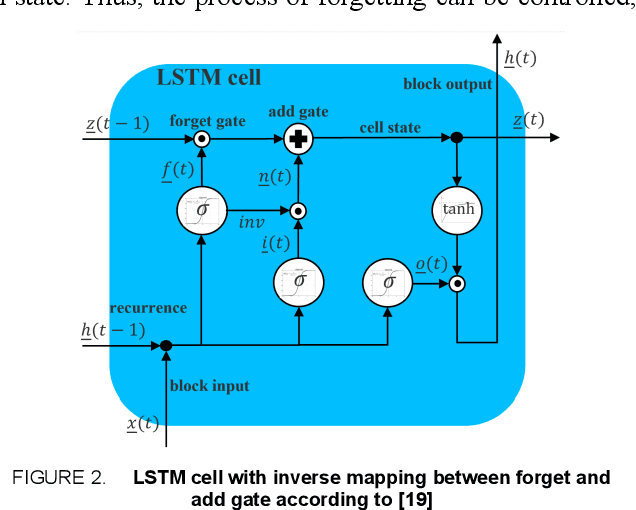

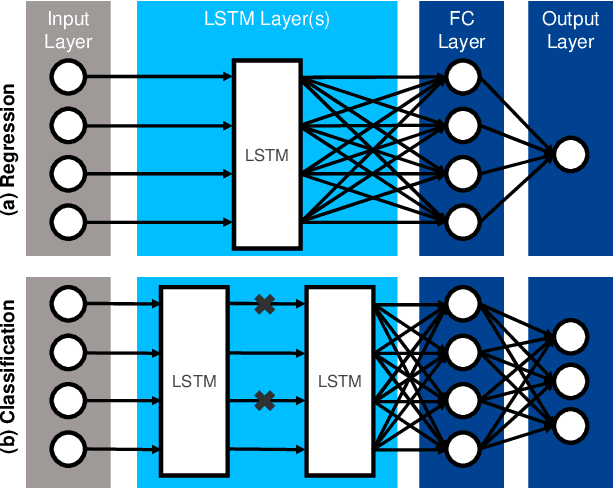
Anomalies represent deviations from the intended system operation and can lead to decreased efficiency as well as partial or complete system failure. As the causes of anomalies are often unknown due to complex system dynamics, efficient anomaly detection is necessary. Conventional detection approaches rely on statistical and time-invariant methods that fail to address the complex and dynamic nature of anomalies. With advances in artificial intelligence and increasing importance for anomaly detection and prevention in various domains, artificial neural network approaches enable the detection of more complex anomaly types while considering temporal and contextual characteristics. In this article, a survey on state-of-the-art anomaly detection using deep neural and especially long short-term memory networks is conducted. The investigated approaches are evaluated based on the application scenario, data and anomaly types as well as further metrics. To highlight the potential of upcoming anomaly detection techniques, graph-based and transfer learning approaches are also included in the survey, enabling the analysis of heterogeneous data as well as compensating for its shortage and improving the handling of dynamic processes.
Regularization-based Continual Learning for Anomaly Detection in Discrete Manufacturing
Jan 02, 2021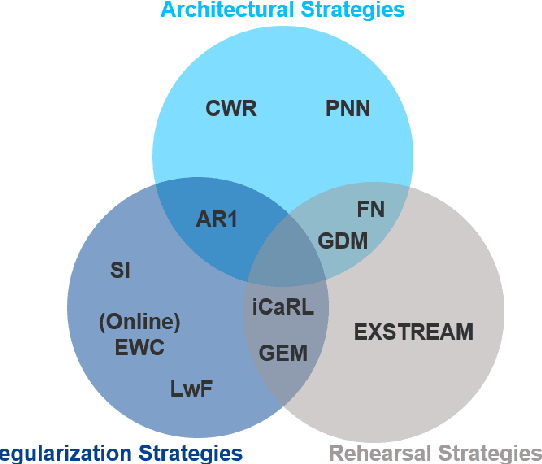

