 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStuttgart Open Relay Degradation Dataset (SOReDD)
Apr 04, 2022
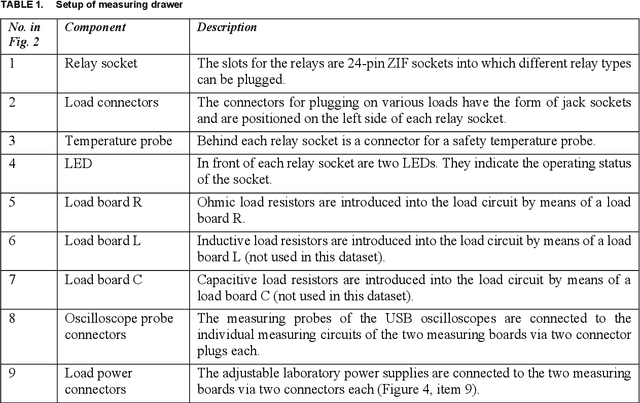


Real-life industrial use cases for machine learning oftentimes involve heterogeneous and dynamic assets, processes and data, resulting in a need to continuously adapt the learning algorithm accordingly. Industrial transfer learning offers to lower the effort of such adaptation by allowing the utilization of previously acquired knowledge in solving new (variants of) tasks. Being data-driven methods, the development of industrial transfer learning algorithms naturally requires appropriate datasets for training. However, open-source datasets suitable for transfer learning training, i.e. spanning different assets, processes and data (variants), are rare. With the Stuttgart Open Relay Degradation Dataset (SOReDD) we want to offer such a dataset. It provides data on the degradation of different electromechanical relays under different operating conditions, allowing for a large number of different transfer scenarios. Although such relays themselves are usually inexpensive standard components, their failure often leads to the failure of a machine as a whole due to their role as the central power switching element of a machine. The main cost factor in the event of a relay defect is therefore not the relay itself, but the reduced machine availability. It is therefore desirable to predict relay degradation as accurately as possible for specific applications in order to be able to replace relays in good time and avoid unplanned machine downtimes. Nevertheless, data-driven failure prediction for electromechanical relays faces the challenge that relay degradation behavior is highly dependent on the operating conditions, high-resolution measurement data on relay degradation behavior is only collected in rare cases, and such data can then only cover a fraction of the possible operating environments. Relays are thus representative of many other central standard components in automation technology.
Regularization-based Continual Learning for Anomaly Detection in Discrete Manufacturing
Jan 02, 2021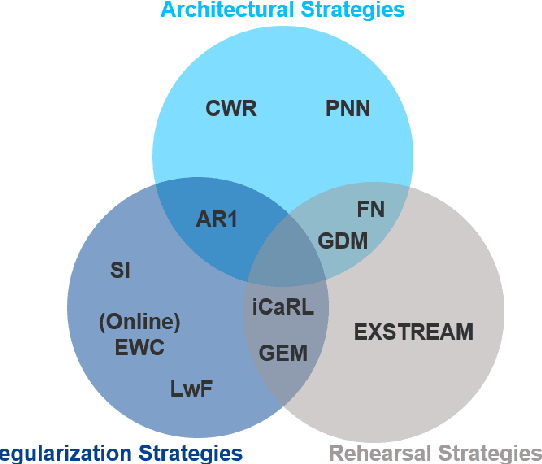

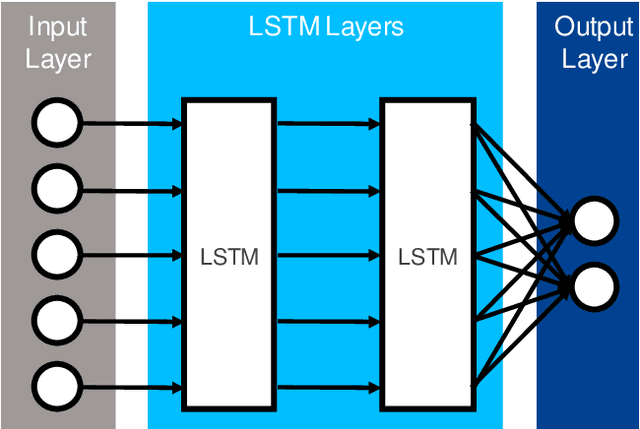

The early and robust detection of anomalies occurring in discrete manufacturing processes allows operators to prevent harm, e.g. defects in production machinery or products. While current approaches for data-driven anomaly detection provide good results on the exact processes they were trained on, they often lack the ability to flexibly adapt to changes, e.g. in products. Continual learning promises such flexibility, allowing for an automatic adaption of previously learnt knowledge to new tasks. Therefore, this article discusses different continual learning approaches from the group of regularization strategies, which are implemented, evaluated and compared based on a real industrial metal forming dataset.