 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Laplacian Positional Encodings for Heterophilous Graphs
Apr 29, 2025In this work, we theoretically demonstrate that current graph positional encodings (PEs) are not beneficial and could potentially hurt performance in tasks involving heterophilous graphs, where nodes that are close tend to have different labels. This limitation is critical as many real-world networks exhibit heterophily, and even highly homophilous graphs can contain local regions of strong heterophily. To address this limitation, we propose Learnable Laplacian Positional Encodings (LLPE), a new PE that leverages the full spectrum of the graph Laplacian, enabling them to capture graph structure on both homophilous and heterophilous graphs. Theoretically, we prove LLPE's ability to approximate a general class of graph distances and demonstrate its generalization properties. Empirically, our evaluation on 12 benchmarks demonstrates that LLPE improves accuracy across a variety of GNNs, including graph transformers, by up to 35% and 14% on synthetic and real-world graphs, respectively. Going forward, our work represents a significant step towards developing PEs that effectively capture complex structures in heterophilous graphs.
On the Impact of Feature Heterophily on Link Prediction with Graph Neural Networks
Sep 26, 2024
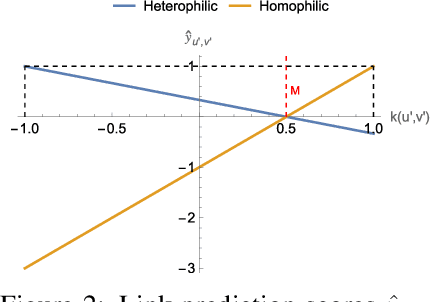
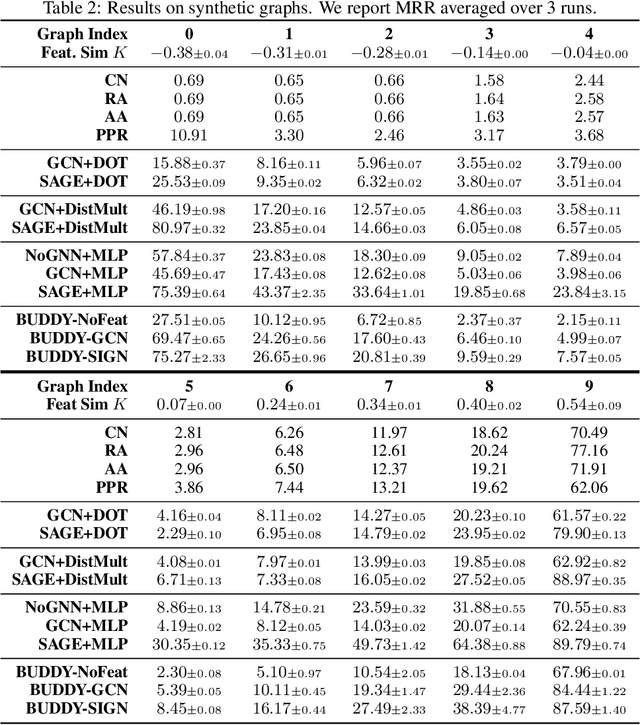
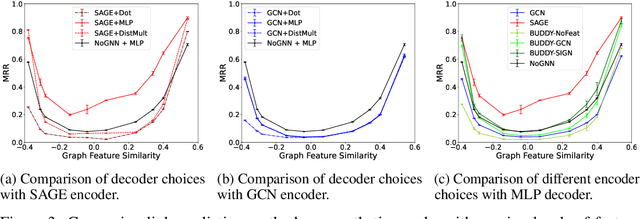
Heterophily, or the tendency of connected nodes in networks to have different class labels or dissimilar features, has been identified as challenging for many Graph Neural Network (GNN) models. While the challenges of applying GNNs for node classification when class labels display strong heterophily are well understood, it is unclear how heterophily affects GNN performance in other important graph learning tasks where class labels are not available. In this work, we focus on the link prediction task and systematically analyze the impact of heterophily in node features on GNN performance. Theoretically, we first introduce formal definitions of homophilic and heterophilic link prediction tasks, and present a theoretical framework that highlights the different optimizations needed for the respective tasks. We then analyze how different link prediction encoders and decoders adapt to varying levels of feature homophily and introduce designs for improved performance. Our empirical analysis on a variety of synthetic and real-world datasets confirms our theoretical insights and highlights the importance of adopting learnable decoders and GNN encoders with ego- and neighbor-embedding separation in message passing for link prediction tasks beyond homophily.
Graph Coarsening via Convolution Matching for Scalable Graph Neural Network Training
Dec 24, 2023



