 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of Factify5WQA: Fact Verification through 5W Question-Answering
Oct 05, 2024



Researchers have found that fake news spreads much times faster than real news. This is a major problem, especially in today's world where social media is the key source of news for many among the younger population. Fact verification, thus, becomes an important task and many media sites contribute to the cause. Manual fact verification is a tedious task, given the volume of fake news online. The Factify5WQA shared task aims to increase research towards automated fake news detection by providing a dataset with an aspect-based question answering based fact verification method. Each claim and its supporting document is associated with 5W questions that help compare the two information sources. The objective performance measure in the task is done by comparing answers using BLEU score to measure the accuracy of the answers, followed by an accuracy measure of the classification. The task had submissions using custom training setup and pre-trained language-models among others. The best performing team posted an accuracy of 69.56%, which is a near 35% improvement over the baseline.
Graph Coarsening via Convolution Matching for Scalable Graph Neural Network Training
Dec 24, 2023



Graph summarization as a preprocessing step is an effective and complementary technique for scalable graph neural network (GNN) training. In this work, we propose the Coarsening Via Convolution Matching (CONVMATCH) algorithm and a highly scalable variant, A-CONVMATCH, for creating summarized graphs that preserve the output of graph convolution. We evaluate CONVMATCH on six real-world link prediction and node classification graph datasets, and show it is efficient and preserves prediction performance while significantly reducing the graph size. Notably, CONVMATCH achieves up to 95% of the prediction performance of GNNs on node classification while trained on graphs summarized down to 1% the size of the original graph. Furthermore, on link prediction tasks, CONVMATCH consistently outperforms all baselines, achieving up to a 2x improvement.
Overview of Memotion 3: Sentiment and Emotion Analysis of Codemixed Hinglish Memes
Sep 12, 2023
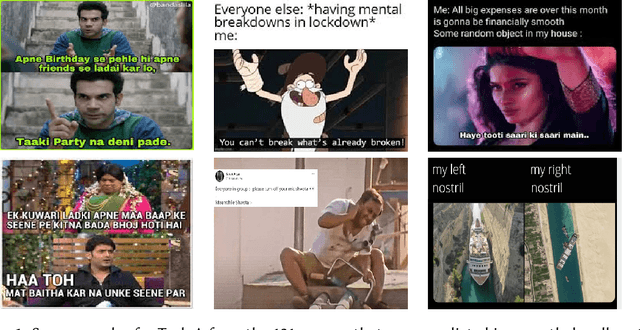
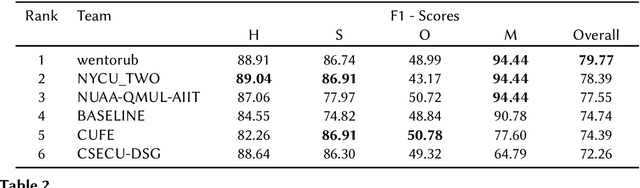

Analyzing memes on the internet has emerged as a crucial endeavor due to the impact this multi-modal form of content wields in shaping online discourse. Memes have become a powerful tool for expressing emotions and sentiments, possibly even spreading hate and misinformation, through humor and sarcasm. In this paper, we present the overview of the Memotion 3 shared task, as part of the DeFactify 2 workshop at AAAI-23. The task released an annotated dataset of Hindi-English code-mixed memes based on their Sentiment (Task A), Emotion (Task B), and Emotion intensity (Task C). Each of these is defined as an individual task and the participants are ranked separately for each task. Over 50 teams registered for the shared task and 5 made final submissions to the test set of the Memotion 3 dataset. CLIP, BERT modifications, ViT etc. were the most popular models among the participants along with approaches such as Student-Teacher model, Fusion, and Ensembling. The best final F1 score for Task A is 34.41, Task B is 79.77 and Task C is 59.82.
Findings of Factify 2: Multimodal Fake News Detection
Jul 19, 2023With social media usage growing exponentially in the past few years, fake news has also become extremely prevalent. The detrimental impact of fake news emphasizes the need for research focused on automating the detection of false information and verifying its accuracy. In this work, we present the outcome of the Factify 2 shared task, which provides a multi-modal fact verification and satire news dataset, as part of the DeFactify 2 workshop at AAAI'23. The data calls for a comparison based approach to the task by pairing social media claims with supporting documents, with both text and image, divided into 5 classes based on multi-modal relations. In the second iteration of this task we had over 60 participants and 9 final test-set submissions. The best performances came from the use of DeBERTa for text and Swinv2 and CLIP for image. The highest F1 score averaged for all five classes was 81.82%.
Simplifying Distributed Neural Network Training on Massive Graphs: Randomized Partitions Improve Model Aggregation
May 17, 2023



