 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Deep Industrial Transfer Learning in Fault Prognostics
Paper and Code
Jan 04, 2023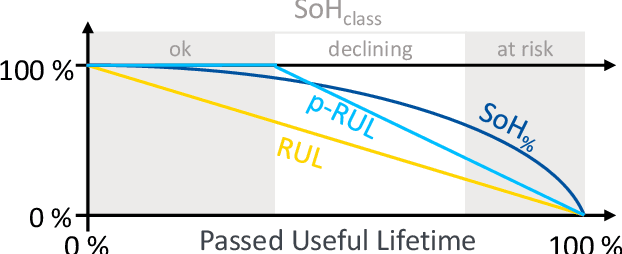

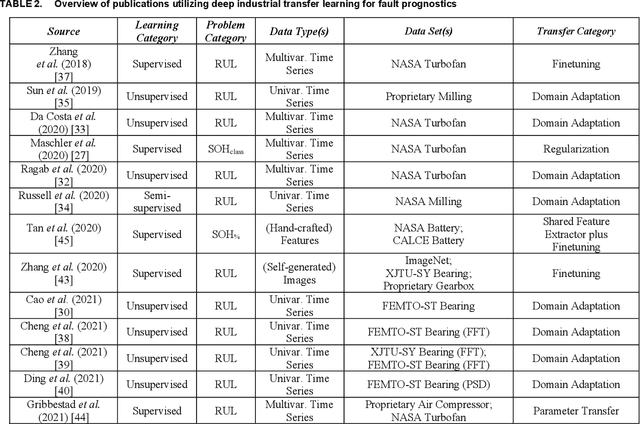

Due to its probabilistic nature, fault prognostics is a prime example of a use case for deep learning utilizing big data. However, the low availability of such data sets combined with the high effort of fitting, parameterizing and evaluating complex learning algorithms to the heterogenous and dynamic settings typical for industrial applications oftentimes prevents the practical application of this approach. Automatic adaptation to new or dynamically changing fault prognostics scenarios can be achieved using transfer learning or continual learning methods. In this paper, a first survey of such approaches is carried out, aiming at establishing best practices for future research in this field. It is shown that the field is lacking common benchmarks to robustly compare results and facilitate scientific progress. Therefore, the data sets utilized in these publications are surveyed as well in order to identify suitable candidates for such benchmark scenarios.