Graph summarization as a preprocessing step is an effective and complementary technique for scalable graph neural network (GNN) training. In this work, we propose the Coarsening Via Convolution Matching (CONVMATCH) algorithm and a highly scalable variant, A-CONVMATCH, for creating summarized graphs that preserve the output of graph convolution. We evaluate CONVMATCH on six real-world link prediction and node classification graph datasets, and show it is efficient and preserves prediction performance while significantly reducing the graph size. Notably, CONVMATCH achieves up to 95% of the prediction performance of GNNs on node classification while trained on graphs summarized down to 1% the size of the original graph. Furthermore, on link prediction tasks, CONVMATCH consistently outperforms all baselines, achieving up to a 2x improvement.
On Performance Discrepancies Across Local Homophily Levels in Graph Neural Networks
Jun 08, 2023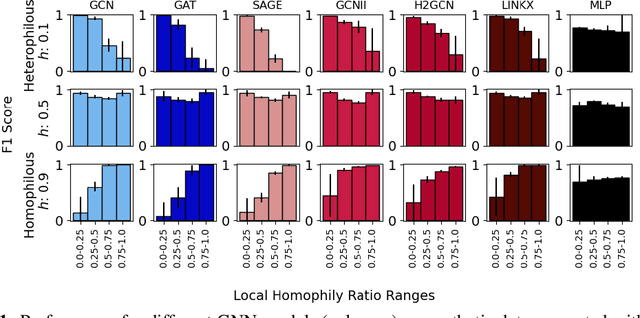

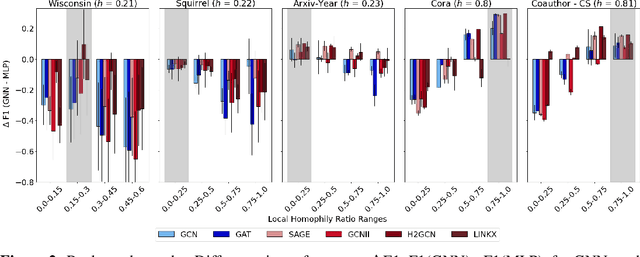

Research on GNNs has highlighted a relationship between high homophily (i.e., the tendency for nodes of a similar class to connect) and strong predictive performance in node classification. However, recent research has found the relationship to be more nuanced, demonstrating that even simple GNNs can learn in certain heterophilous settings. To bridge the gap between these findings, we revisit the assumptions made in previous works and identify that datasets are often treated as having a constant homophily level across nodes. To align closer to real-world datasets, we theoretically and empirically study the performance of GNNs when the local homophily level of a node deviates at test-time from the global homophily level of its graph. To aid our theoretical analysis, we introduce a new parameter to the preferential attachment model commonly used in homophily analysis to enable the control of local homophily levels in generated graphs, enabling a systematic empirical study on how local homophily can impact performance. We additionally perform a granular analysis on a number of real-world datasets with varying global homophily levels. Across our theoretical and empirical results, we find that (a)~ GNNs can fail to generalize to test nodes that deviate from the global homophily of a graph, (b)~ high local homophily does not necessarily confer high performance for a node, and (c)~ GNN models designed to handle heterophily are able to perform better across varying heterophily ranges irrespective of the dataset's global homophily. These findings point towards a GNN's over-reliance on the global homophily used for training and motivates the need to design GNNs that can better generalize across large local homophily ranges.
Simplifying Distributed Neural Network Training on Massive Graphs: Randomized Partitions Improve Model Aggregation
May 17, 2023