Distributed training of GNNs enables learning on massive graphs (e.g., social and e-commerce networks) that exceed the storage and computational capacity of a single machine. To reach performance comparable to centralized training, distributed frameworks focus on maximally recovering cross-instance node dependencies with either communication across instances or periodic fallback to centralized training, which create overhead and limit the framework scalability. In this work, we present a simplified framework for distributed GNN training that does not rely on the aforementioned costly operations, and has improved scalability, convergence speed and performance over the state-of-the-art approaches. Specifically, our framework (1) assembles independent trainers, each of which asynchronously learns a local model on locally-available parts of the training graph, and (2) only conducts periodic (time-based) model aggregation to synchronize the local models. Backed by our theoretical analysis, instead of maximizing the recovery of cross-instance node dependencies -- which has been considered the key behind closing the performance gap between model aggregation and centralized training -- , our framework leverages randomized assignment of nodes or super-nodes (i.e., collections of original nodes) to partition the training graph such that it improves data uniformity and minimizes the discrepancy of gradient and loss function across instances. In our experiments on social and e-commerce networks with up to 1.3 billion edges, our proposed RandomTMA and SuperTMA approaches -- despite using less training data -- achieve state-of-the-art performance and 2.31x speedup compared to the fastest baseline, and show better robustness to trainer failures.
Factify 2: A Multimodal Fake News and Satire News Dataset
Apr 08, 2023



The internet gives the world an open platform to express their views and share their stories. While this is very valuable, it makes fake news one of our society's most pressing problems. Manual fact checking process is time consuming, which makes it challenging to disprove misleading assertions before they cause significant harm. This is he driving interest in automatic fact or claim verification. Some of the existing datasets aim to support development of automating fact-checking techniques, however, most of them are text based. Multi-modal fact verification has received relatively scant attention. In this paper, we provide a multi-modal fact-checking dataset called FACTIFY 2, improving Factify 1 by using new data sources and adding satire articles. Factify 2 has 50,000 new data instances. Similar to FACTIFY 1.0, we have three broad categories - support, no-evidence, and refute, with sub-categories based on the entailment of visual and textual data. We also provide a BERT and Vison Transformer based baseline, which acheives 65% F1 score in the test set. The baseline codes and the dataset will be made available at https://github.com/surya1701/Factify-2.0.
Memotion 3: Dataset on Sentiment and Emotion Analysis of Codemixed Hindi-English Memes
Mar 23, 2023



Memes are the new-age conveyance mechanism for humor on social media sites. Memes often include an image and some text. Memes can be used to promote disinformation or hatred, thus it is crucial to investigate in details. We introduce Memotion 3, a new dataset with 10,000 annotated memes. Unlike other prevalent datasets in the domain, including prior iterations of Memotion, Memotion 3 introduces Hindi-English Codemixed memes while prior works in the area were limited to only the English memes. We describe the Memotion task, the data collection and the dataset creation methodologies. We also provide a baseline for the task. The baseline code and dataset will be made available at https://github.com/Shreyashm16/Memotion-3.0
A Thousand Words Are Worth More Than a Picture: Natural Language-Centric Outside-Knowledge Visual Question Answering
Jan 14, 2022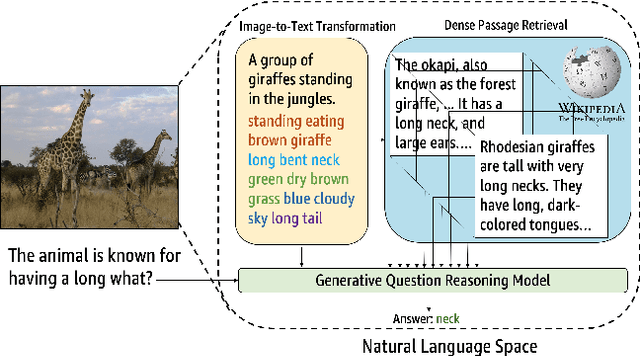
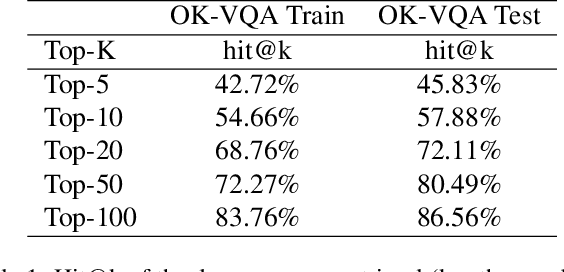

