Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deep Industrial Transfer Learning: Clustering for Transfer Case Selection
Paper and Code
Apr 04, 2022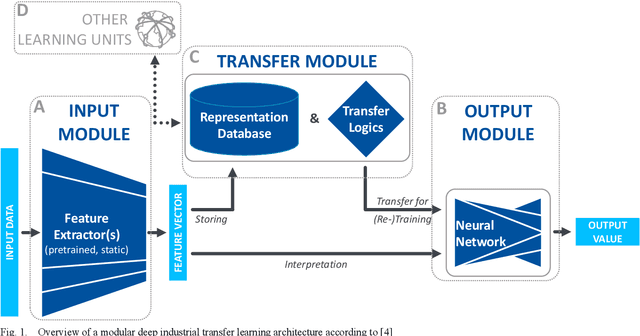
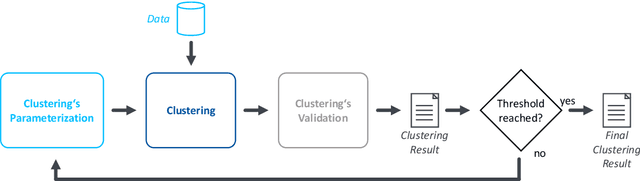
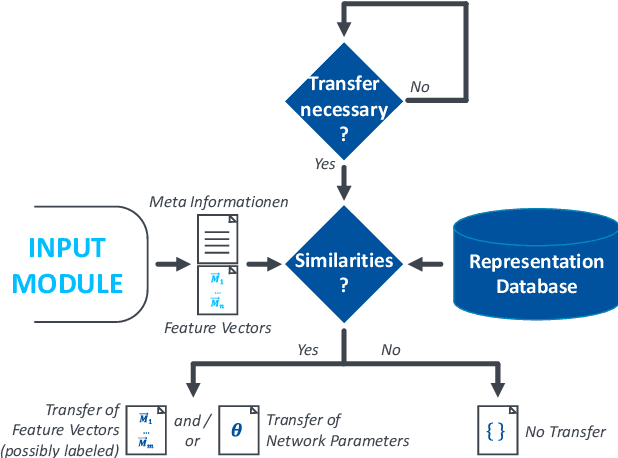
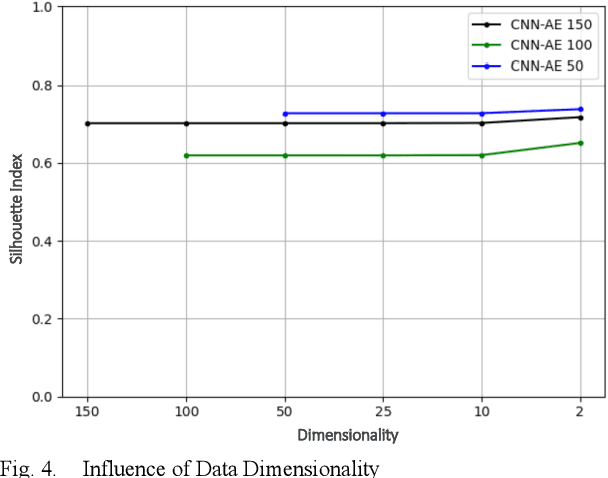
Industrial transfer learning increases the adaptability of deep learning algorithms towards heterogenous and dynamic industrial use cases without high manual efforts. The appropriate selection of what to transfer can vastly improve a transfer's results. In this paper, a transfer case selection based upon clustering is presented. Founded on a survey of clustering algorithms, the BIRCH algorithm is selected for this purpose. It is evaluated on an industrial time series dataset from a discrete manufacturing scenario. Results underline the approaches' applicability caused by its results' reproducibility and practical indifference to sequence, size and dimensionality of (sub-)datasets to be clustered sequentially.
* 7 pages, 5 figurs, 2 tables. Submitted to IEEE ETFA 2022
View paper on