Distributed training of GNNs enables learning on massive graphs (e.g., social and e-commerce networks) that exceed the storage and computational capacity of a single machine. To reach performance comparable to centralized training, distributed frameworks focus on maximally recovering cross-instance node dependencies with either communication across instances or periodic fallback to centralized training, which create overhead and limit the framework scalability. In this work, we present a simplified framework for distributed GNN training that does not rely on the aforementioned costly operations, and has improved scalability, convergence speed and performance over the state-of-the-art approaches. Specifically, our framework (1) assembles independent trainers, each of which asynchronously learns a local model on locally-available parts of the training graph, and (2) only conducts periodic (time-based) model aggregation to synchronize the local models. Backed by our theoretical analysis, instead of maximizing the recovery of cross-instance node dependencies -- which has been considered the key behind closing the performance gap between model aggregation and centralized training -- , our framework leverages randomized assignment of nodes or super-nodes (i.e., collections of original nodes) to partition the training graph such that it improves data uniformity and minimizes the discrepancy of gradient and loss function across instances. In our experiments on social and e-commerce networks with up to 1.3 billion edges, our proposed RandomTMA and SuperTMA approaches -- despite using less training data -- achieve state-of-the-art performance and 2.31x speedup compared to the fastest baseline, and show better robustness to trainer failures.
On Graph Neural Network Fairness in the Presence of Heterophilous Neighborhoods
Jul 10, 2022
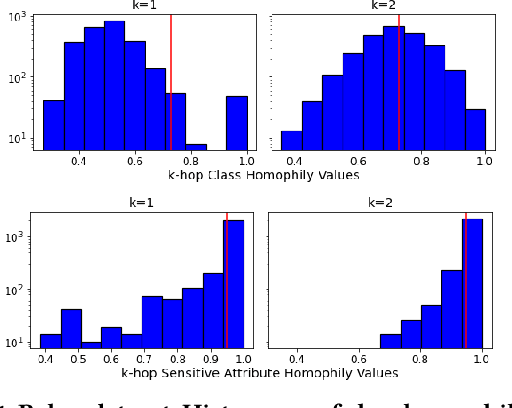


We study the task of node classification for graph neural networks (GNNs) and establish a connection between group fairness, as measured by statistical parity and equal opportunity, and local assortativity, i.e., the tendency of linked nodes to have similar attributes. Such assortativity is often induced by homophily, the tendency for nodes of similar properties to connect. Homophily can be common in social networks where systemic factors have forced individuals into communities which share a sensitive attribute. Through synthetic graphs, we study the interplay between locally occurring homophily and fair predictions, finding that not all node neighborhoods are equal in this respect -- neighborhoods dominated by one category of a sensitive attribute often struggle to obtain fair treatment, especially in the case of diverging local class and sensitive attribute homophily. After determining that a relationship between local homophily and fairness exists, we investigate if the issue of unfairness can be associated to the design of the applied GNN model. We show that by adopting heterophilous GNN designs capable of handling disassortative group labels, group fairness in locally heterophilous neighborhoods can be improved by up to 25% over homophilous designs in real and synthetic datasets.
Improving Robustness of Graph Neural Networks with Heterophily-Inspired Designs
Jun 14, 2021
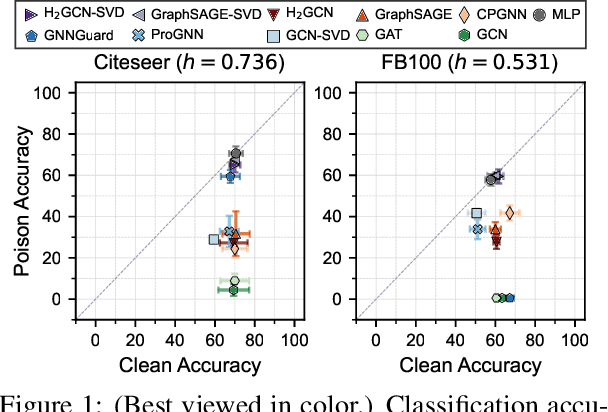
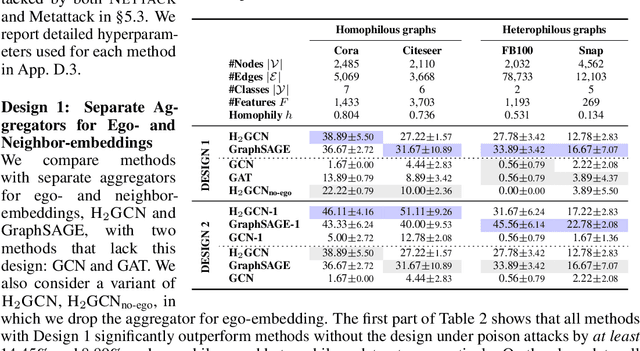