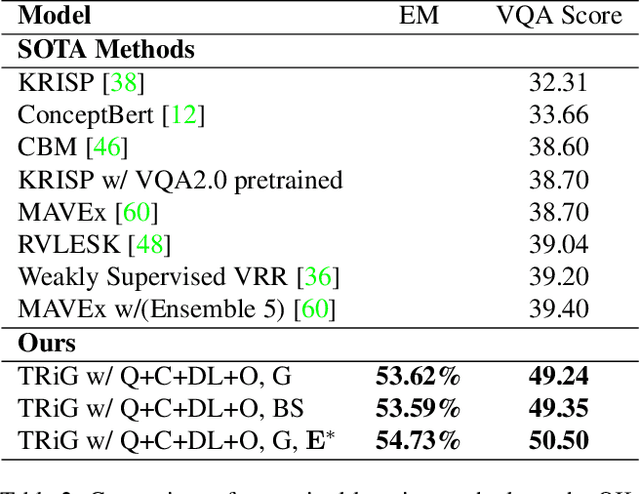
Outside-knowledge visual question answering (OK-VQA) requires the agent to comprehend the image, make use of relevant knowledge from the entire web, and digest all the information to answer the question. Most previous works address the problem by first fusing the image and question in the multi-modal space, which is inflexible for further fusion with a vast amount of external knowledge. In this paper, we call for a paradigm shift for the OK-VQA task, which transforms the image into plain text, so that we can enable knowledge passage retrieval, and generative question-answering in the natural language space. This paradigm takes advantage of the sheer volume of gigantic knowledge bases and the richness of pre-trained language models. A Transform-Retrieve-Generate framework (TRiG) framework is proposed, which can be plug-and-played with alternative image-to-text models and textual knowledge bases. Experimental results show that our TRiG framework outperforms all state-of-the-art supervised methods by at least 11.1% absolute margin.
Best of Both Worlds: A Hybrid Approach for Multi-Hop Explanation with Declarative Facts
Dec 17, 2021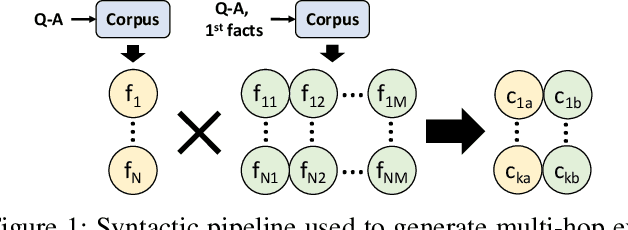
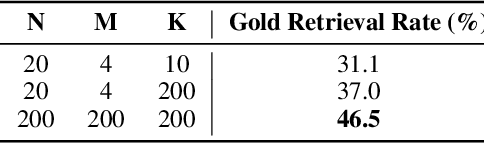
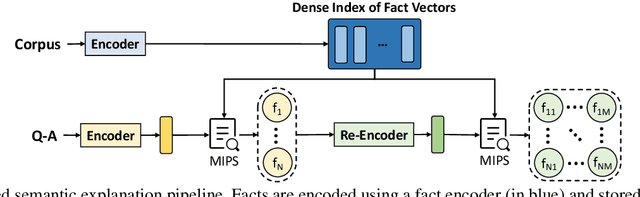
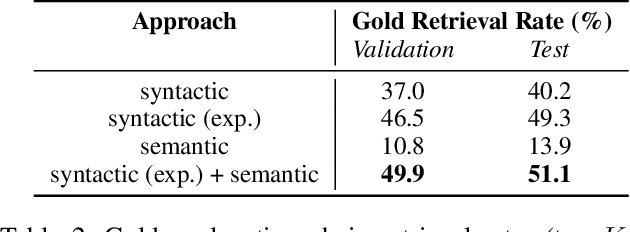
Language-enabled AI systems can answer complex, multi-hop questions to high accuracy, but supporting answers with evidence is a more challenging task which is important for the transparency and trustworthiness to users. Prior work in this area typically makes a trade-off between efficiency and accuracy; state-of-the-art deep neural network systems are too cumbersome to be useful in large-scale applications, while the