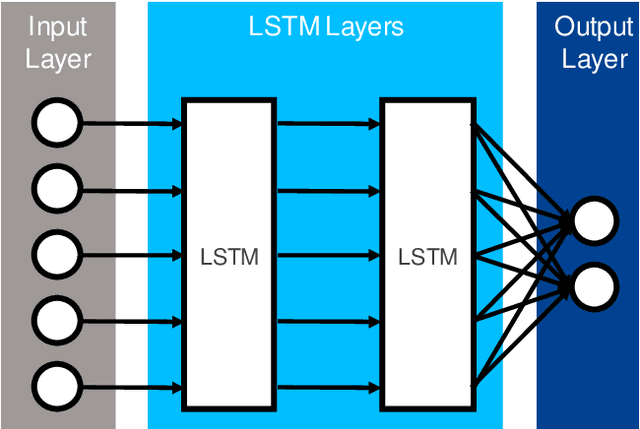

The early and robust detection of anomalies occurring in discrete manufacturing processes allows operators to prevent harm, e.g. defects in production machinery or products. While current approaches for data-driven anomaly detection provide good results on the exact processes they were trained on, they often lack the ability to flexibly adapt to changes, e.g. in products. Continual learning promises such flexibility, allowing for an automatic adaption of previously learnt knowledge to new tasks. Therefore, this article discusses different continual learning approaches from the group of regularization strategies, which are implemented, evaluated and compared based on a real industrial metal forming dataset.
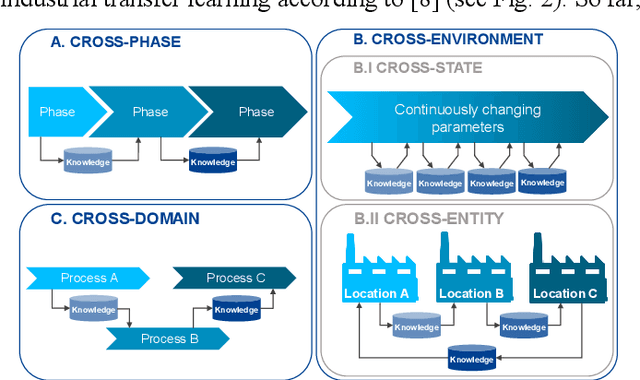
Deep Transfer Learning for Industrial Automation: A Review and Discussion of New Techniques for Data-Driven Machine Learning
Dec 06, 2020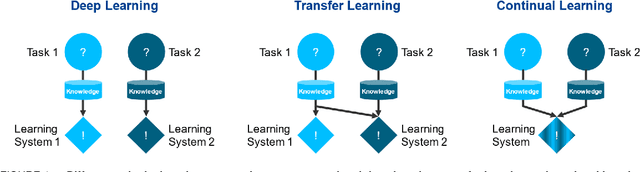
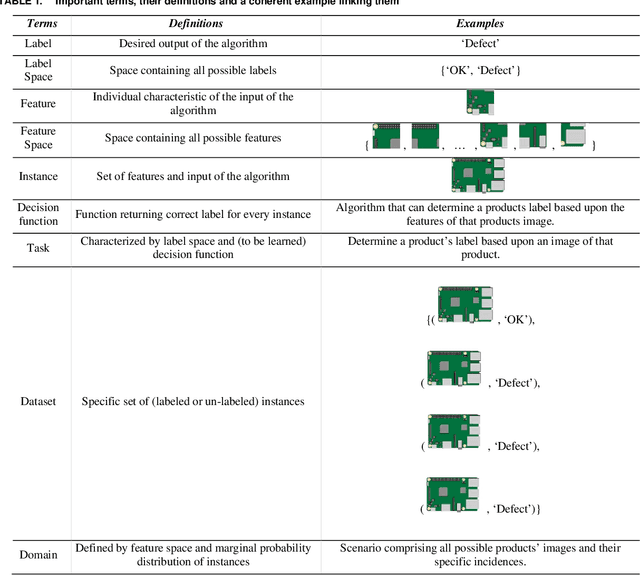
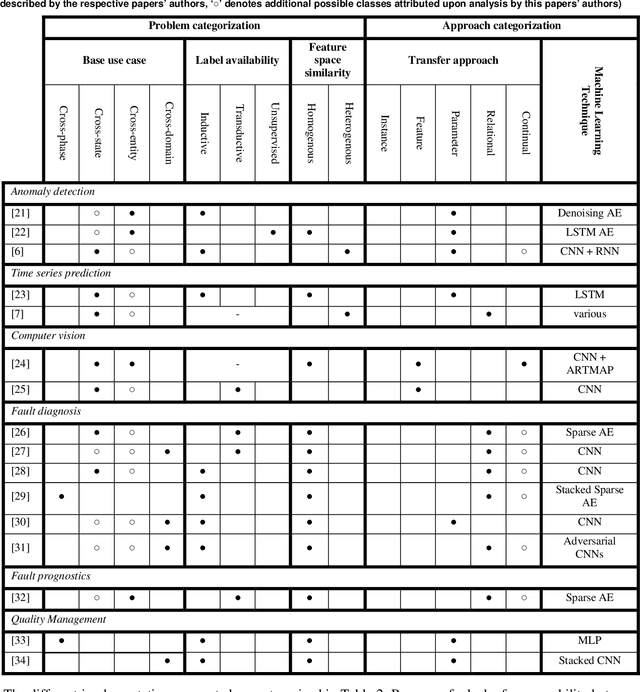
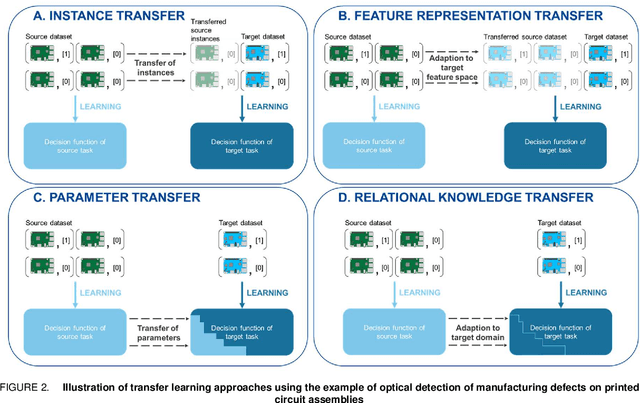
In this article, the concepts of transfer and continual learning are introduced. The ensuing review reveals promising approaches for industrial deep transfer learning, utilizing methods of both classes of algorithms. In the field of computer vision, it is already state-of-the-art. In others, e.g. fault prediction, it is barely starting. However, over all fields, the abstract differentiation between continual and transfer learning is not benefitting their practical use. In contrast, both should be brought together to create robust learning algorithms fulfilling the industrial automation sector's requirements. To better describe these requirements, base use cases of industrial transfer learning are introduced.