Recent studies have exposed that many graph neural networks (GNNs) are sensitive to adversarial attacks, and can suffer from performance loss if the graph structure is intentionally perturbed. A different line of research has shown that many GNN architectures implicitly assume that the underlying graph displays homophily, i.e., connected nodes are more likely to have similar features and class labels, and perform poorly if this assumption is not fulfilled. In this work, we formalize the relation between these two seemingly different issues. We theoretically show that in the standard scenario in which node features exhibit homophily, impactful structural attacks always lead to increased levels of heterophily. Then, inspired by GNN architectures that target heterophily, we present two designs -- (i) separate aggregators for ego- and neighbor-embeddings, and (ii) a reduced scope of aggregation -- that can significantly improve the robustness of GNNs. Our extensive empirical evaluations show that GNNs featuring merely these two designs can achieve significantly improved robustness compared to the best-performing unvaccinated model with 24.99% gain in average performance under targeted attacks, while having smaller computational overhead than existing defense mechanisms. Furthermore, these designs can be readily combined with explicit defense mechanisms to yield state-of-the-art robustness with up to 18.33% increase in performance under attacks compared to the best-performing vaccinated model.
Graph Neural Networks with Heterophily
Sep 28, 2020Graph Neural Networks (GNNs) have proven to be useful for many different practical applications. However, most existing GNN models have an implicit assumption of homophily among the nodes connected in the graph, and therefore have largely overlooked the important setting of heterophily. In this work, we propose a novel framework called CPGNN that generalizes GNNs for graphs with either homophily or heterophily. The proposed framework incorporates an interpretable compatibility matrix for modeling the heterophily or homophily level in the graph, which can be learned in an end-to-end fashion, enabling it to go beyond the assumption of strong homophily. Theoretically, we show that replacing the compatibility matrix in our framework with the identity (which represents pure homophily) reduces to GCN. Our extensive experiments demonstrate the effectiveness of our approach in more realistic and challenging experimental settings with significantly less training data compared to previous works: CPGNN variants achieve state-of-the-art results in heterophily settings with or without contextual node features, while maintaining comparable performance in homophily settings.
Generalizing Graph Neural Networks Beyond Homophily
Jun 20, 2020
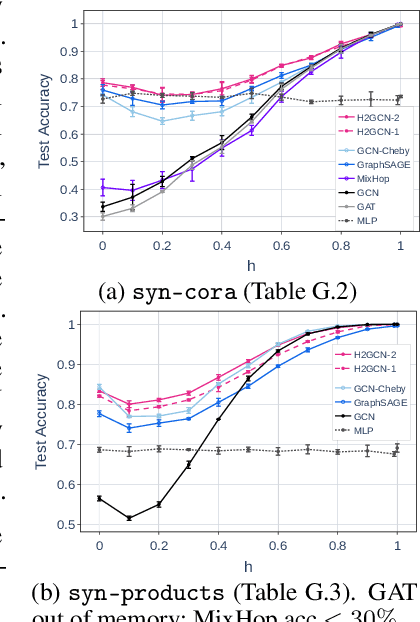

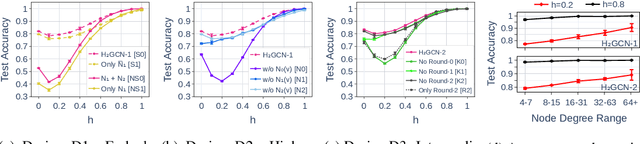
We investigate the representation power of graph neural networks in the semi-supervised node classification task under heterophily or low homophily, i.e., in networks where connected nodes may have different class labels and dissimilar features. Most existing GNNs fail to generalize to this setting, and are even outperformed by models that ignore the graph structure (e.g., multilayer perceptrons). Motivated by this limitation, we identify a set of key designs -- ego- and neighbor-embedding separation, higher-order neighborhoods, and combination of intermediate representations -- that boost learning from the graph structure under heterophily, and combine them into a new graph convolutional neural network, H2GCN. Going beyond the traditional benchmarks with strong homophily, our empirical analysis on synthetic and real networks shows that, thanks to the identified designs, H2GCN has consistently strong performance across the full spectrum of low-to-high homophily, unlike competitive prior models without them.