fastest systems lack reliability. In this work, we integrate fast syntactic methods with powerful semantic methods for multi-hop explanation generation based on declarative facts. Our best system, which learns a lightweight operation to simulate multi-hop reasoning over pieces of evidence and fine-tunes language models to re-rank generated explanation chains, outperforms a purely syntactic baseline from prior work by up to 7% in gold explanation retrieval rate.
Interactive Teaching for Conversational AI
Dec 02, 2020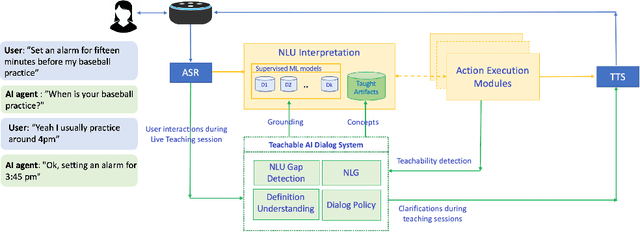
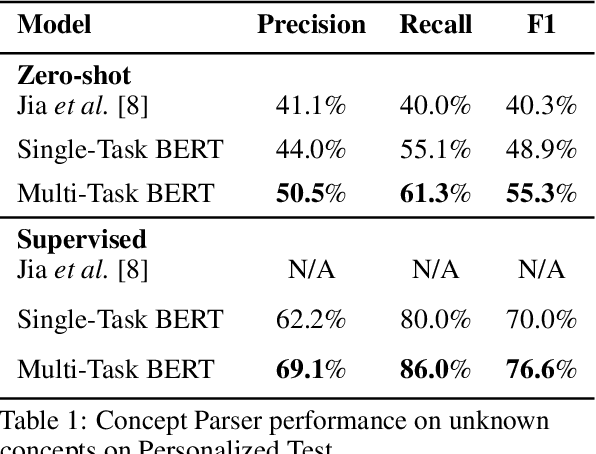
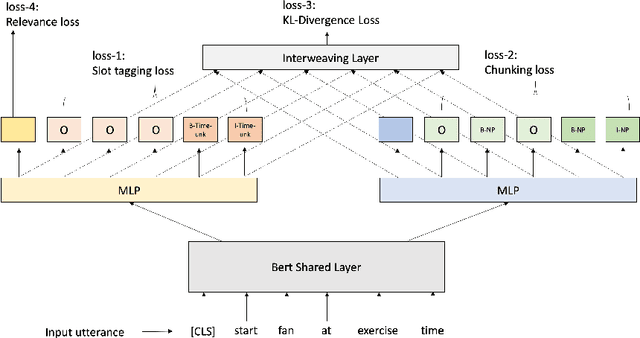
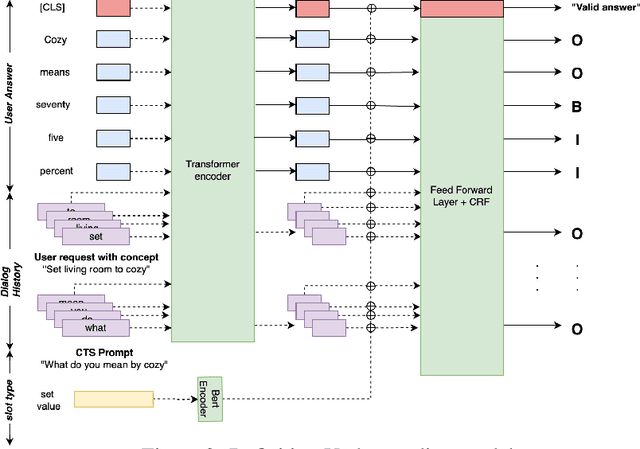
Current conversational AI systems aim to understand a set of pre-designed requests and execute related actions, which limits them to evolve naturally and adapt based on human interactions. Motivated by how children learn their first language interacting with adults, this paper describes a new Teachable AI system that is capable of learning new language nuggets called concepts, directly from end users using live interactive teaching sessions. The proposed setup uses three models to: a) Identify gaps in understanding automatically during live conversational interactions, b) Learn the respective interpretations of such unknown concepts from live interactions with users, and c) Manage a classroom sub-dialogue specifically tailored for interactive teaching sessions. We propose state-of-the-art transformer based neural architectures of models, fine-tuned on top of pre-trained models, and show accuracy improvements on the respective components. We demonstrate that this method is very promising in leading way to build more adaptive and personalized language understanding models.